
CODEX
Python: Stock Data Scraping

Overview
Data is the new asset! In this article, I am going through the fundamental of using Python to scrape data from the Internet for use in your data project.
There are many Python libraries for web scraping. You can use the requests library with either BeautifulSoup, lxml, or Parsel, or frameworks like scrapy, Selenium, or a combination of both for dynamic websites.
Personally, I use requests + lxml for most of my scraping needs, and only use scrapy + Selenium for certain scenarios, e.g. getting content from dynamic or interactive websites. Most of the time using a simple approach should suffice.
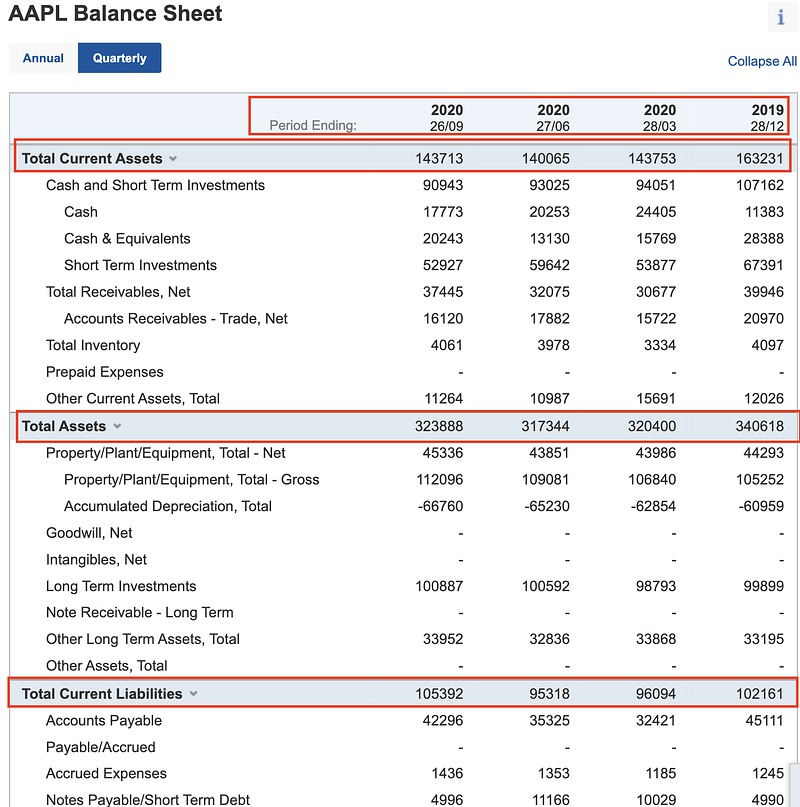
Below I will be using requests + lxml to scrape the stock balance sheet data, highlighted in red boxes as shown below.
XPath vs CSS Selector
There are quite a fair bit of debates regarding XPath and CSS selector, and which one is better to be used for web scraping. This article is not going to compare the two and I will just use XPath for my scraping needs.
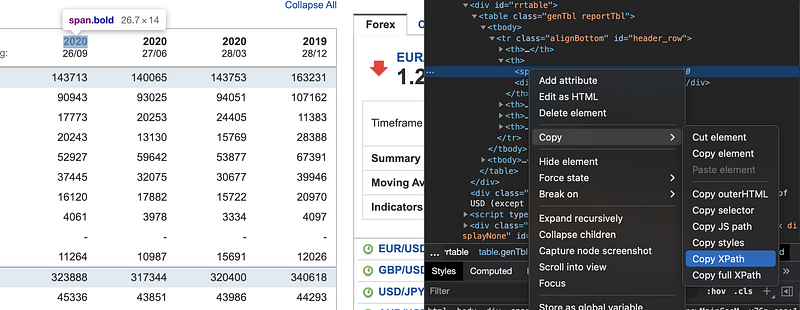
Modern browsers like Brave, Chrome, or Edge allow us to inspect web pages and easily find out the XPath or CSS selector for a particular HTML element.
Below is a screenshot of how I get the XPath for a particular HTML element.
The Code
HTTP User Agent
For the HTTP headers, I am going to generate random user-agent. You can find the list of agents I use from the code snippet here. This is helpful if I am going to make numerous requests on the same website.
def http_headers():
return {
"User-Agent": random_user_agent(),
"X-Requested-With": "XMLHttpRequest",
"Accept": "text/html",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
}def random_user_agent():
return str(random.choice(constant.USER_AGENTS))XPath to the HTML Table
The stock balance sheet data is contained in an HTML table. To make the later selection easier, I assign the HTML table element to a variable.
def get_stock_balance_sheet(url):
req = requests.get(url, headers=http_headers())
if req.status_code != 200:
raise ConnectionError(
"ERR: error " + str(req.status_code) + ", try again later."
)root_ = fromstring(req.text)
path_ = root_.xpath("//*[@id='rrtable']/table")
if path_:
for elements_ in path_:
balance_sheet_dates = _extract_balance_sheet_dates(elements_)
balance_sheet = _extract_balance_sheet(elements_, balance_sheet_dates)
return balance_sheetraise RuntimeError("ERR: data retrieval error while scraping.")Extract Balance Sheet Dates
Using XPath, the scraping is going to be extremely simple. Below are the dates that I want to extract.

Using the below code I can extract them into a Python list -[‘26/09/2020’, ‘27/06/2020’, ‘28/03/2020’, ‘28/12/2019’]
def _extract_balance_sheet_dates(elements):
"""
Extract budget dates to a list. Date format is dd/mm/yyyy.
"""
# Extract years. Use python reg. Can also use lxml exslt
years = list()
nodes = elements.xpath(".//*[@id='header_row']/th/span")
for node in nodes:
match = re.search(r"\d\d\d\d", node.text_content().strip())
if match:
years.append(match.string)# Extract month and day
month_days = list()
nodes = elements.xpath("//*[@id='header_row']/th/div")
for node in nodes:
match = re.search(r"\d\d/\d\d", node.text_content().strip())
if match:
month_days.append(match.string)# Balance sheet timestamps
return ["/".join(map(str, i)) for i in zip(month_days, years)]Extract Balance Sheet Summary
For the balance sheet summary — Total Assets, Total Current Assets, Total Current Liabilities, Total Liabilities and Total Equity, I extract them into a dictionary object using the following code snippets
def _extract_balance_sheet(elements, balance_sheet_dates):
"""
Extract balance sheet info.
"""
nodes = elements.xpath(".//*[@id='parentTr']/td")
balance_sheet = {}
section = ""
dt_index = 0
for node in nodes:
value = node.text_content().strip()
if not is_float(value):
section = value
balance_sheet[section] = {}
dt_index = 0
else:
balance_sheet[section][balance_sheet_dates[dt_index]] = float(value)
dt_index = dt_index + 1
return balance_sheet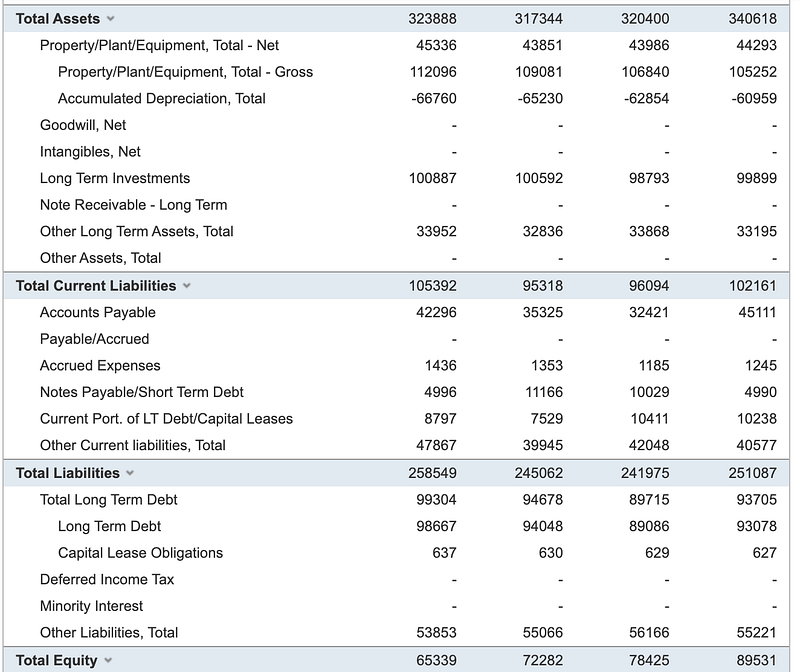
{'Total Current Assets': {'26/09/2020': 143713.0, '27/06/2020': 140065.0, '28/03/2020': 143753.0, '28/12/2019': 163231.0}, 'Total Assets': {'26/09
/2020': 323888.0, '27/06/2020': 317344.0, '28/03/2020': 320400.0, '28/12/2019': 340618.0}, 'Total Current Liabilities': {'26/09/2020': 105392.0, '
27/06/2020': 95318.0, '28/03/2020': 96094.0, '28/12/2019': 102161.0}, 'Total Liabilities': {'26/09/2020': 258549.0, '27/06/2020': 245062.0, '28/03
/2020': 241975.0, '28/12/2019': 251087.0}, 'Total Equity': {'26/09/2020': 65339.0, '27/06/2020': 72282.0, '28/03/2020': 78425.0, '28/12/2019': 895
31.0}}Testing
And here is the unit test case for the above code snippet. You can find the code from this repository.
import unittest
import investplusclass TestClass(unittest.TestCase):"""Test case docstring."""def setUp(self):
passdef tearDown(self):
passdef test_stocks(self):
url = "https://www.investing.com/equities/apple-computer-inc-balance-sheet"
balance_sheet = investplus.get_stock_balance_sheet(url)
assert balance_sheet is not None
print(balance_sheet)Summary
As you can see it is very easy to scrape data using Python without using any complex framework. However, the above method will not work if the website is dynamic and requires interaction to generate the data that we want. In this case frameworks like Selenium will be needed.
Do also check out the following articles.