
CODEX
Python — Categorical Data with Pandas

Overview
Numerical, categorical, time series, text, and geolocation data are the common data types that data scientists or analysts deal with daily. I talked about time series data with Pandas previously. In this article let’s go through categorical data.
The Basic
Normally a categorical variable takes on a limited, and usually fixed, number of possible values, with or without an order.
Represent Categories by Numeric
Let’s create a Pandas series with a range of different colors.
import pandas as pdcolors = pd.Series(['green', 'yellow', 'black','blue', 'green', 'red', 'yellow'])
print(colors)
pd.unique(colors)As you can see, the default data type is the object.
0 green
1 yellow
2 black
3 blue
4 green
5 red
6 yellow
array(['green', 'yellow', 'black', 'blue', 'red'], dtype=object)For efficiency and better performance, normally in analytics, we represent the values are integers.
# black = 0, blue = 1, green = 2, red = 3, yellow = 4
values = pd.Series([0,0,4,3, 2,1,1, 0, 4] * 2)
colors = pd.Series(['black', 'blue', 'green', 'red', 'yellow'])
colors.take(values)Represent colors using numbers.
0 black
0 black
4 yellow
3 red
2 green
1 blue
1 blue
0 black
4 yellow
0 black
0 black
4 yellow
3 red
2 green
1 blue
1 blue
0 black
4 yellow
dtype: objectCategorical Data Type
In Pandas, the categorical data type is provided.
Let’s take the following sales data as an example.
sales_data = pd.read_csv("test_data/datasets/sales.csv")
sales_data.head(10)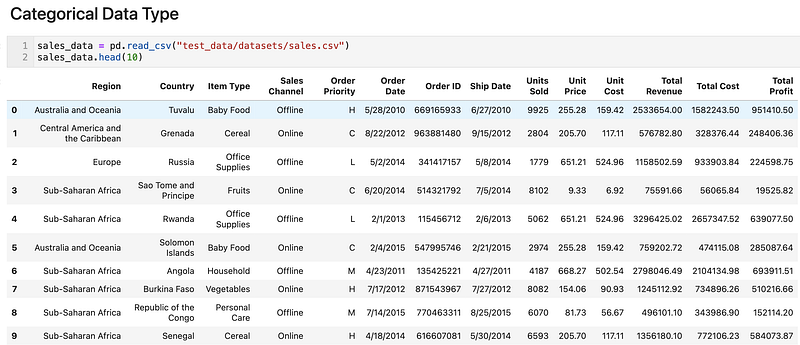
Region, Country, Item Type, Sales Channel, Order Priority are all categories, and for Order Priority, the order matters. A bigger number probably indicates a higher priority.
Currently, these categories are presented as objects by default.
sales_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Region 100 non-null object
1 Country 100 non-null object
2 Item Type 100 non-null object
3 Sales Channel 100 non-null object
4 Order Priority 100 non-null object
5 Order Date 100 non-null object
6 Order ID 100 non-null int64
7 Ship Date 100 non-null object
8 Units Sold 100 non-null int64
9 Unit Price 100 non-null float64
10 Unit Cost 100 non-null float64
11 Total Revenue 100 non-null float64
12 Total Cost 100 non-null float64
13 Total Profit 100 non-null float64
dtypes: float64(5), int64(2), object(7)
memory usage: 11.1+ KBAnd there is no descriptive statistics provided for the object data type.
sales_data.describe()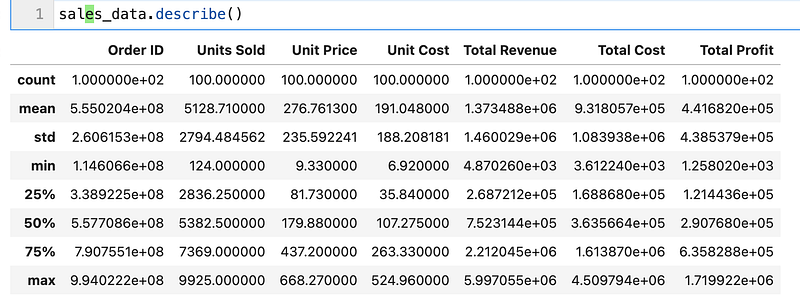
Let’s convert the categories to categorical data types.
sales_data_cats = sales_data[["Region", "Country", "Item Type", "Sales Channel", "Order Priority"]].astype("category")
sales_data_cats.info()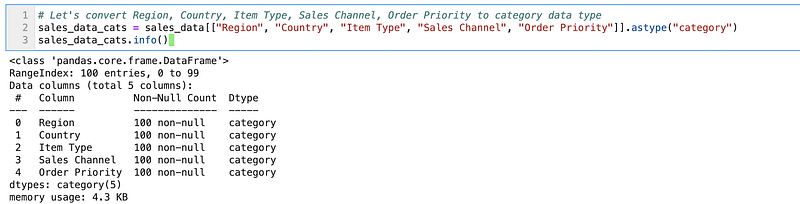
You can see the data type is changed to category now.
Descriptive statistics are generated now. Internally the categories are now represented using the codes and categories attributes.
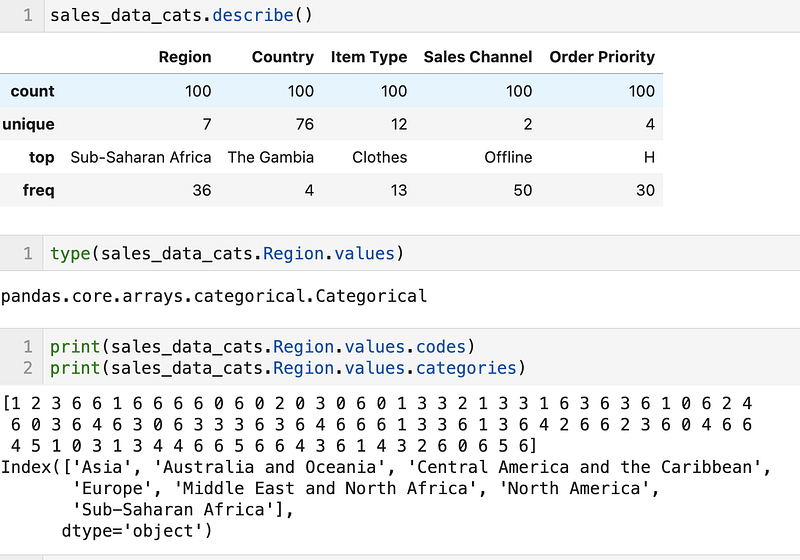
Categorical Data Type Order
Order Priority are Low, Medium, High and Critical but currently, the representation has no particular order.
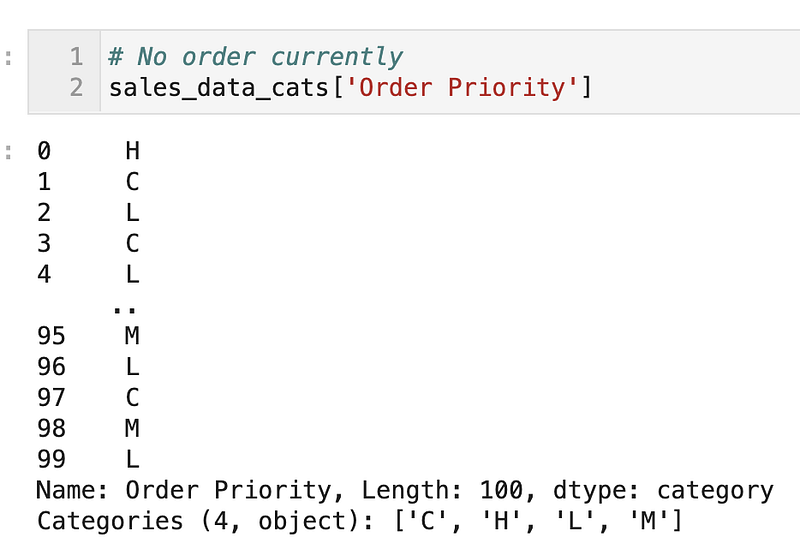
Let’s make sure they have a proper order (L < M < H < C)
sales_data_cats['Order Priority'] = sales_data_cats['Order Priority'].cat.reorder_categories(['L', 'M', 'H', 'C'], ordered=True)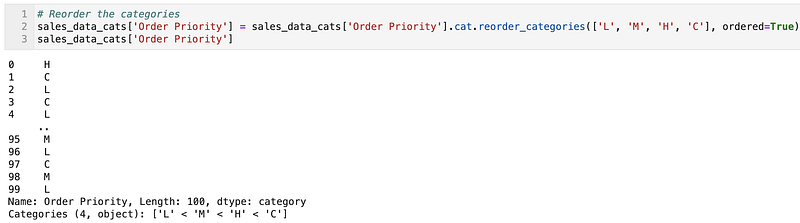
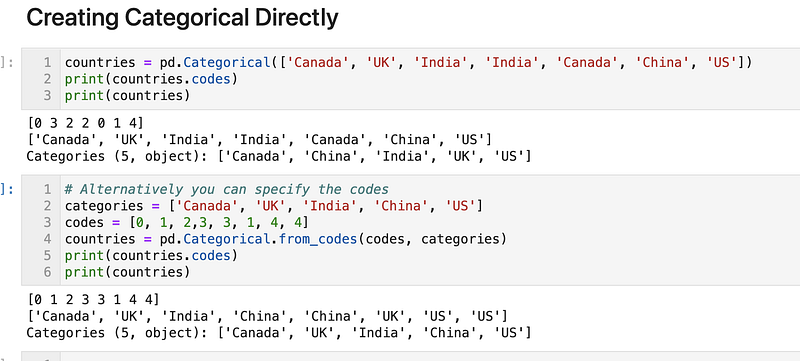
Creating Pandas Categorical Directly
Also, you can create a Pandas categorical type directly.
Categorical Methods
Let’s continue to use the sales data for demonstration purposes.
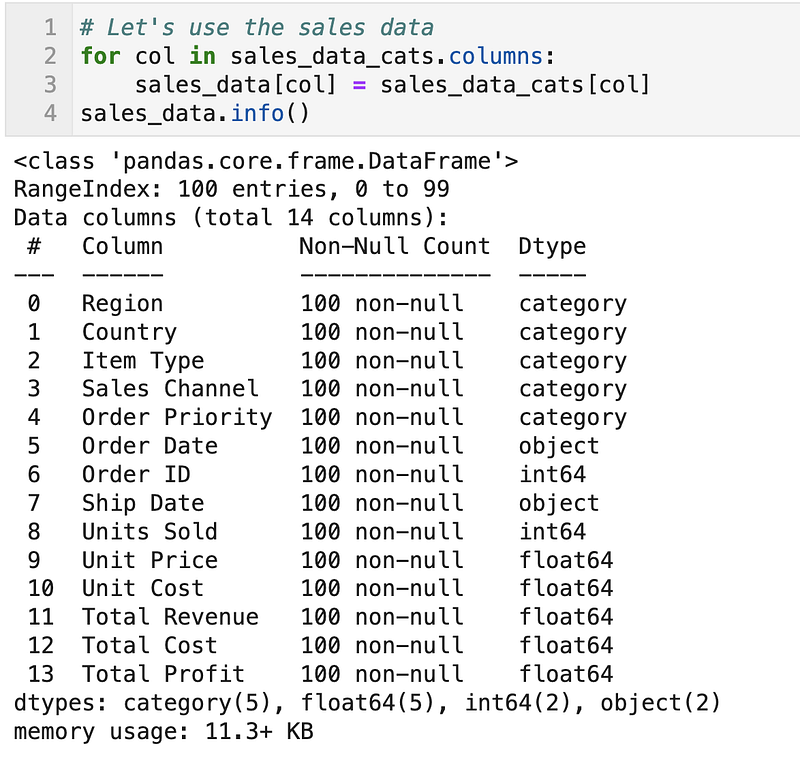
The categorical accessor can be accessed through the catattribute.
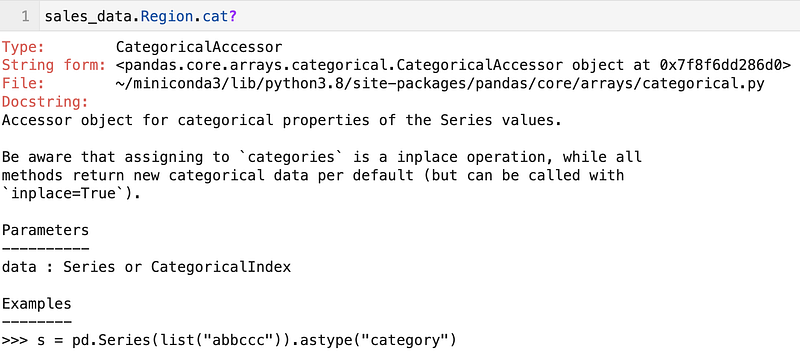
Here are some of the operations.
rename_categories
reorder_categories
add_categories
remove_categories
remove_unused_categories
set_categories
as_ordered
as_unorderedTo get the represented categories and codes.
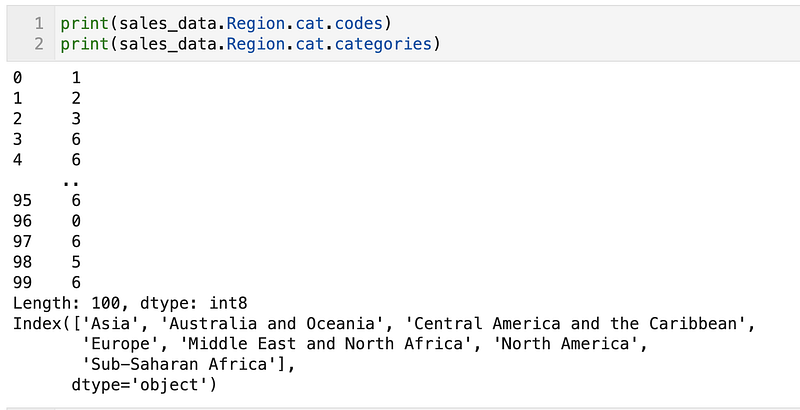
You can add new categories, reorder or rename them or even remove unused categories. I used the reorder_categories previously to reorder the Order Priority More details available in the Pandas user guide.
Categorical Encodings
Using Pandas
We can use the pd.get_dummies to perform one-hot encoding. E.g. for Order Priority
pd.get_dummies(sales_data['Order Priority'])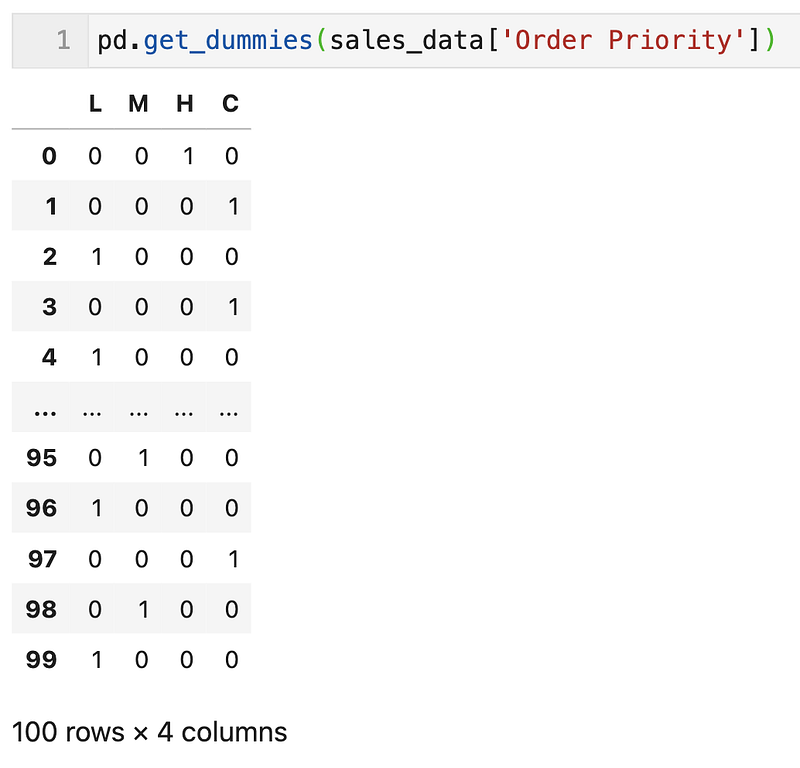
scikit-learn
In scikit-learn, we can use OrdinalEncoder, OneHotEncoder, LabelEncoder , LabelBinarizer and MultiLabelBinarizer to encode categorical data.
OrdinalEncoder
ordinal_encoder = OrdinalEncoder()sales_data['ordinal_encoded']= one_hot_encoder.fit_transform(sales_data[['Order Priority']])
sales_data[['Order Priority', 'ordinal_encoded']].head(10)
OneHotEncoder
one_hot_encoder = OneHotEncoder()encoded = one_hot_encoder.fit_transform(sales_data[['Order Priority']])
pd.DataFrame(encoded.toarray(), columns=one_hot_encoder.categories_).head(10)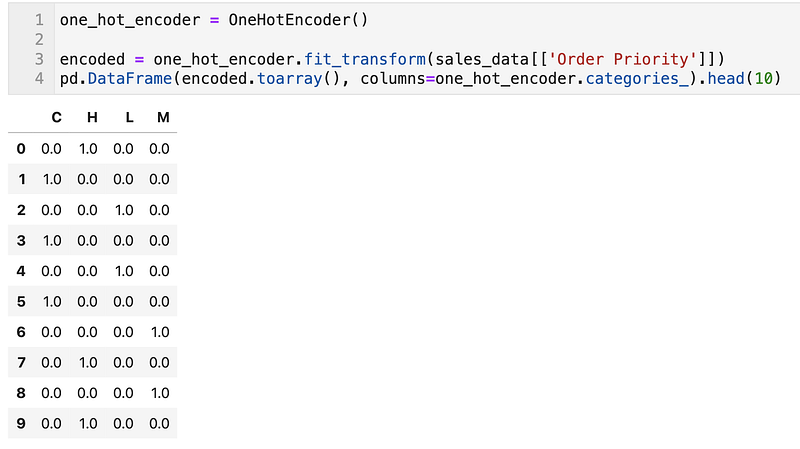
LabelEncoder
This is normally used to encode target values.
label_encoder = LabelEncoder()sales_data['label_encoded']= label_encoder.fit_transform(sales_data[['Order Priority']])
sales_data[['Order Priority', 'label_encoded']].head(10)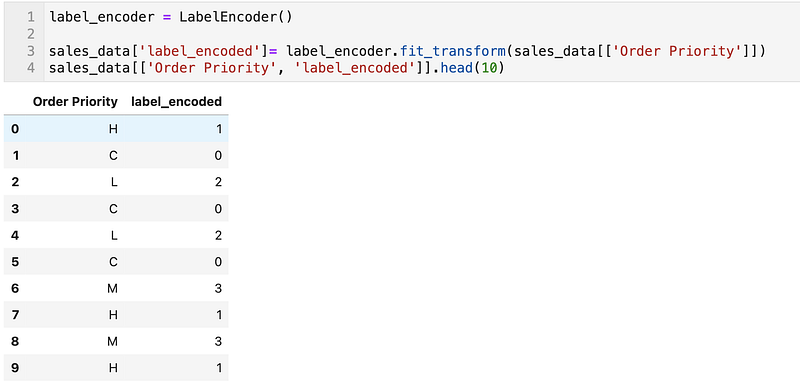
LabelBinarizer
This is normally used to encode target values.
label_binarizer = LabelBinarizer()encoded = label_binarizer.fit_transform(sales_data['Order Priority'])
pd.DataFrame(encoded, columns=label_binarizer.classes_).head(10)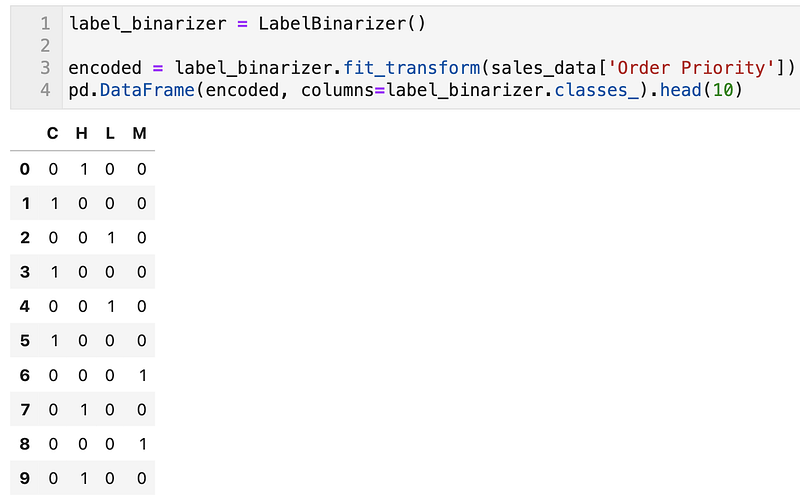
Category Encoders from scikit-learn Contrib
Category Encoders is a set of scikit-learn-style transformers for encoding categorical variables into numeric with different techniques.
To install it using pip.
pip install -Uqq category_encodersThere are many different techniques that you can explore
import category_encoders as ce
encoder = ce.BackwardDifferenceEncoder(cols=[...])
encoder = ce.BaseNEncoder(cols=[...])
encoder = ce.BinaryEncoder(cols=[...])
encoder = ce.CatBoostEncoder(cols=[...])
encoder = ce.CountEncoder(cols=[...])
encoder = ce.GLMMEncoder(cols=[...])
encoder = ce.HashingEncoder(cols=[...])
encoder = ce.HelmertEncoder(cols=[...])
encoder = ce.JamesSteinEncoder(cols=[...])
encoder = ce.LeaveOneOutEncoder(cols=[...])
encoder = ce.MEstimateEncoder(cols=[...])
encoder = ce.OneHotEncoder(cols=[...])
encoder = ce.OrdinalEncoder(cols=[...])
encoder = ce.SumEncoder(cols=[...])
encoder = ce.PolynomialEncoder(cols=[...])
encoder = ce.TargetEncoder(cols=[...])
encoder = ce.WOEEncoder(cols=[...])
encoder.fit(X, y)
X_cleaned = encoder.transform(X_dirty)Efficient Memory Usage
Lastly, using categorical data types are more efficient in terms of memory and performance.
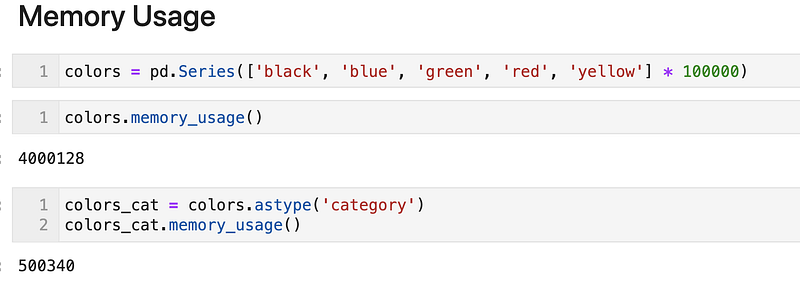
The notebook used for this article can be found here.
Do also check out the following articles.