
Prompt Engineering — Self Consistency Chain Of Thought (CoT — SC)
The article is part of series: Prompt Engineering via Prompt Patterns and is a sequel to earlier article Prompt Engineering — Chain of Thought Prompting
You can switch to video version of this article
So in chain of thought prompting, we forced the LLM to come up with a reasoning for the solution it was providing for our complex question. While this does improves the accuracy and results, anyone who has worked on complex logical problems or tasks knows that there are multiple ways of solving the same problem. You can always find someone who comes up with a better, optimal, more performant way of solving the same problem. Now come to think of it, if you are able to come up with an amazing solution to a question, already answered on the internet, what would you do? And if you are like most normal people, the first instinct would be to show off your solution to the world by posting it as a solution on the internet. Even if you are not a show off, a brilliant solution that lives in your head only is no benefit to the world.
Now who would read your answer? Your friends, colleagues, people interested in the topic, and fingers crossed, a crawler for large language model since internet is their training data and they would love to read anything and everything there is to read.
So now the LLM knows about the question, and knows about multiple ways of solving the question, the previous, lets say ordinary mortal solutions, and your amazing immortal gem you just posted. Now if anyone asks LLM say ChatGPT the question, which answer do you think it would share as response?

Well, chances are, it would be the ordinary, mortal solution. Why? When your brilliant solution is in its knowledge box? Simply because LLM does not know it is brilliant. It is a large language model trying to come up with most plausible next words to emit in response to prompt. It is using patterns of language to figure out which is the best answer among so many more possible ones, and it is trying to do in the most optimal way by using various indicators. And just like google, which uses its page rank algorithm to sort resulting pages based on how many other pages link to that result, LLM would use several techniques like giving higher priority to more quoted responses to similar questions as the one you asked.
I am just giving one example of indicators as LLMs work in mysterious, or lets say complex ways. The point being, an ordinary, mortal solution that has been there for a while has been shared, discussed and admired a lot more than the solution you just posted. Or maybe your social network was limited due to which your solution did not spread as fast as the other solutions. Either way, we can’t say for sure why LLM would pick one answer over the other for sure, but what we CAN say for sure, is that the answer picked by LLM is not guaranteed to be the best one, doesn’t matter how much reasoning accompanies the response.
Even if we set aside the default ranking for known, beaten to death problems on the internet for a minute, LLM would try to come up with a reasoning path for the problem that you prompted it with, and what we termed ‘chain of thought’, the sequence of steps that lead to the final answer, if it gets any one of those steps wrong, the final answer would be wrong, and believe me, this is more frequent than you think. This is specially the case for complex, multi step logical or arithmetic reasoning problems. Again taking example of manual division of a large number to have the simplest ‘reasoning’, having any step wrong in the sequence would lead to problem being magnified by the end. Chain of thought prompting minimizes errors by a big margin for sure, but still leaves a lot to be desired.
So what are your options now? One, you can accept the answer as is and have inner peace with the reasoning for yourself that the algorithm must have chosen the best answer for you. But do you always only click the first result on the google result page? No. You go through a few top options and then choose the best result ‘for you’. With the pattern we are discussing in this article, Self Consistency Chain Of Thought Prompting (CoT-SC) introduced in this great research paper, this is exactly what we are trying to do.
Reiterating that the key concept at play here is that there are multiple ways of approaching the same problem. So it works pretty much like a panel of experts at your disposal where you post a question, and then they come up with their own independent answers, not knowing the answers from other experts. Then we marginalize out the answers to find the most consistent answer in the answer set, kind of like a majority vote. The intuition is similar to human experience such that if multiple different ways of thinking lead to the same answer, one has greater confidence that the answer is correct.
There are multiple ways to use self consistency prompting. One is to simply prompt the model several times with variation in prompt or question nudging it to a different approach to solve the problems, and then comparing the answers and picking the most consistent answer. The other, more creative way, is to use our earlier analogy of multiple experts independently, and differently approaching the problem, into our prompt as a scenario for the model. Impressive what you can do with LLM right? 😊. So, you can add following instructions after your question to accomplish that
Imagine
This is it, you just forced the model to come up with ’n’ novel approaches to solve the problem, and then do the voting and find the most consistent answer. Hats off to those who come up with such beautiful prompting techniques, and I, for myself, can’t stop admiring the versatility of large language models. The most common way of getting stuff done in this world is by use of language, and large language models being, well, language models, can be put to effective use by just creative use of natural language. The future is surely exciting.
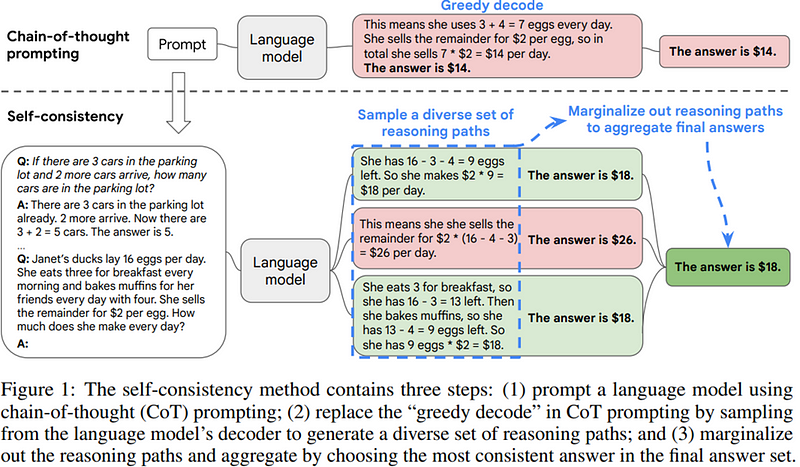
Coming back to self consistency prompting, The approach is really simpler and makes for much more accurate results than other approaches including the chain of thought prompting that it enhances. It is totally unsupervised, works off the shelf with pre trained language models, requires no additional human annotation, and avoids any additional training or fine tuning.
If you recall from previous video on chain of thought prompting where we discussed that chain of thought performance is a function of size of model, and for small sized language models, the performance can actually not improve or even degrade. Well, chain of thought coupled with self consistency improves the performance for those small models as well, so it’s a win overall no matter which model you are using.
The key point of this approach is celebrating diversity of reasoning to approach a problem, and then picking the most consistent answer. LLMs are poor at reasoning so getting a wrong answer even with reasoning is not a matter of if but when. Models can produce incorrect reasoning or make a mistake in one of the reasoning steps, but multiple solutions are unlikely to arrive at the same answer if there is a mistake in one or more of them. Mistakes would make the answer jump all over the place, but correct solutions would converge to the same answer, which, in all probability, is the correct answer.
One should note that self-consistency can be applied only to problems where the final answer is from a fixed answer set, but in principle this approach can be extended to open-text generation problems if a good metric of consistency can be defined between multiple generations, e.g., whether two answers agree or contradict each other.
Next slide
Note the results for arithmetic reasoning and symbolic reasoning. Note the approach is much more performant than regular chain of thought for arithmetic reasoning, and reasonably more performant in symbolic reasoning.
Results
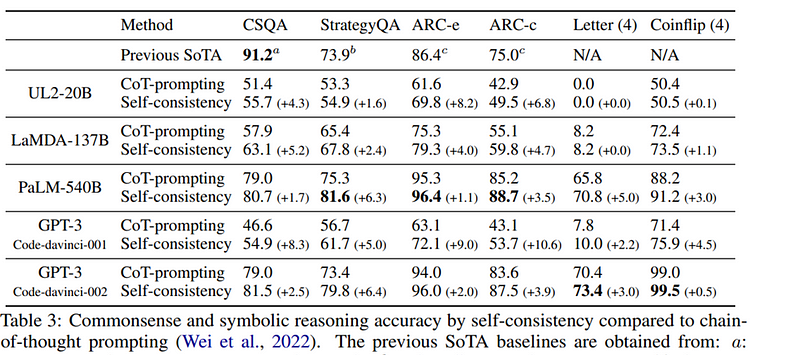
There are several techniques in LLM world to rank the best answer after LLM has been trained, some of which involve humans to provide ranking for common questions, but Cot-SC is one of the simplest methods available to accomplish this. Beyond accuracy gains, self-consistency is also useful for collecting rationales when performing reasoning tasks with language models.
The only downside is it is computationally heavy which does not affect you upfront, but does affect the LLM ecosystem which is providing you LLMs as a service. The more cost they bear, the more services they would move to paid realm. The creators of Cot-SC suggest to limit reasoning paths to 5–10 as it is the optimal range where most performance gain is seen. Any higher number has diminishing returns. My suggestion would be to use the ‘environmentally friendly’ 5–10 number 😊
This concludes our article on CoT-sc. Hope you liked and if you did, please clap/ share. You can consider subscribing to our YouTube channel as well. Thank you!!!.
Next: Prompt Engineering via Prompt Patterns — ReAct Prompting





