
Prompt Engineering — Chain of Thought Prompting
The article is part of series: Prompt Engineering via Prompt Patterns
You can switch to video version of this article
As a kid, all of us have a tendency to provide a knee jerk answer if asked a complicated question, specially if we feel we may have a shot at our answer being the correct one. After all, who wants to go through the trouble of computing all the way, and thinking through the solution if we feel pretty confident in our guess to be the correct answer. Worth a shot right?
Turns out, LLMs are not too different in this behavior. In our ChatGPT Features and Prompt Engineering series, we have multiple times come across the issue that when it comes to mathematical or logic and reasoning kind of questions, LLMs, at least today, suck. They would generate a totally wrong answer confidently, and may even provide a small explanation for that wrong answer too. But that would be totally wrong, just like a child. What kind of behavior is that? LLMs should be sent to detention for doing that repeatedly.
The problem with humans and models alike is that, when it comes to mathematical and logical questions, not taking shortcuts via guesswork is often costly. The first instinct of humans and models would be to save brain and processor usage and try to guess an answer specially if it ‘feels’ correct. But many a times, just like you may have experienced, the teachers would not give you a good score if you just write the answers and don’t write the steps or reasoning for coming up with that answer. Even as adults, during interviews, trick questions are used to see the approach of a candidate. Leetcode is filled with such problems where guesswork and jumping to conclusion simply destroys you. One of my favorites used to be to tell the angle between two hands of an analog clock at 3:15. Most people will instinctively start by saying zero. When forced to come up with the steps or reasoning, your accuracy improved dramatically (I hope). Turns out, and very counter intuitively, the same is true for most large language models.
If you come to think of it, it makes sense. LLMs are predictive models. They are just trying to come up with the most plausible response to your prompt. If their training included a question similar in nature to the one you are asking, they might try answering with its answer first. Don’t expect an LLM to be trying hard to come up with the most accurate response to your query, it would try the most plausible answer. But being aware of this limitation of LLM gives you certain prompt engineering techniques to illicit a better quality output. Some were covered in our prompt patterns series. Yet probably the best of such type of questions is ‘chain of thought prompting’.

Content of this article is very much inspired by an amazing paper from Google research brain team comprising of Jason Wei and colleagues. I have provided link to the actual paper below and would highly encourage you to read it since we are ‘obviously’ not going to go in full detail. The article is trying to simplify the detailed information in that paper. One important lesson from the paper is that this technique is subjective w.r.t the size of the model in question. The larger the model, the more effective this technique is, but still, the technique works in most cases and shows marked improvement in large models. There are tons of example prompts and their outputs for various LLMs given near the end of the paper which you can use to improve your skills of this technique. That is it about the paper, let’s continue with chain of thought prompting.
Research paper: https://arxiv.org/pdf/2201.11903.pdf Chain-of-Thought Prompting Elicits Reasoning in Large Language Models from Google research brain team Jason Wei and colleagues.
So the main idea of that technique is that forcing LLM to demonstrate that its output is based on reasoning forces it to process your question more and in doing so, refining the answer. It also makes it breaks down the problem into coherent intermediate constituent steps in most cases, specially where it is required. Note it is a complete reversal of few shots where we provide examples of solving problem with intermediate steps and model follows, while here we are asking it to come up with or generate intermediate steps. As we discussed earlier, the model would always tries to reduce processing where it can, and chain of thought prompting forces it to process your answer more than it would do by default. Right reasoning leads to right answer, and getting step 1 correct leads to better chances of step 2 being correct and so on.
Easiest way to visualize it is dividing a large number by a smaller one manually. It needs to be done step wise and all steps are important to get the right answer. Its just a basic example as we are talking complex logic and reasoning based questions here in context of this prompt engineering technique 😊 Experiments on multiple large language models show that chain of thought prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks. It is applicable to any task that humans can solve via language. The empirical gains can be striking.
Can we consider Chain of thought prompting to be forcing model to overthink? Well in some situations, yes, it might have responded correctly without CoT. But what about the situations where it should have and didn’t? And how do you know if it did ‘think’ or ‘reason’ when it should have? There is no visible red line, and hence for any complex questions, and without CoT, someone has to do the hard work of fact checking the answer, so its either you or the model doing the thinking. If you are happy to do so, you can get the model off the hook. Otherwise, CoT is your friend 😊
Another important aspect is that chain of thought prompting provides an interpretable window into the behavior of the model, suggesting how it might have arrived at a particular answer and providing opportunities to debug where the reasoning path went wrong (although fully characterizing a model’s computations that support an answer remains an open question). You can identify and change the prompt/question, or add further details to reduce chances of confusion and nudging the model to the right answer. At least you have a shot.
The technique can be effectively combined with few shots prompting technique which we covered in earlier article in the series, where you give it a few examples and provide detailed reasoning in the answers. The examples, coupled with explicit instructions to rationalize the output makes for a detailed and hopefully more accurate answer. Just few shots prompting with question and answer would result in more erroneous answers than when our examples involve a reasoning section where we provide a reasoning for our answers. The answer might actually change, and hopefully for the better 😊
Lets go over some examples now starting off with wrong examples. I have listed one of multiple categories of errors so apologies for the small print. For sake of time I won’t go through all the examples but you can pause and take a look, or better still find examples in the paper link below to see more examples with full details of errors and incorrect vs correct reasoning.
Most errors LLMs make with these kind of questions can be broadly categorized in three categories. These are calculator error, semantic understanding error, and one step missing error. Calculator errors are simple errors arising out of incorrect calculation. You can see the first example where a very simple multiplication has an error where instead of 600 it calculated 300. The study showed 8% of chain of thought prompts were correct except for this type of error. The other category is semantic understanding or symbol mapping kind of errors where model makes an understanding or mapping error, and lastly is one step missing error where the steps required for a correct solution have some missing step. This is the biggest contributor to errors with 22% in the study compared to 8% of calculator and 16% in symbol mapping errors.
Right example
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11. Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
A: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23–20 = 3. They bought 6 more apples, so they have 3 + 6 = 9. The answer is 9.
Why did that happen? Consider one’s own thought process when solving a complicated reasoning task such as a multi-step math word problem. It is typical to decompose the problem into intermediate steps and solve each before giving the final answer. Forcing the model to generate a similar chain of thought makes it dive more deeply as it has to come up with reasoning for each step.
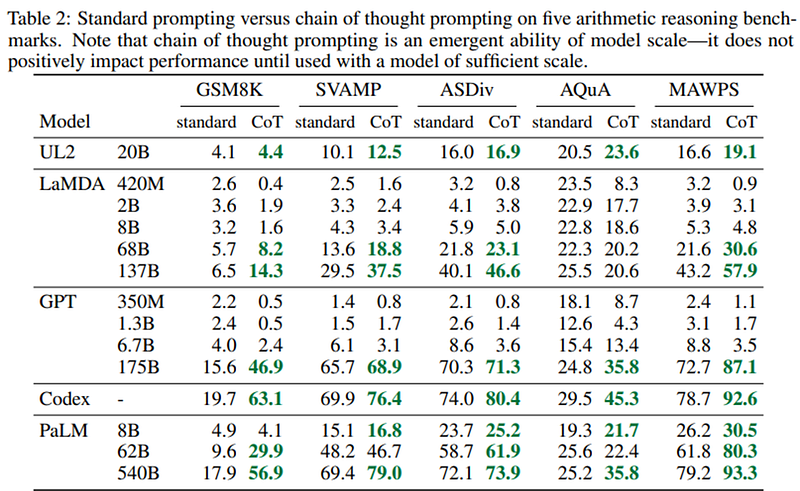
Note again that chain of thought prompting does not give best results on smaller large language models, and works best with models of 100B parameters and more. Though smaller models do generate chain of thought fluently, but it might be illogical leading to wrong, inaccurate answers.
In short the two main conclusions from the study are that while the technique is applicable to any text to text task, it works best for tasks that are challenging and requires multi-step reasoning and a large, large language model is used. For problems requiring single or two steps only, the performance of even smaller models are pretty good and using this technique is an overkill achieving little additional benefit
Picking just one example from the paper
Question: Tracy used a piece of wire 4 feet long to support tomato plants in the garden. The wire was cut into pieces 6 inches long. How many pieces did she obtain?
Answer by Model with 62B parameters
She cut the wire into 6 inch pieces. This means she got 4 * 6 = 24 pieces. The answer is 24. (Incorrect: semantic understanding error)
Answer by model with 520B parameters
The wire was 4 feet long. This means it was 4 * 12 = 48 inches long. It was cut into pieces 6 inches long. This means she obtained 48 / 6 = 8 pieces. The answer is 8. (Correct)
Many other examples in the paper
Showing you a result slide from the study where various large language models and their size variants were subjected to benchmark tests. Take home being that it better be used with larger variants of large language models for problems requiring more than two intermediate steps.
Read end of paper for host of examples of chain of thought prompting.
This is it for the chain of thought prompt engineering technique. If you liked, please clap and share. You can consider subscribing to our YouTube channel as well. Thank you!!!.
Next article: Prompt Engineering — Self Consistency Chain Of Thought Prompting (CoT — SC)



