
Prefect — Orchestrate Your Machine Learning Workflow
In this article, we will dive into the relevance of Workflow Orchestration and a great tool that enables this process, Prefect.

My last article was about MLflow and experiment tracking which is the idea of keeping the most information possible about all the training models built from the data used, the metrics, parameters, results… As I explained, this process is apart of MLOps which corresponds to all the practices needed and applied to bring a model into production and maintain it. However, experiment tracking is just a part of Machine Learning Pipelines.
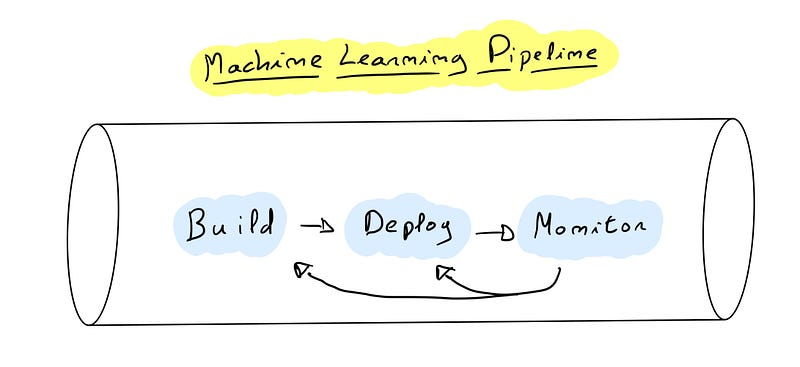
A Machine Learning Pipeline is a combination of several related steps that allow the ML Lifecycle to run smoothly. These pipelines are composed of 3 major steps that follow each other :
- The first one is the Building step which consists of getting the data (data ingestion), training a model (data preprocessing, feature engineering, scaling, hyperparameter tuning), testing the model (evaluation) and versioning it (model packaging and registering).
- Once the model ready, the next step of the pipeline is Deployment. As its name suggests this stage is about getting the model into production. Before that, a phase of production testing is done to prevent any issue when the production release happens.
- Finally, the last step of the pipeline is the Monitoring. At this step, the model is doing its job (making predictions for example) and the purpose of monitoring is to examine its performance. Analyze with defined metrics and alert when something goes wrong. A well known issue is Model Drift/Data Drift which represents a situation where the model predicts a target that is not the correct one due to changes in the data itself. Thus,the accuracy vanished and the model must be trained with the new data to stay relevant.
As we know what a ML Pipeline is, let’s talk about the subject of this article : Workflow Orchestration.
Before seeing what does orchestration mean, a Workflow is basically the flow of the pipeline, from the building step to the monitoring one. It is possible to represent this flow by arrows from one stage to another. The pipeline is endless, as long as the product works, each step is linked within an infinite flow and it is therefore necessary to have control over it…
This is where workflow orchestration comes in, allowing it to be managed like a conductor manages his musicians. The main idea is to locate any failure in the pipeline during the workflow and reduce the consequences of those. An important concept exists in the development field and not only in Data Science, Negative Engineering.
Negative Engineering is defensive code written by developers, engineers so that the positive code (the one that is actually written for a specific purpose) works without issues. The main problem is that it takes up all the time of the person doing it (90% of the engineers’ time is spent on negative/defensive issues versus 10% on positive solutions.). Therefore, instead of waiting that a failure in the program happens, try to locate it and then fix it, Workflow Orchestration Frameworks provides the means to contain problems and prevent all surrounding codes and services from being affected.
Now let’s look at these frameworks…
Some example type of Machine Learning Workflow Orchestration Tools
As the subject is on Machine Learning here is 3 python based libraries/frameworks/platforms :
- Apache Airflow : the pioneer of workflow orchestration tool.
- Prefect : a newcomer since 2018 that builds on its idea of fighting negative engineering.
- Dagster : a recent platform that is very popular because of its elegance, simplicity and efficiency.
Presentation of Prefect
Prefect is a modern Open Source python-based data stack used to build workflows as blocks. It works with decorators in a python script that defines the workflow and its element. Each step of the workflows is called a task but it can also take no task at all.
The 2 main attributes of Prefect Blocks are Tasks and Flows:
- Tasks are as I said, each step that defines the flow. It is declared with a @task decorator to any type of function. Moreover, task functions can have inputs or outputs, parameter that specify if the task has to retry and more.
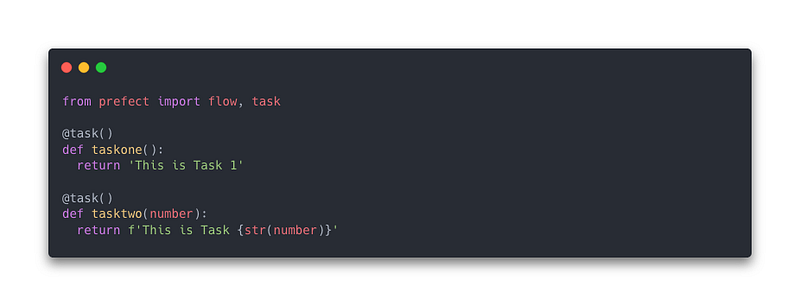
- Flows are containers (as the doc explains) because it wraps all the tasks and dependencies between them. It is used with the @flow decorator to a python function in which you can organize the tasks as you want and prefect will create links between them. It is possible to specify some parameters like the task_runner which is one that defines how the flow has to run (Concurrently or Sequentially for example). Prefect flows object automatically logs a lot of information about flow runs. You can have flows in another flow, that we call subflows.
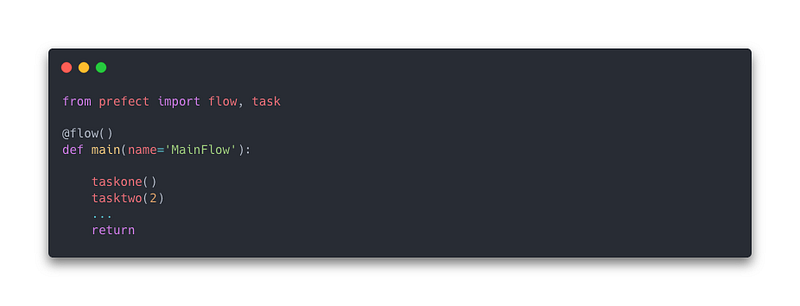
Having a flow to run can be done either manually by calling the script of the flow or by deploying it. Deployment is an important concept in Prefect. You can deploy a flow either in the Prefect Cloud (at a cost) or either locally (remotely on a VM also) within a Prefect Orion Server that we will now introduce.
Prefect has an UI called Core or Orion (depending on the version) that makes possible the visualization of the flows with edges between tasks and the launch of flows directly with the API (from anywhere as long as an agent is available and the server up).
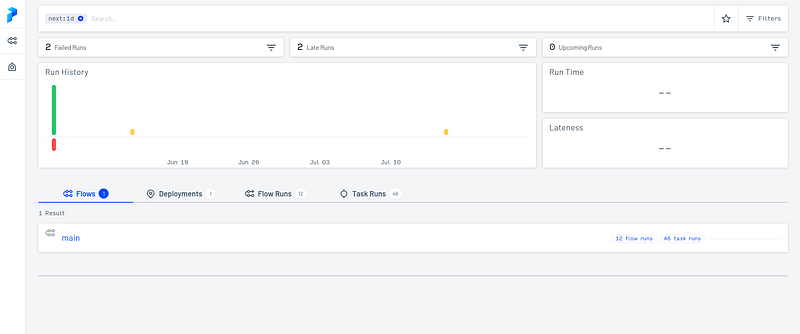
Once the UI is ready, you can access it at http://127.0.0.1:4200 and find any flow, deployments, and runs. It is possible to filter by tags, date and more. If you want to know better about a flow run, you can have more information by selecting the one that you want. This is an example of the Radar View of a flow run :
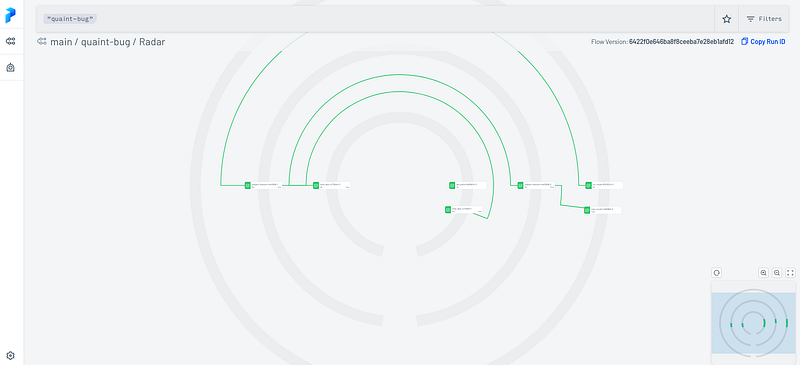
It shows how the tasks were performed and the dependencies between each other.
Let’s talk a little bit about Deployment and Logging.
Deployments in Prefect
Deployments are packaging the flows into Prefect Orion Server allowing it to be run with the API (not just with a python script) and add schedule on it (to run alone).
Each deployment is backed by a flow, however, you can have multiple deployments for a unique flow and specify different parameters for example.
Here is an example :

You can then run the following command to create the deployment :
prefect deployment create file.py
That will create the schedules of the runs in the Prefect Orion Server but it will not run the flow, you need Work Queues and Agents to achieve this. Work queues are associated with specific runs from deployments (depending on filter criteria) and sends agents to launch these runs when the time comes.
To know more about work queues and agent, check this link.
Logging in Prefect
It is possible to add any log you want, in addition to those integrated by Prefect, inside your task and flows by calling get_run_logger :

Conclusion
Workflow Orchestration is a must have process when working with pipelines or a product/service involving various steps, all linked between each other. The idea behind tools like Prefect is to fight against negative engineering by having an eye on all the development pipeline and be able to fix quickly.
Naturally, orchestration is about having a logic on the elements that work together and those frameworks improve the way it is done. What I mean is that it is possible to create a large pipeline and tell any task in it some condition to not ruin the entire process. This is clearly more difficult without workflow orchestration tools, especially when many people are working on the project.
Thanks for reading this article, I hope you enjoy it and discover what is Workflow Orchestration as well as Prefect which is a complete tool.