
Optimizing Small Language Models on a Free T4 GPU
Comprehensive Guide to Fine-Tuning Phi-2 using Direct Preference Optimization

“Small” Large Language Models (LLMs) are rapidly becoming a game-changer in the field of artificial intelligence.
Unlike the traditional LLMs which require significant computational resources, these models are much smaller and more efficient. While their performance would be that of the larger ones, they can easily operate on standard devices such as laptops, and even go to the edge. This also means that they can be easily customized and integrated for use on your data set.
In this article, I will first explain the basics and inner workings of the model fine-tuning and alignment processes. Then, I’ll guide you through the process of preference fine-tuning Phi 2, a small LLM with 2 billion parameters, using a novel approach called Direct Preference Optimization (DPO).
Thanks to the small size of the model and optimization techniques such as quantization and QLoRA, we’ll be able to perform this process through Google Colab using the free T4 GPU! This requires some adaptation of the settings and hyperparameters used by Hugging Face to train its Zephyr 7B model.
Table of Contents:
- Why We Need Fine-Tuning and the Mechanics of Direct Preference Optimization (DPO) 1.1. Why We Need Fine-Tuning a LLM 1.2. What is DPO and DPO vs. RLHF 1.3. Why Use DPO? 1.2. How to Implement DPO?
- An Overview of Key Components in the DPO Process 2.1. Hugging Face Transformers Reinforcement Learning (TRL) Library 2.2. Preparing the Dataset 2.3. The Microsoft’s Phi2 Model
- Step-by-Step Guide to Fine-Tuning Phi2 on T4 GPU
- Closing thoughts
Why We Need Fine-Tuning and the Mechanics of Direct Preference Optimization
Why We Need Fine-Tuning a LLM?
Although highly capable, Large Language Models (LLMs)have their limits, especially in handling the latest or specific domain knowledge captured in company’s repositories. To tackle this, we have two options:
- Finetuning, which involves further training the model on specific domains
- Retrieval Augmented Generation (RAG). RAG integrates external database data into LLM prompts, enabling more grounded and current responses.
Fine-tuning is more complex and resource-intensive than RAG, but it offers several benefits such as enhanced data privacy, better task completion and accuracy, as well as greater control and transparency.
The typical fine-tuning process involves three key steps:
- Instruction Dataset Preparation: Prepare an instruction dataset tailored to your specific use cases.
- Supervised Fine-Tuning (SFT): This step teaches language models to follow instructions by adjusting the weights of a pre-trained model using a smaller set of labeled data.
- Alignment: This step aligns the model with human preferences. Significant gains in helpfulness and safety can be had by augmenting SFT with human (or AI) preferences.
Selecting the model’s desired responses and behavior from its very wide knowledge and abilities is crucial to building AI systems that are safe, performant and controllable.
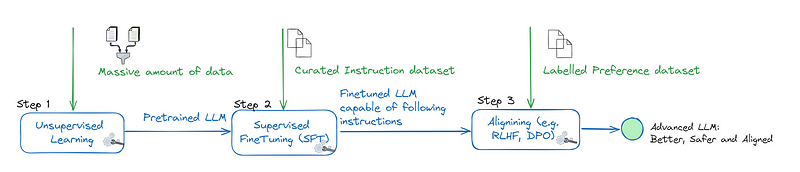
What is DPO and DPO vs. RLHF
Traditional methods for fine-tuning unsupervised LMs, like RLHF (Reinforcement Learning from Human Feedback), are complex and involve traning multiple Language Models.
Direct Preference Optimization (DPO) is a simpler alignment approach that shares the same goals as the common RHLF methods for the training of a Language Model. It trains directly the Language Model to align human preferences with respect to the defined reward function.
DPO Compared to RLHF
RLHF typically follows these steps:
- Manually annotating preferred choices: use people (in some cases another LLM) to review two answers provided for the same question and select the one that aligns more with their interest. They typically opt for the answer that is more helpful and less toxic.
- Training a Reward Model: use this preference dataset to train a reward model. This model assigns higher rewards to responses that are particularly favored by people.
- Reinforcement Learning: improve the LLM through reinforcement learning in order to generate answers that receive the highest scores from people.
This process, while effective, is complex and demands substantial resources.
On the contrary, DPO offers a more streamlined method. It involves training the LLM directly based on specified preferences and eliminates the need for a separate reward model. This direct approach simplifies the fine-tuning process and can be equally effective in certain scenarios.

Why Use DPO?
- Simplification and Stability: DPO offers a stable and performant method for aligning LMs with human preferences. It is simpler, more efficient and computationally lightweight than traditional RLHF methods.
- Direct Training from Preferences: Unlike RLHF, DPO directly trains the LLM to satisfy human preferences using a simple cross-entropy loss, streamlining the preference learning process.
- Comparative Performance: DPO performs similarly or better than existing RLHF algorithms, including PPO-based methods, especially in controlling sentiment of generations and improving response quality in certain tasks.
How to Implement DPO ?
We can take inspiration from Hugging Face’s training process for their Zephyr 7B Beta from Mistral 7B to implement the DPO algorithme. It is a three-step process:
1. Supervised fine-tuning (SFT) on instruction datasets generated by other larger models
2. Annotating data with preference labels: Scoring/ranking LLMs’ outputs using a state-of-the-art LLM
3. Training DPO with the model obtained in Step 1 on the data obtained in Step 2
Fine-tune Llama 2 with DPO by Kashif Rasul, Younes Belkada, and Leandro von Werra.
An Overview of Key Components in the DPO Process
Hugging Face TRL Library
The Hugging Face Transformer Reinforcement Learning (TRL) library is a full stack library, providing a set of tools to train transformer language models with Reinforcement Learning, from the Supervised Fine-tuning step (SFT), Reward Modeling step (RM) to the Proximal Policy Optimization (PPO) step.
TRL supports the DPO Trainer for training language models from preference data.

Preparing the Dataset
The DPO trainer expects a very specific format for the preference dataset.
It should contain 3 entries:
promptthis consists of the context prompt which is given to a model at inference time for text generation
chosencontains the preferred generated response to the corresponding prompt
rejectedcontains the response which is not preferred or should not be the sampled response with respect to the given prompt
from Hugging Face Transformer Reinforcement Learning documentation

The Microsoft’s Phi2 Model
Phi-2, made by Microsoft, is a 2.7 billion-parameter language model. It shows outstanding reasoning and language understanding capabilities, demonstrating state-of-the-art performance among base language models with less than 13 billion parameters.
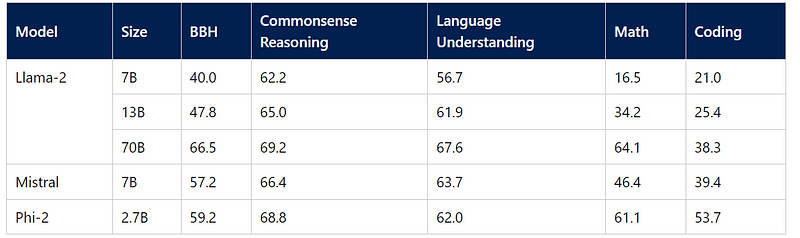
I have selected Phi2 for our experimentation because of its compact size but still highly performant. Notably, Phi2 has not been fine-tuned through RLHF. This makes Phi2 an ideal candidate for exploring preference fine-tuning using a free Google Colab T4 instance.
Step-by-Step Guide to Fine-Tuning Phi2 on a T4 GPU
The first step, as always, is to train your Supervised Fine-Tuning (SFT) model.
In this guide, our focus here will be on preference-tuning Phi2 using a T4 GPU in Google Colab to align the model with human preference.
We’ll assume you already have an SFT-trained model and have signed up for Google Colab. We’ll begin directly with the step of alignment. For a detailed walkthrough of the SFT process and an explanation of optimization techniques like quantization and QLoRa, be sure to check out this article below.
Step 1: Install Dependencies and Import Packages
In this step, we’ll set up our environment by installing necessary dependencies and importing relevant packages. The Hugging Face transformers and peft libraries are installed directly from their GitHub repositories to ensure we're using the latest versions.
# Install necessary libraries
!pip install -q datasets trl bitsandbytes sentencepiece
!pip install -q -U git+https://github.com/huggingface/transformers.git
!pip install -q -U git+https://github.com/huggingface/peft.git
# Importing packages
import os
import gc
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, BitsAndBytesConfig
from datasets import load_dataset
from peft import LoraConfig, PeftModel, get_peft_model, prepare_model_for_kbit_training, AutoPeftModelForCausalLM
from trl import DPOTrainer
import bitsandbytes as bnb
# Define model names and tokens
hf_token = "[YOUR_HF_TOKEN]" # Replace [YOUR_HF_TOKEN] with your Hugging Face token
peft_model_name = "Ronal999/phi2_finance_SFT" # The model obtained after the SFT step
new_model = "phi2_DPO" #the name of the DPO trained modelStep 2: Prepare the Preference Dataset
We’ll use a pre-existing preference dataset from Hugging Face for demonstration purposes. Specifically, we’ll utilize the “orca_dpo_pairs” dataset provided by Intel.
Preference Dataset: https://huggingface.co/datasets/Intel/orca_dpo_pairs
we map the dataset entries to return the desired dictionary via the helper function chatml_format and drop all the original columns.
# Tokenizer setup
tokenizer = AutoTokenizer.from_pretrained(peft_model_name)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
# Helper function to format the dataset
def chatml_format(example):
# Formatting system response
if len(example['system']) > 0:
message = {"role": "system", "content": example['system']}
system = tokenizer.apply_chat_template([message], tokenize=False)
else:
system = ""
# Formatting user instruction
message = {"role": "user", "content": example['question']}
prompt = tokenizer.apply_chat_template([message], tokenize=False, add_generation_prompt=True)
# Formatting the chosen answer
chosen = example['chosen'] + "\n"
# Formatting the rejected answer
rejected = example['rejected'] + "\n"
return {
"prompt": system + prompt,
"chosen": chosen,
"rejected": rejected,
}
# Loading the dataset
dataset = load_dataset("Intel/orca_dpo_pairs")['train']
# Saving original columns for removal
original_columns = dataset.column_names
# Applying formatting to the dataset
dataset = dataset.map(
chatml_format,
remove_columns=original_columns
)
# Displaying a sample from the dataset
print(dataset[1])Step 3 : Train the model with DPO
This step involves the actual training of the Phi2 model using DPO. We’ll set up the DPOTrainer with the appropriate configurations and initiate the training process.
To do this, we need to initialize DPOTrainer with the model that we want to train along with a reference model (ref_model) which will be used to compute implicit rewards for the preferred as well as rejected responses.
Hugging Face suggests three main options to initialize the reference models:
- Create Two Model Instances: Each instance loads your adapter. This method works fine but is quite inefficient.
- Merge Adapter into Base Model: Create another adapter on top, and leave the model_ref parameter null. In this case, the DPOTrainer will unload the adapter for reference inference. This method is more efficient but might lead to reduced performance.
- Load the Fine-Tuned Adapter Twice: To mitigate the downsides of option 2, but with slightly increased VRAM usage, you can load your fine-tuned adapter into the model twice, under different names, and set the respective model/ref adapter names in the DPOTrainer.
In this guide, we’ll use option 3, which offers a good balance between performance and computational resource demands.
# LoRA configuration
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['k_proj', 'v_proj', 'q_proj', 'dense']
)
# Load the base model with BitsAndBytes configuration
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
)
model = AutoPeftModelForCausalLM.from_pretrained(
peft_model_name,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
quantization_config=bnb_config,
is_trainable=True,
)
model.config.use_cache = False
model.load_adapter(peft_model_name, adapter_name="training2")
model.load_adapter(peft_model_name, adapter_name="reference")
# Initialize Training arguments
training_args = TrainingArguments(
per_device_train_batch_size=2,
max_steps=100, # we set up the max_steps to 100 for demo purpose
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=5e-5,
lr_scheduler_type="cosine",
save_strategy="no",
logging_steps=1,
output_dir=new_model,
optim="paged_adamw_32bit",
warmup_steps=5,
remove_unused_columns=False,
)
# Initialize DPO Trainer
dpo_trainer = DPOTrainer(
model,
model_adapter_name="training2",
ref_adapter_name="reference",
args=training_args,
train_dataset=dataset,
tokenizer=tokenizer,
peft_config=peft_config,
beta=0.1, # The parameter 'beta' is the hyperparameter of the implicit reward and is normally set from 0.1 to 0.5. It's important to note that if beta tends to zero, we tend to ignore the reference model.
max_prompt_length=512,
max_length=1024,
)
# Start Fine-tuning with DPO
dpo_trainer.train()Step 4: Save and Upload the Model
After training the Phi2 model using DPO, the next step is to save the fine-tuned model and upload it for future use or sharing.
# Saving the fine-tuned model and tokenizer
dpo_trainer.model.save_pretrained("final_checkpoint")
tokenizer.save_pretrained("final_checkpoint")
# Releasing memory resources
del dpo_trainer, model
gc.collect()
torch.cuda.empty_cache()
# Loading the base model and tokenizer
base_model = AutoPeftModelForCausalLM.from_pretrained(
peft_model_name,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
return_dict=True
)
tokenizer = AutoTokenizer.from_pretrained(peft_model_name)
# Merging the base model with the adapter and unloading
model = PeftModel.from_pretrained(base_model, "final_checkpoint")
model = model.merge_and_unload()
# Saving the merged model and tokenizer
model.save_pretrained(new_model)
tokenizer.save_pretrained(new_model)
# Pushing the model and tokenizer to Hugging Face Hub
model.push_to_hub(new_model, use_temp_dir=False, token=hf_token)
tokenizer.push_to_hub(new_model, use_temp_dir=False, token=hf_token)Step 5 : Run inference
Now, let’s wrap up by testing and running inference on our newly DPO fine-tuned Phi-2 Model. I’d like to demonstrate it quickly through Gradio so I can easily share the results with my friends and colleagues.
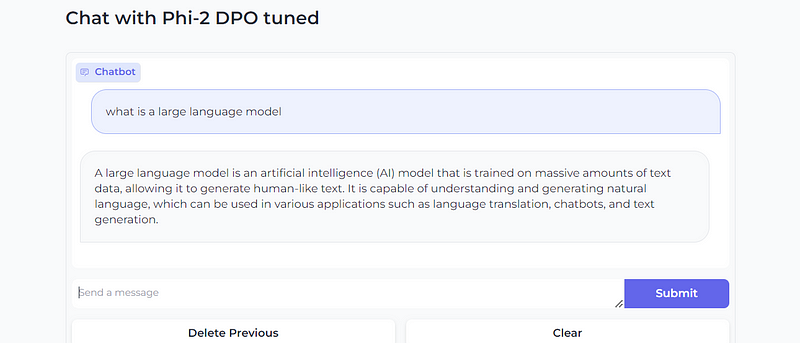
So here is the code snippet to quickly implement a chatbot interface.
# Install Gradio for creating an interface
!pip install -q gradio
import gradio as gr
import torch
from transformers import AutoPeftModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer
from threading import Thread
# Load the fine-tuned model and tokenizer
new_model = "Ronal999/phi2_DPO"
model = AutoPeftModelForCausalLM.from_pretrained(new_model,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,)
tokenizer = AutoTokenizer.from_pretrained(new_model)
model = model.to('cuda:0')
# Define stopping criteria
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [29, 0] # Token IDs to stop the generation
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
# Define the prediction function
def predict(message, history):
# Transform history into the required format
history_transformer_format = history + [[message, ""]]
stop = StopOnTokens()
# Format messages for the model
messages = "".join(["".join(["\n<human>:"+item[0], "\n<bot>:"+item[1]]) for item in history_transformer_format])
model_inputs = tokenizer([messages], return_tensors="pt").to("cuda")
# Set up the streamer and generate responses
streamer = TextIteratorStreamer(tokenizer, timeout=10., skip_prompt=True, skip_special_tokens=True)
generate_kwargs = dict(
model_inputs,
streamer=streamer,
max_new_tokens=1024,
do_sample=True,
top_p=0.95,
top_k=1000,
temperature=1.0,
num_beams=1,
stopping_criteria=StoppingCriteriaList([stop])
)
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
# Yield partial messages as they are generated
partial_message = ""
for new_token in streamer:
if new_token != '<':
partial_message += new_token
yield partial_message
# Launch Gradio Chat Interface
gr.ChatInterface(predict).queue().launch(debug=True)Closing Thoughts
RLHF is a key building block of the most advanced LLMs.
In this article, we’ve explored Direct Preference Optimization (DPO), a powerful alternative of RLHF that dramatically simplifies the alignment process, paving the way for safer and more reliable LLMs.
We have showed how to preference fine-tuning a small language model, specifically Microsoft’s Phi2, using DPO on a free T4 GPU. The potential of small LLMs like Phi2, especially when fine-tuned with efficient methods like DPO, is huge and holds exciting possibilities.
Additionally, for those interested, incorporating tools like Weights & Biases (wandb) can be very useful to track experiments and evaluate model performance.
As usual, you can find my Google Colab notebook here.
Before you go! 🦸🏻♀️
If you liked my story and you want to support me:
- Throw some Medium love 💕(claps, comments and highlights), your support means the world to me.👏
- Follow me on Medium and subscribe to get my latest article🫶
References
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model by Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn
- Fine-tune Llama 2 with DPO by Kashif Rasul, Younes Belkada, and Leandro von Werra.
- Preference Tuning LLMs with Direct Preference Optimization Methods by Kashif Rasul, Edward Beeching, Lewis Tunstall, Leandro von Werra and Omar Sanseviero.
- Hugging Face Transformer Reinforcement Learning documentation
- Supervised Fine-Tuning and Direct Preference Optimization on Intel Gaudi2





