
#30DaysOfNLP
NLP-Day 8: How To Read Between The Lines — Topic Modeling With LSA.
An introduction to Latent Semantic Analysis
In the previous article, we covered the topic of the term frequency-inverse document frequency (TF-IDF). We even implemented a TD-IDF vectorizer from scratch. And we learned how a TF-IDF vector or matrix can help us to estimate the importance of words in a given text or even across a whole corpus.
Now, we’re ready to take the next step.
We’re ready to step into the realm of Latent Semantic Analysis (LSA).
In the following sections, we’re going to learn about topic vectors. What they represent. And how to create them, by using the scores from our TF-IDF vectors.
But first of all, we will build a stronger understanding of the fundamental concept of Latent Semantic Analysis.
So take a seat, don’t go anywhere, and make sure to follow #30DaysOfNLP: How To Read Between The Lines — Topic Modeling With LSA.
I’m totally fine with TF-IDF. Why LSA?
We counted. We counted a lot.
Up until now, we created numerous word counts, Bag-Of-Words, and vectors with normalized term frequencies. We even constructed TF-IDF vectors or matrices to score the importance of a word.
However, TF-IDF is no panacea.
If we want to score the meaning and the topics of a given text, TF-IDF won’t cut the deal alone.
Let’s imagine two documents.
An academic paper about Latent Semantic Analysis on the one hand and on the other hand, this blog. Both revolve around the same content.
Although covering the same topic, the TF-IDF vector for this blog may not be very close to similar-meaning sections in the academic paper. The words used in the academic paper are most likely more sophisticated and rigorous compared to the casual language in this blog.
TF-IDF vectors count the exact terms in a document.
Different word usage or spellings will result in a completely different vector representation. This messes up search engines and document similarity measures.
One approach to deal with this is normalization.
But this makes it only worse.
Lemmatization, for example, consolidates words with different spellings that share the same lemma into a single token. This, however, doesn’t ensure the merging of words with similar meanings.
On the contrary. We could end up erroneously combining antonyms. Words with the exact opposite meaning, yet similar spelling.
So we need another approach. An approach that still generalizes well but accounts for the underlying meaning.
Introducing Latent Semantic Analysis
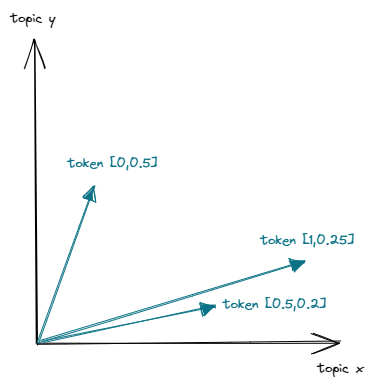
Let’s assume we have a TF-IDF vector for a particular document that we want to convert into a topic vector. We can also think about topic vectors as how much each word contributes to certain topics.
In order to transform a TF-IDF vector into a topic vector, we need to find an algorithm to not only determine the topics but also to specify the weights for each term, telling us how much the word contributes to every single topic.
So how can we tell which words belong together, sharing the same topic and similar meaning?
By looking at its “company”.
One approach to deriving the topic of a word is to consider the number of co-occurrences in the same document. And we already did half the job by creating our Bag-Of-Words and TF-IDF matrices.
LSA is an algorithm to analyze our TF-IDF matrix and gather up single words into topics.
The underlying algorithm works like Principal Component Analysis (PCA). In fact, LSA is exactly the same math as PCA, however, the wording differs depending on the context.
The main idea here is to transform a large set of features (TF-IDF matrix) into a smaller one (topic vectors) while preserving as much information as possible. This is also known as dimensionality reduction.
Loosely speaking, the algorithm involves the computation and decomposition of the covariance matrix. By selecting the most important eigenvectors and eigenvalues, we can project the original matrix into its reduced dimension.
We can visualize the idea like the following:
LSA and its relatives
Although Latent Semantic Analysis is mostly performed by using PCA, two cousins exist:
- Linear discriminant analysis (LDA)
- Latent Dirichlet allocation (LDiA)
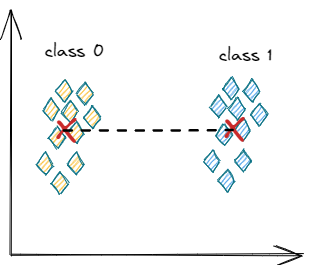
LDA is a straightforward and fast dimension reduction and classification technique.
Imagine, we want to classify email into spam or ham. The core idea is to compute two centroids (average positions) for each class. Next, we calculate the vector difference between the centroids. A line that connects them. This is all we need to train our LDA model.
Now, if we want to infer or predict the class of a new sample, we simply have to find out if the sample is closer to the spam- or ham-centroid.
Latent Dirichlet allocation is a non-linear, generative statistical model, that generally takes longer to train, making it less practical for real-world applications.
However, the algorithm is considered to generate topics, more closely to human intuition. Thus making them easier to interpret and explain.
Conclusion
In this article, we introduced the concept of Latent Semantic Analysis. We learned that we can transform our TF-IDF vectors into topic vectors, allowing us to create a more general representation of a given document with fewer dimensions.
However, we have not applied any of the theories yet.
In the next episode, we will get our hands dirty, roll up our sleeves and perform a semantic analysis by utilizing sklearn’s implementation of PCA.
So take a seat, fire up your IDE, make sure to follow, and never miss a single day of the ongoing series #30DaysOfNLP.
Enjoyed the article? Become a Medium member and continue learning with no limits. I’ll receive a portion of your membership fee if you use the following link, at no extra cost to you.
References / Further Material:
- Hobson Lane, Cole Howard, Hannes Max Hapke. Natural Language Processing in Action. New York: Manning, 2019.