
#30DaysOfNLP
NLP-Day 20: You Better Pay Attention To Transformers (Part 2)
Understanding the general and transformer attention mechanism
In the last episode, we gently introduced the concept of attention in general as well as in the context of machine learning. We, however, purposely stayed on the surface, allowing us to get a general overview.
Now, it’s time to get into the weeds. To dive deeper and explore the attention mechanism in greater detail.
In the following sections, we’re going to uncover the inner workings and the main computational steps of the attention mechanism. We will learn about the general and the transformer-based attention mechanisms, understanding the meaning and purpose of things like queries, keys, and values.
So take a seat, don’t go anywhere, and make sure to follow #30DaysOfNLP: You Better Pay Attention To Transformers (Part 2)
The attention mechanism
Introduced by Bahdanau et al. (2014), the attention mechanism provides a way to address the bottleneck problem that arises due to fixed-length encoded vectors, allowing the decoder to only access a limited part of the information.
The core idea to overcome this problem is to allow the decoder to dynamically select and utilize the most important parts of the input sequence. This can be achieved by the computation of a context vector that represents the attention by a weighted combination of the encoded input vector.
The attention mechanism consists of 3 different computational steps.
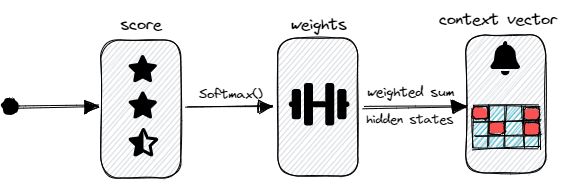
First of all, we have to calculate the alignment scores that tell us how well the elements of the input sequence align with the output at the current time step. We can implement this function by a feedforward network that takes in the encoded hidden states and the decoder’s previous output as input.
The second step involves the computation of the weights which can be achieved by applying a softmax function to the previously calculated alignment scores.
At last, we create a context vector by taking the weighted sum of all encoder hidden states at each time step.
These steps define the nuts and bolts of the attention mechanism. However, the procedure can be further generalized, where the information is not related in a sequential fashion.
The general attention mechanism
Similar to the attention mechanism, the general version is also defined by three components: The queries, keys, and values.
The query contains the decoder’s output from the previous time step whereas the values are defined by the encoded inputs. We can think of the whole process as some kind of query against a database with key-value pairs. Where the keys are the vectors and the values are the encoded hidden states.
Next, we follow the same computational steps as described earlier.
First of all, we match each query vector against a key to compute a score value which is defined by the dot product of the query and the corresponding key vector.
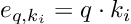
Once again we apply a softmax function to calculate the weights.
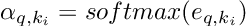
The next step involves the computation of the generalized attention by taking the weighted sum of the value vector with the associated key.
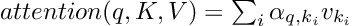
Let’s consider a machine translation task as an example.
We take a specific word from an input sequence and make use of its query vector to score it against each key in the database. Doing so, allows us to capture the information of how our specific word relates to other words in the sequence. Next, we simply scale the values according to the attention weights, enabling us to retain focus on the most relevant words.
Transformer attention
Now, the attention mechanism is taken even one step further.
The approach, described in Attention Is All You Need by Vaswani et al. (2017), revolutionized the attention mechanism by ditching recurrence and convolutions and instead relying solely on a self-attention mechanism.
Self-attention, sometimes called intra-attention, computes a representation of a sequence by relating different words in the same sequence.
The main components used by the Transformer attention are quite similar to the ones we already encountered in the earlier sections.
We also make use of query, key, and value vectors. However, this time we pack them together as a set and store them into three matrices Q, K, and V respectively. Next, we have three projection matrices, allowing us to generate different subspace representations of the query, key, and value matrices. The last component is yet another projection matrix for the multi-head output.
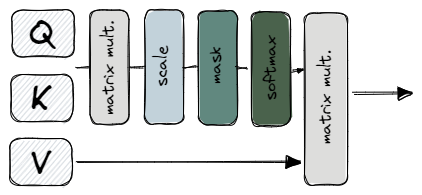
The computational steps needed follow the general attention mechanism by implementing scaled dot-product attention.
Since we store the queries, keys, and values in three matrices, we can apply the scaled dot-product attention to the entire set of queries simultaneously.
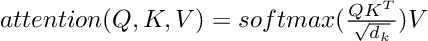
The scaling factor is used to deal with the problem of vanishing gradients that can arise due to the computation of large dot-products in combination with the softmax function.
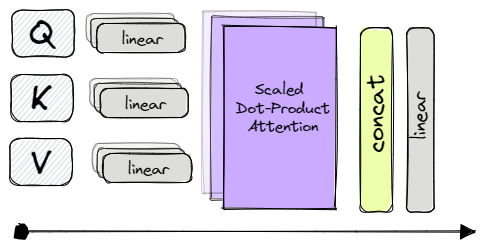
Building upon the single-head attention, the multi-head attention mechanism linearly projects the queries, keys, and values multiple times. Each time using a different learned projection.
This allows us to apply the single attention mechanism to each projection in parallel and produce multiple outputs which are then concatenated and projected one last time in order to produce the final output.
The underlying idea here is to be able to extract information from different learned representation subspaces which would be impossible by simply relying on a single attention head.
Conclusion
In this article, we covered the attention mechanism in general and in the context of a transformer-based application. We introduced the main components as well as the computational steps needed to compute the attention.
By encountering the concept of self-attention, we started to build the foundation needed to understand, apply, and implement a transformer-based neural network.
In the next episode, we continue building upon that foundation by dissecting the transformer model.
So take a seat, don’t go anywhere, make sure to follow, and never miss a single day of the ongoing series #30DaysOfNLP.
Enjoyed the article? Become a Medium member and continue learning with no limits. I’ll receive a portion of your membership fee if you use the following link, at no extra cost to you.
References / Further Material:





