
#30DaysOfNLP
NLP-Day 19: You Better Pay Attention To Transformers (Part 1)
Introducing the concept of attention

In the last episode, we implemented a sequence-to-sequence model for machine translation. We did this by creating a network in an encoder-decoder structure that made use of two LSTMs, mapping one sequence to another.
This approach worked very well for short phrases.
But what if we want to work with longer input sequences? What if we want to summarize a complete online article for example?
As we can imagine, trying to compress a complete document into a single thought vector and determining the most important information can become pretty difficult and computationally expensive. Thus, we need a way to focus.
We need a way to pay attention.
In the following sections, we’re going to learn what attention actually is, why it’s important, and how we can leverage the general concept of attention in the context of machine learning.
So take a seat, don’t go anywhere, and make sure to follow #30DaysOfNLP: You Better Pay Attention To Transformers (Part 1)
Focalization and concentration
Before we dive straight into the depths, the nitty-gritty of the attention mechanism, we should get an overall feel of the concept.
We should understand what attention actually means.
Attention can be described as an overall level of alertness, the ability to engage with one’s surroundings by selectively concentrating on the most important part of the information, while actively ignoring other parts.
A popular field of study incorporating the concept of attention is computer vision. The use of saliency maps provides a visual way to interpret and see which parts of the image the network pays the most attention to.

Memory and attention are tightly coupled.
It’s important to realize the dependencies between memory capacity and the ability to focus on the most salient information. The ability to pay attention.
Let’s consider our brain for example.
We as humans don’t have unlimited memory capacity. On the contrary, it is actually quite limited. Thus, it becomes crucial anility to actively select and decide which information is important enough to be stored and remembered.
Paying attention
Now, we have a basic idea of what attention is. But how does all of that fit into the context of machine learning?
In machine learning, attention describes the ability, and the mechanism to dynamically highlight and use the most salient, the most important part of the information at hand. In other terms, we need a dynamic way to decide which information is important and to what degree.
An attention-based system has generally three components.
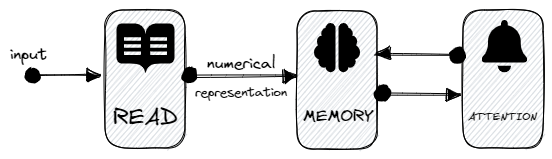
At first, a process that reads and converts raw data into a numerical vector representation with one feature vector for each word position. Second, a list of feature vectors created from the first component’s output that represents some kind of memory. And third, a process that “pays attention”, that “exploits” the memory when performing a certain task.
We can think of the encoder-decoder framework as an example.
First of all, we process an input sequence of words and feed that sequence into an encoder. The encoder outputs a numerical representation, a vector for every element.
Next, we create a list based on the encoder’s output and the decoder’s previous hidden states. This list represents some kind of memory that can be used to dynamically highlight which part of the information is most important. We can imagine the output in the form of a learned heat map.
Now, at each time step, we compute score values based on the memory and the decoder’s previous state. The score value tells us how well the input sequence aligns with the current output. After some further processing (normalizing, weighting, etc.) we generate a context vector that basically represents the attention mechanism. The context vector indicates which part of the information or which context is most important to the current output.
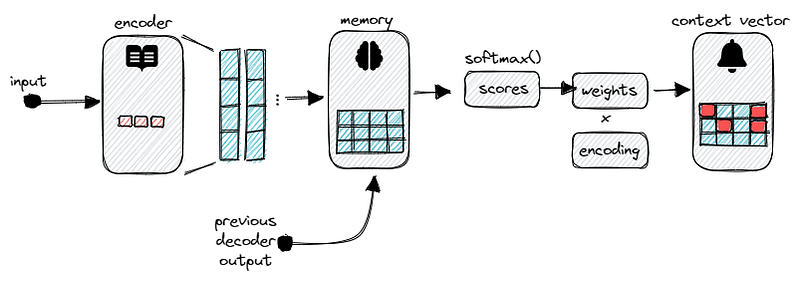
We can also think of the complete process as some form of iterative re-weighting that allows the attention mechanism to flexible and dynamically highlight the most salient parts needed for output generation.
Once the context vector is obtained, we feed it into the decoder to generate the final translated output.
Conclusion
In this article, we gently introduced the concept of attention in general and in the context of machine learning. We not only developed an overall understanding but also got to know the different components of the attention mechanism.
Now it’s time to get to the nuts and bolts of the attention mechanism.
In the next episode, we cover the general and the transformer attention mechanisms, discovering the computational steps needed to create a context vector.
So don’t go anywhere, pay some attention, make sure to follow, and never miss a single day of the ongoing series #30DaysOfNLP.
Enjoyed the article? Become a Medium member and continue learning with no limits. I’ll receive a portion of your membership fee if you use the following link, at no extra cost to you.
References / Further Material:
- https://arxiv.org/abs/1409.0473
- Attention in Psychology, Neuroscience, and Machine Learning
- Deep Learning (Ian J. Goodfellow, Yoshua Bengio and Aaron Courville), Chapter 12, MIT Press, 2016.




