
#30DaysOfNLP
NLP-Day 17: Machine Translation With Sequence 2 Sequence (Part 1)
Introducing Sequence 2 Sequence models and related tasks
Yesterday, we implemented a long-short-term memory with the help of the Keras API. We generated novel text in a certain style our model had learned during the training stage.
But what about other tasks, like chatbot conversations, question answering, document summarization, or machine translation?
These are all sequence-to-sequence-related problems.
In the following sections, we’re going to learn about sequence-to-sequence models, their underlying concepts, their inner workings, and how to build a sequence-to-sequence model by making use of an encoder-decoder architecture.
So take a seat, don’t go anywhere, and make sure to follow #30DaysOfNLP: Machine Translation with Sequence 2 Sequence (Part 1)
Encoding? Decoding?
So far, we created neural networks to perform sentiment classification or to generate novel text in a certain style. But what if we want to build a conversational chatbot for example? Or translate text from one language into another?
Both tasks belong to the world of sequence-to-sequence-related problems, the mapping of one sequence to another with unknown and most likely different lengths.
In order to solve those problems, we can once again rely on the magic of long-short-term memory. But this time, we need two networks instead of just one. We need an encoder-decoder structure.
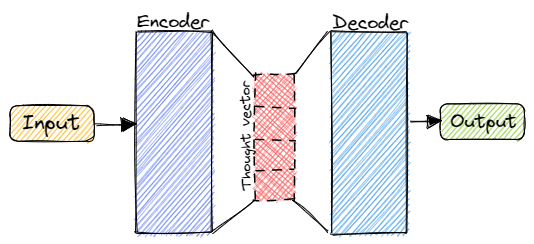
The first half of our model is the sequence encoder. A network that turns a sequence, such as natural language text, into a lower-dimensional representation — a thought vector, similar to the memory state we already encountered in the previous episodes.
The second half of our encoder-decoder structure is the sequence decoder. The decoder simply turns the lower-dimensional representation, the thought vector, back to human-readable text.
Loosely speaking, we just need to extract the thought vector from the encoder and feed this internal representation as input to the decoder.
One just isn’t enough
Let’s imagine we want to translate the following sentence from English to German.
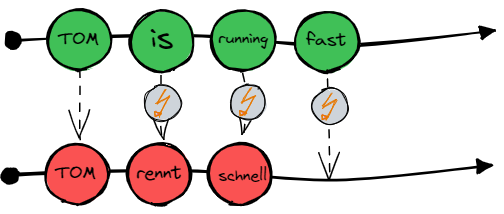
"Tom is running fast."
"Tom rennt schnell."Directly using a single LSTM to map from one language to another gets us into trouble quite fast.
In our example, the phrase “is running” is translated to “rennt”. Now, we have a problem since we can’t simply map token to token at each time step. We have to deal with an offset.
Thus, we need the input and output sequence to have the same length in order for a single LSTM to work. However, this is rarely the case when it comes to translation.
Sequence-to-sequence models (seq2seq) solve this particular problem by creating an input representation in the form of a fixed-length vector. This vector is called the thought vector and it includes two parts. The output of the hidden layer and the memory state of the LSTM.
Now, we can initialize the second network, the decoder with the thought vector and a “start token”. Primed with the initial state and the special token, the network has to learn to generate the first element of the target sequence e.g. a character or a word.
Sequence-to-sequence pipeline
Training a sequence-to-sequence model requires some preprocessing steps.
First of all, we need to pad the input as well as the target data to match the longest sequence.
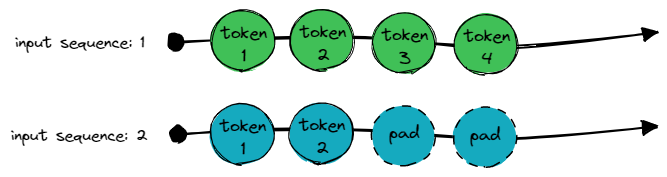
Note: Input and target sequences don’t need to have the same length.
In addition to the padding, we also need to prepare a second version of the target data. The output sequence has to be annotated with the “start” and “stop” tokens, to tell the decoder when the task begins and when the job is done.
So basically each training example is provided in the form of a triplet: The input sequence for the encoder, the annotated target sequence for the decoder, and the target sequence without the “start” token used for the loss calculations.
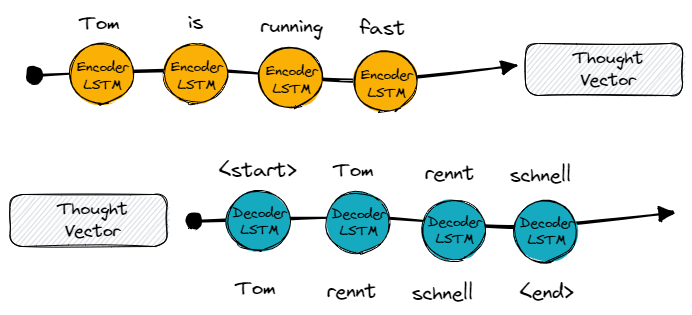
In order to start the training and learning process, we simply pass the input sequence to the encoder and the annotated target sequence to the decoder.
During inference, however, we don’t have access to the target sequence. Therefore, we extract the thought vector from the encoder based on our new input sequence.
Next, we initialize the decoder with the thought vector and make use of the “start” token to generate the first element.
Now, we update the thought vector with the decoder states and use the updated vector as well as the generated token as new input for the decoder in the next iteration. This process repeats itself until either a “stop” token is generated or we reach the maximum sequence length.
Conclusion
In this article, we learned all about sequence-to-sequence. The related problems and key applications. We also learned why a single LSTM is not enough. How sequence-to-sequence models are built, structured, and why they work.
However, we stayed in the world of theory and have yet to apply any of that knowledge.
In the next episode, we’re going to change that. We will implement our own encoder-decoder structured sequence-to-sequence model.
So take a seat, don’t go anywhere, make sure to follow, and never miss a single day of the ongoing series #30DaysOfNLP.
Enjoyed the article? Become a Medium member and continue learning with no limits. I’ll receive a portion of your membership fee if you use the following link, at no extra cost to you.
References / Further Material:
- https://arxiv.org/abs/1409.3215
- Deep Learning (Ian J. Goodfellow, Yoshua Bengio and Aaron Courville), Chapter 10, MIT Press, 2016.
- Hobson Lane, Cole Howard, Hannes Max Hapke. Natural Language Processing in Action. New York: Manning, 2019.