
#30DaysOfNLP
NLP-Day 13: Get Loopy With Recurrent Neural Networks (Part 1)
Starting to remember things with Recurrent Neural Networks
In the last episode, we classified movie reviews as either being positive or negative by implementing our very first Convolutional Neural Network. We were able to extract meaningful relationships by accounting for the word order.
However, we did this based on a just small frame of a few tokens.
In the following sections, we‘re going to get loopy. We will learn about Recurrent Neural Networks, the underlying concepts, how they work, and why they’re useful. We will broaden our horizons, widen our small frame of just a few tokens, and start to remember things.
So take a seat, don’t go anywhere, and make sure to follow #30DaysOfNLP: Get Loopy With Recurrent Neural Networks (Part 1)
So far so good
Up until now, we’ve extracted information about the relationships between words based on word order with the help of Convolutional Neural Networks. And there is nothing particularly wrong with that.
However, this approach is based on a small frame. A tiny sliding window of just a few tokens. But what if we want to broaden our horizons? What if we want to consider more than just a few words? What if we even want to remember the previous words?
Words in a document or sentence are rarely completely independent of each other. Not only the ordering of words but also the sequence of appearance matters.
Let’s consider the following two sentences.
"The angry man stepped into the room."
"The funny man stepped into the room."Depending on the word preceding "man", we either deal with a pleasant or not so pleasant addition to our current company. The swapping of the adjective changes the meaning of the sentence and the emotions invoked.
So how do we remember?
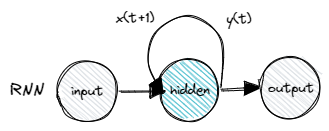
Recurrent Neural Networks provide a way to remember the past words within a sentence.
The core idea is to somewhat recycle the previous output and use it again in the hidden layer at the current time step, in concurrence with the new input. Such a technique can also be interpreted as some kind of auto-regressive model in other domains (e.g. finance)
So we basically tell a neural network what has happened before along with what is happening now.
Commonly, the structure of a Recurrent Neural Network is shown differently. We normally “unroll the net”, depicting different snapshots of the same network with a single set of weights at multiple time steps.
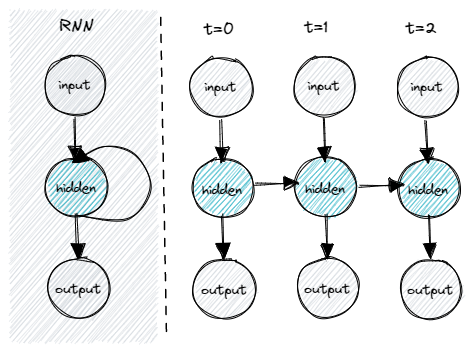
A concept of time
The network is able to learn how much weight or importance to give to events of the past, as we provide an input sequence token by token.
This is important.
Instead of passing the complete collection of word vectors all at once (like we did in the last episode, implementing our Convolutional Neural Network), we take the sample and feed one token at a time, individually to the network. Now, the network has some idea, some concept of time — before and after.
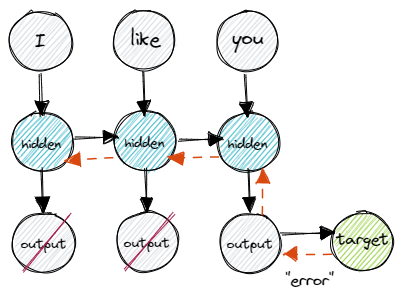
We collect the output of the last time step, compare it to the target label and backpropagate the error through the whole computational graph. All the way back to the first input with time step 0. Once, we arrive at the beginning, we can update the set of weights.
Too good to be true
Recurrent Neural Networks can quickly get very expensive to train. Especially for longer sequences of, for example, 10 tokens. The more tokens, the more time steps, the more computational steps, and backpropagation has to happen. RNNs are costly.
And there is one more catch.
If a network gets deeper a new problem arises. The problem of vanishing or exploding gradient. When a network has enough layers, the error signal can either grow or dissipate with each computation of the gradient. This vanishing or exploding of the gradient influences the update process of our weights to go in the wrong direction. Either due to a too strong or no signal at all.
Although Recurrent Neural Networks are shallow, depending on the input sequence, the network can unroll into multiple time steps. Those multiple steps can be the reason that we experience a vanishing or exploding gradient during the training process.
So how do we implement a Recurrent Neural Network?
Fortunately, we can rely once again on the Keras API and use the provided implementation.
Conclusion
In this article, we learned about Recurrent Neural Networks, how they work, the underlying concepts, why they might prove useful, and how we can take the first step toward a memory.
However, we did all of that just in theory.
In the next article, we roll up our sleeves and start implementing. We will use the same dataset from the last episode, classify movie reviews, and compare the results between the two different neural network implementations.
So take a seat, open up your IDE, make sure to follow, and never miss a single day of the ongoing series #30DaysOfNLP.
Enjoyed the article? Become a Medium member and continue learning with no limits. I’ll receive a portion of your membership fee if you use the following link, at no extra cost to you.
References / Further Material:
- Deep Learning (Ian J. Goodfellow, Yoshua Bengio and Aaron Courville), Chapter 10, MIT Press, 2016.
- Hobson Lane, Cole Howard, Hannes Max Hapke. Natural Language Processing in Action. New York: Manning, 2019.





