

Multimodal Retrieval Augmented Generation
An implementation with Azure AI Search and GPT-4-turbo
Generative AI systems have demonstrated stunning capabilities in producing new content, given users’ questions in natural language. However, generating high-quality and relevant content is not an easy task, especially when it requires factual or domain-specific knowledge. How can we ensure that the generative models produce accurate and useful outputs for various tasks and contexts?
One promising approach is retrieval augmented generation (RAG), which combines the power of large language models (LLMs) with the information retrieval capabilities of search engines.
Note: in the retrieval stage, we can leverage different search methods depending on our application. Traditional search engines might leverage keyword or semantic search; more recent approaches would rather rely on vector search, which leverages text embeddings (both for the knowledge base and user’s query) to compute text similarities and retrieve the most similar context, given a user query; finally, there are methods that combine both semantic and vector search (hybrid methods) to achieve better performance, as proposed by the Azure AI Search service.
RAG is a technique that allows the generative models to access external knowledge sources, such as documents, databases, or web pages, and use them as additional inputs for generating responses. By doing so, RAG can improve the quality, diversity, and reliability of the generated content, as well as provide transparency and verifiability for the users.
Insofar, RAG has been mainly applied to unstructured textual data, which may not capture the full richness and diversity of the world knowledge. What about images, video, audio and other data format?
To answer this question, researchers have proposed the new method of multimodal retrieval-augmented generation (MM-RAG), which extends RAG to incorporate multiple modalities of information. MM-RAG can also be combined with Large Multimodal Models (LMMs), which are pre-trained on massive amounts of multimodal data, such as image-text, video-text, or audio-text pairs and can perform cross-modal tasks, such as image captioning, visual question answering, or text-to-image generation.
In this article, we are going to cover the architecture behind MM-RAG frameworks, focusing on a scenario which includes images as knowledge base.
Multimodal embedding
In a classical RAG approach, the “R” stands for Retrieval, meaning we need to store our knowledge base somewhere and format it in such a way that, given a user’s input, we can retrieve the relevant context to produce the generative answer (that explains the Augmented Generation step of the whole framework). Typically, in LLMs-powered applications, the unstructured text of the knowledge base is transformed into vectors (a process called embedding) into a multidimensional space, in such a way that their mathematical distance is representative of the corresponding texts’ semantic similarity. By doing so, we can then embed the user’s query and retrieve the context that has the closest mathematical distance (or, in other words, the greatest semantic similarity) to that query.
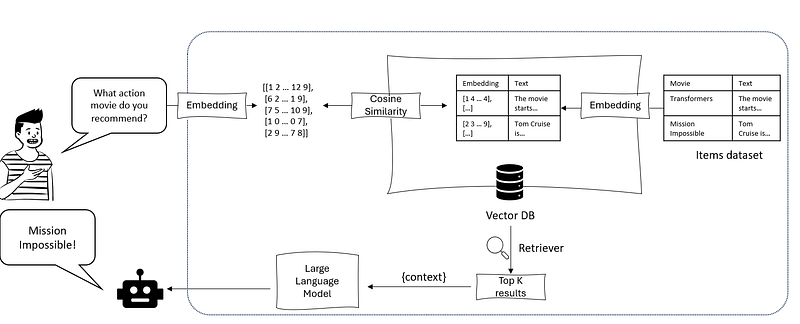
With data different from texts, such as images, the process is similar, with the difference that embedding space will be shared across different domains. For example, we will have a text and images’ embeddings in the same multidimensional space.
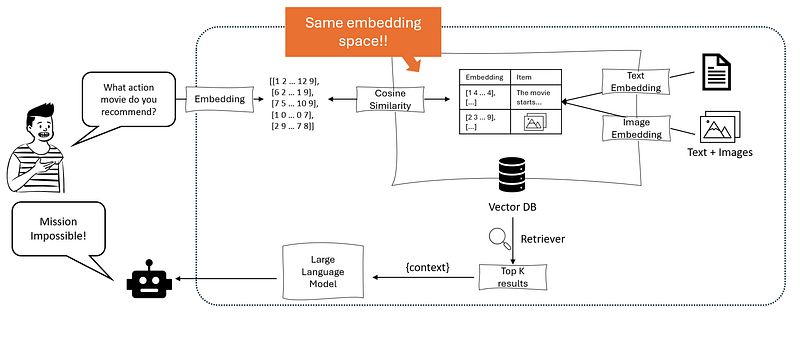
Now, there are two main ways to create your images’ embeddings:
- Option A: Leveraging a model that is capable of producing embeddings directly from images, typically a Visual Transformer (ViT). In fact, ViT leverages the same encoder-decoder framework of standard Transformers, with the difference that they are trained on images’ patches rather than bag of words. An example of a ViT is CLIP, developed by OpenAI (you can read the technical paper here).
- Option B: Splitting the task into two steps: 1) using a computer vision model to get a textual description of the image and 2) use an embedding model such as the text-ada-002 to vectorize the image’s description. In this scenario, the vision model could also be a Large Multimodal Model (LMM) such as the GPT-4v or LLaVA (this can lead to more accurate descriptions and, consequently, more relevant embeddings).
Regardless of the approach, the ultimate goal is that of producing a shared embedding space where vectors of both data formats (having the same dimensionality) can live, keeping the same idea behind text-only embedding: similar concepts will be represented by vector which are close among each others.
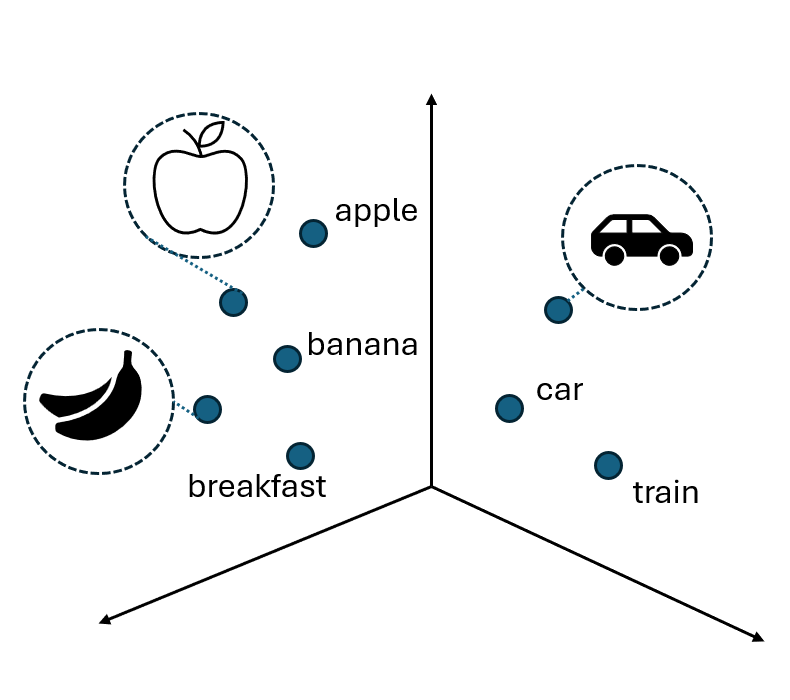
In this article, we are going to explore Option B, leveraging the Azure AI services computer vision capabilities, as well the Azure AI search as indexer and VectorDB.
Azure AI Search as multimodal VectorDB
Azure AI Search is a cloud-based service that provides developers with the tools to incorporate sophisticated search capabilities into their applications. In the “pre GenAI” era, Azure AI Search (formerly called Cognitive Search) was mainly based on either keyword or semantic search, along with advanced indexing capabilities which allows for filters, facets, and geospatial search capabilities, making it versatile for a variety of applications.
With the advent of GenAI, vector search leveraging embedding became a new powerful approach for search engine, and Azure AI search incorporated this function (using the text-ada-002 embedding model) among its capabilities, allowing for both full vector and hybrid (vector + semantic) search options.
On top of that, Azure AI search can be further enhanced with AI capabilities, to allow multi-modal indexing and vectorization.
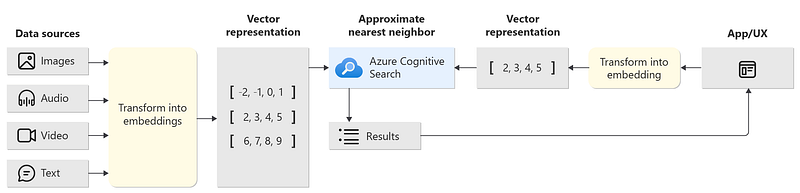
More specifically, it allows a native integration with Azure AI vision capabilities that is able to generate images’ captions (to be then further embedded).
Let’s see how to vectorize images with Azure AI search.
Prerequisites
- Azure AI Search resource →Create a search service in the portal — Azure AI Search | Microsoft Learn
- Azure OpenAI embedding deployment →What is Azure OpenAI Service? — Azure AI services | Microsoft Learn
- An Azure AI services multi-service account →https://learn.microsoft.com/en-us/azure/ai-services/multi-service-resource?tabs=windows&pivots=azportal
- Azure Blob storage where to upload images→Create a storage account — Azure Storage | Microsoft Learn
Steps
- Navigate your Azure AI resource. In the overview page, select “import and vectorize data”:
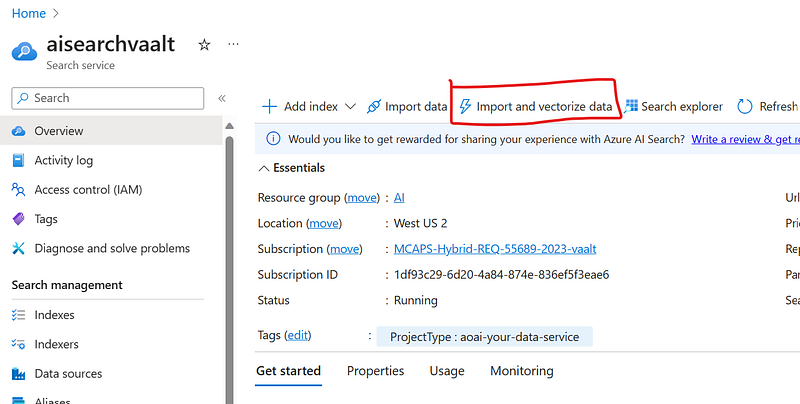
- Link the blog container where you uploaded the content to be vectorized:
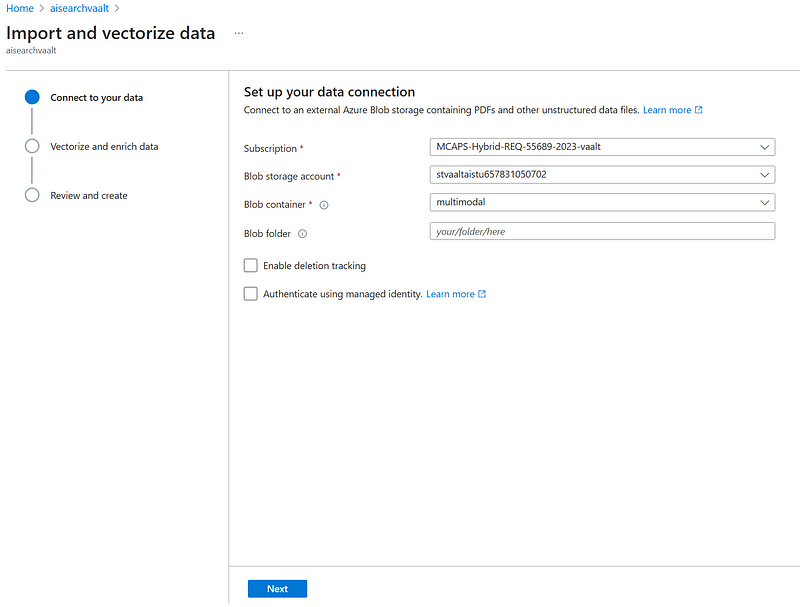
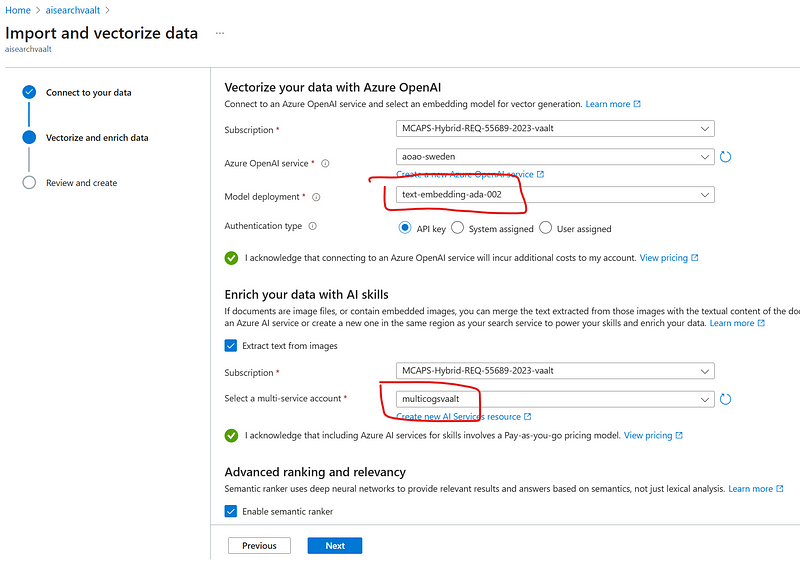
- Configure the embedding model to enable vector search and the Vision enhancements to enable image captioning (to be then embedded by the text-ada-002). To do so, you will need both an Azure OpenAI embedding deployment, and an Azure AI multi-service account. This latter will leverage the vision capabilities of Azure AI services to generate images’ captioning.
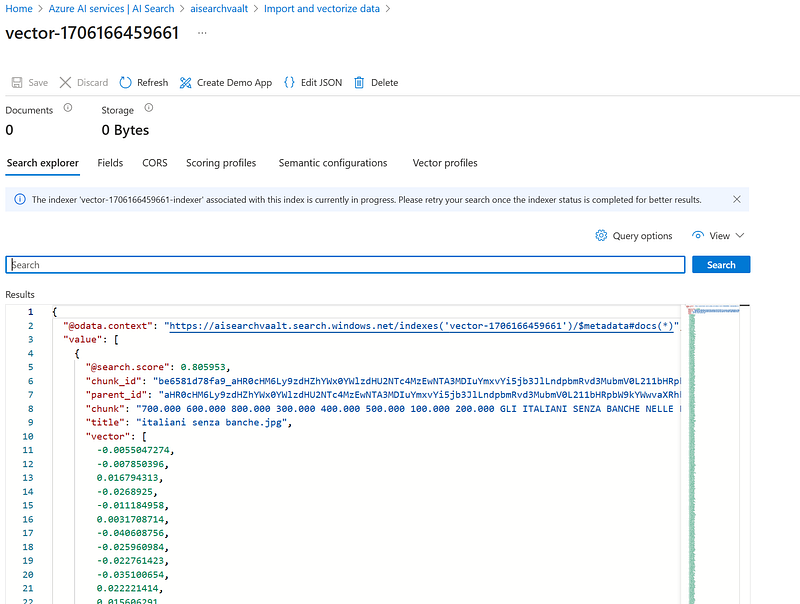
- Once created, you will be able to search the index and see the vectors associated with each image:
Now we can link our index to the Generative model. For this purpose, we are going to leverage the GPT-4 8K in the Azure OpenAI Playground.
Adding the generative model
In the Azure OpenAI Playground, you can deploy a generative model (like the GPT-4 8K) and linking the multimodal index created in the previous section:
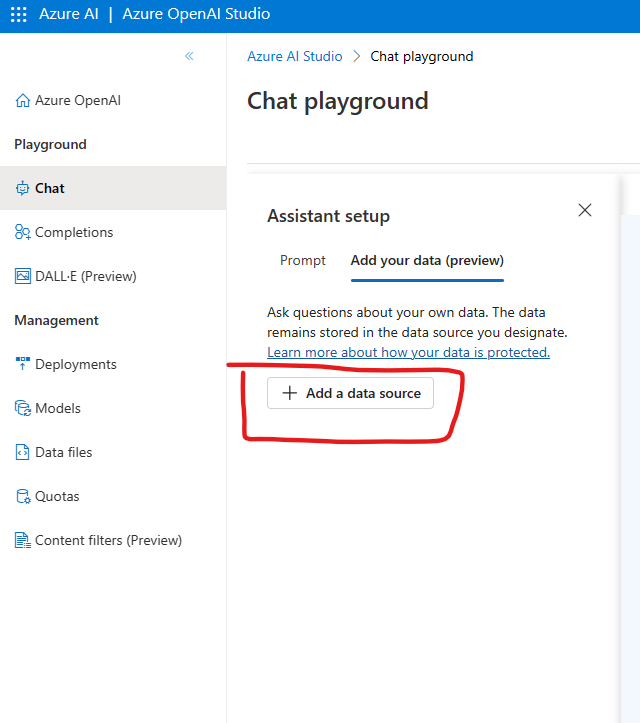
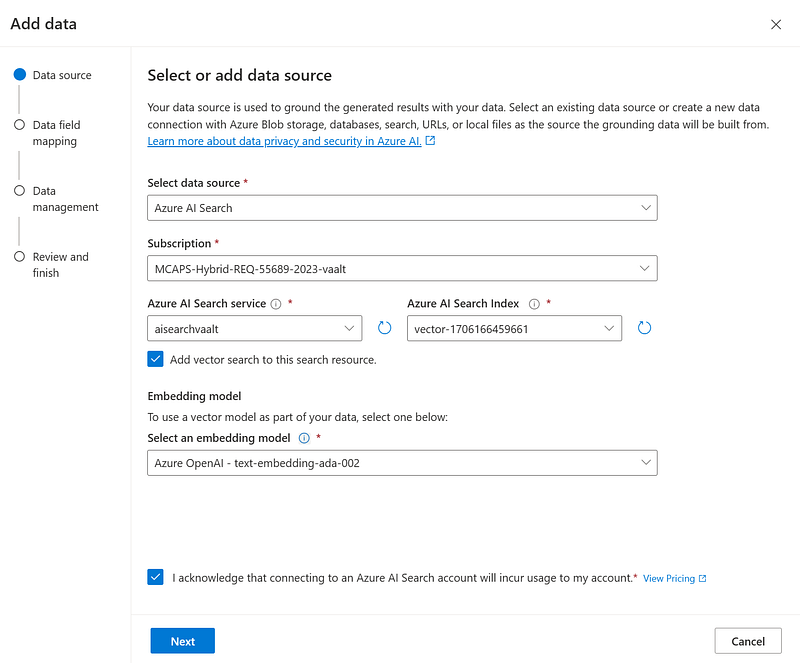
Now that we’ve linked the index to our generative model, we can start asking questions about the images. For example, let’s ask something related to the balance sheet below:
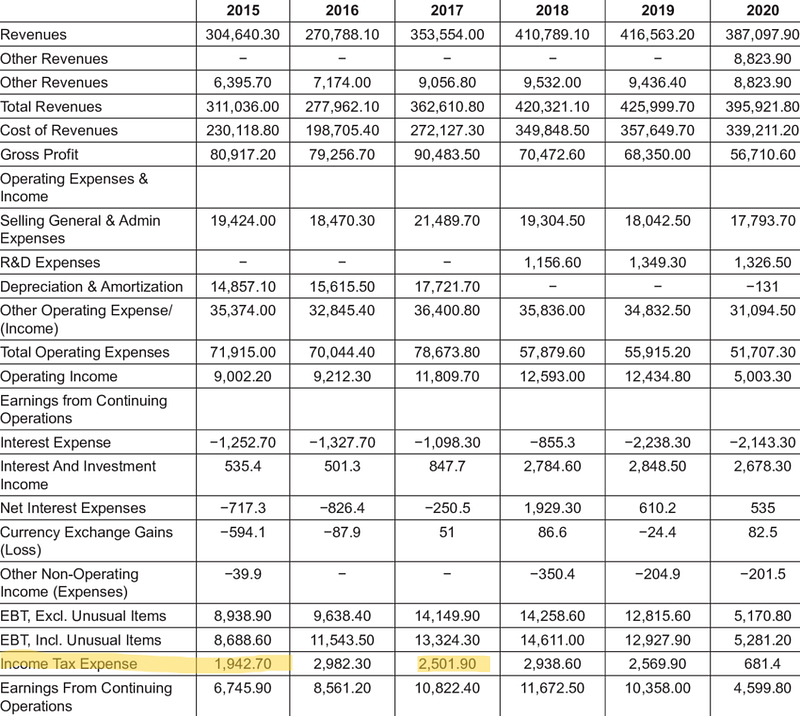
I’ll ask something related to the highlighted line:
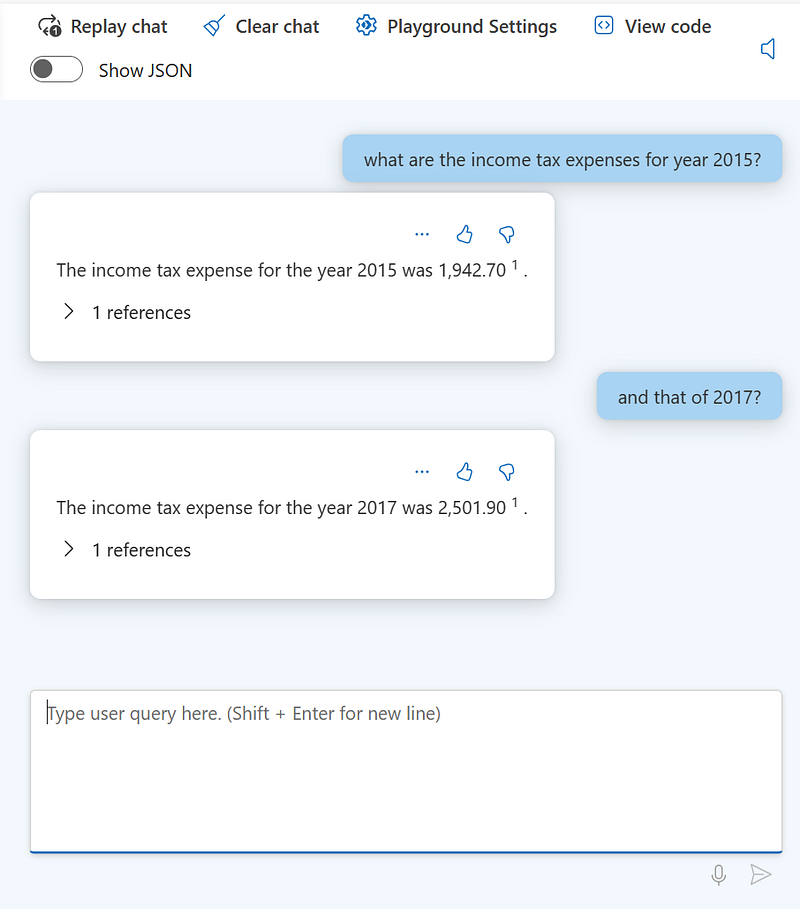
Cool! As you can see, the model was able to retrieve the embedded image with the right information. It was also able to keep the context and answer correctly to my follow up question.
Let’s see another example with the below picture:
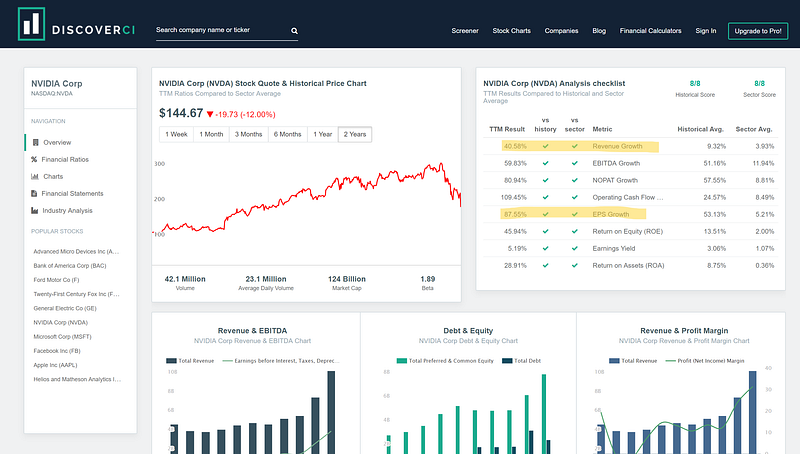
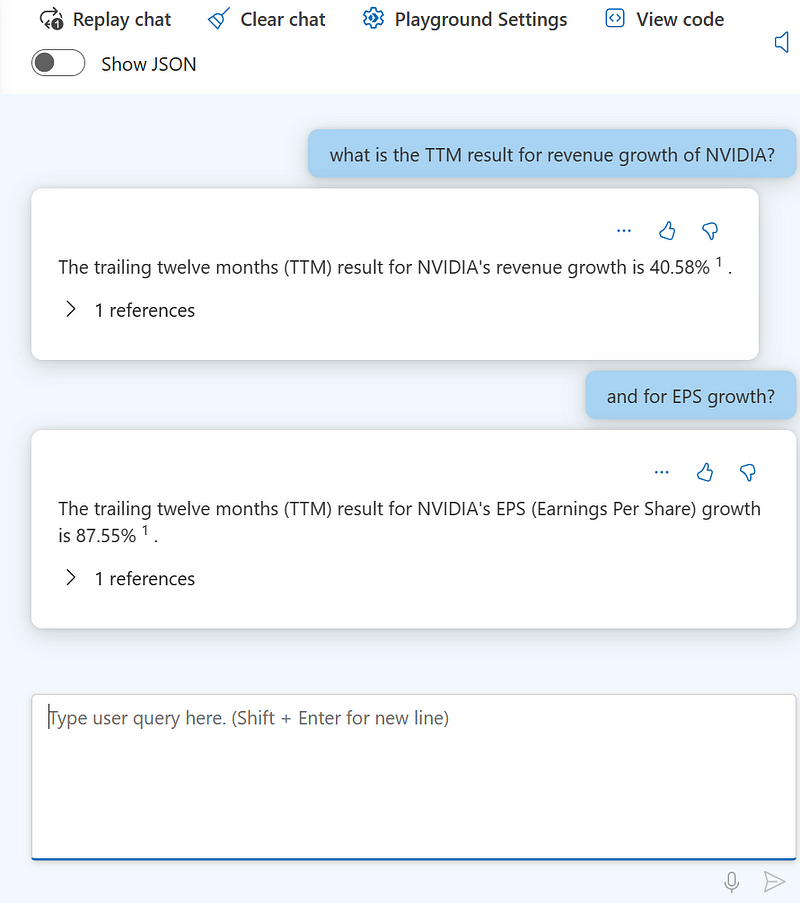
Also in this case, the model retrieved the right context. On top of that, it also explained to me what the EPS and TTM taxonomies stand for.
Finally, I’ll ask the model to generate a short article about the economy of scale of Italian banks, hoping it will refer to the below picture:
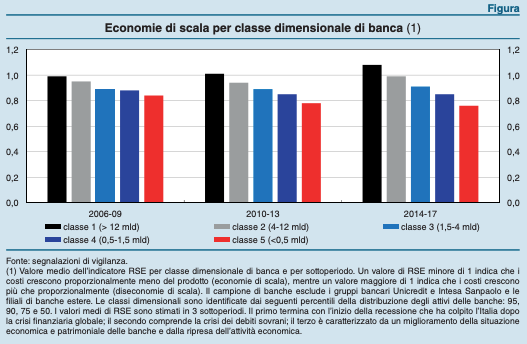
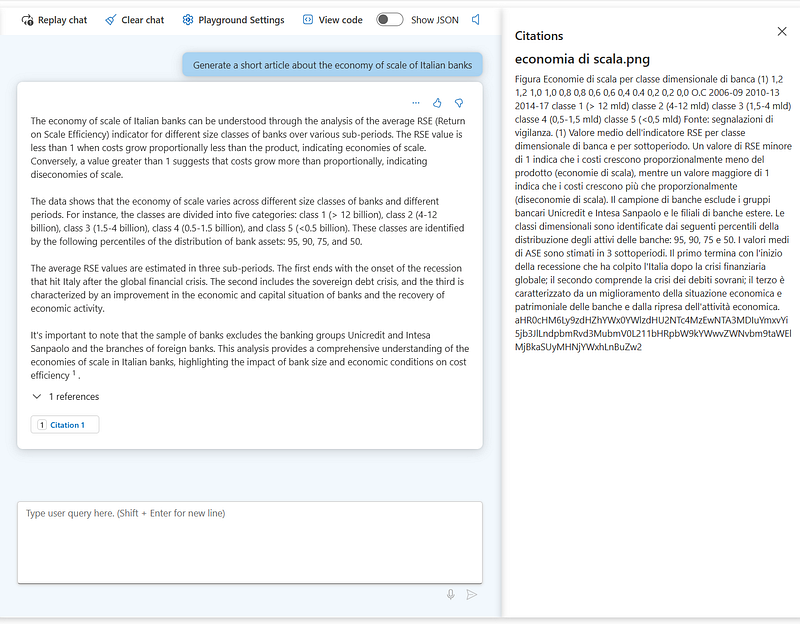
The model referenced correctly the above picture. Plus, it demonstrated it multilingual capabilities, since the picture is described in Italian.
Conclusions
MM-RAG is a further milestone in achieving the Artificial General Intelligence goal. In fact, the idea is that of extending Large Foundation Models’ (LFMs) perception beyond text.
We’ve already seen examples of Large Multimodal Model’s such as the GPT-4-vision; combining them with an external knowledge base which is multimodal, allows for multimodality in both input and output, paving the way for new powerful applications.
References
- https://www.researchgate.net/figure/Example-of-Income-Financial-Statements-Report_tbl3_346646402
- https://www.google.com/url?sa=i&url=https%3A%2F%2Fwww.discoverci.com%2Fstock-analysis&psig=AOvVaw2TfJSqneXXTGW99GsDMmqL&ust=1706215803014000&source=images&cd=vfe&opi=89978449&ved=0CBQQjhxqFwoTCLj9k6vz9oMDFQAAAAAdAAAAABAI
- AI enrichment concepts — Azure AI Search | Microsoft Learn
- https://readmedium.com/getting-started-with-multimodality-eab5f6453080



