

Getting Started with Multimodality
Understanding vision capabilities of Large Multimodal Models
The recent advances in Generative AI have enabled the development of Large Multimodal Models (LMMs) that can process and generate different types of data, such as text, images, audio, and video.
LMMs share with “standard” Large Language Models (LLMs) the capability of generalization and adaptation typical of Large Foundation Models. However, LMMs are capable of processing data that goes beyond text, including images, audio, and video.
One of the most prominent examples of large multimodal models is GPT4V(ision), the latest iteration of the Generative Pre-trained Transformer (GPT) family. GPT-4 can perform various tasks that require both natural language understanding and computer vision, such as image captioning, visual question answering, text-to-image synthesis, and image-to-text translation.
The GPT4V (along with its newer version, the GPT-4-turbo vision), has proved extraordinary capabilities, including:
- Mathematical reasoning over numerical problems:
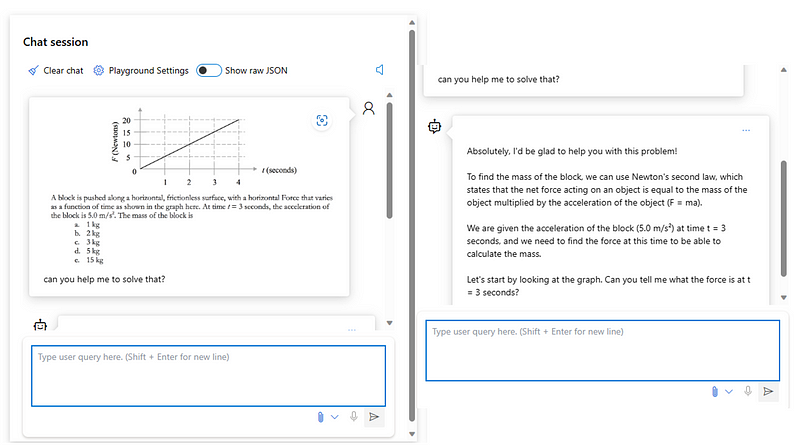
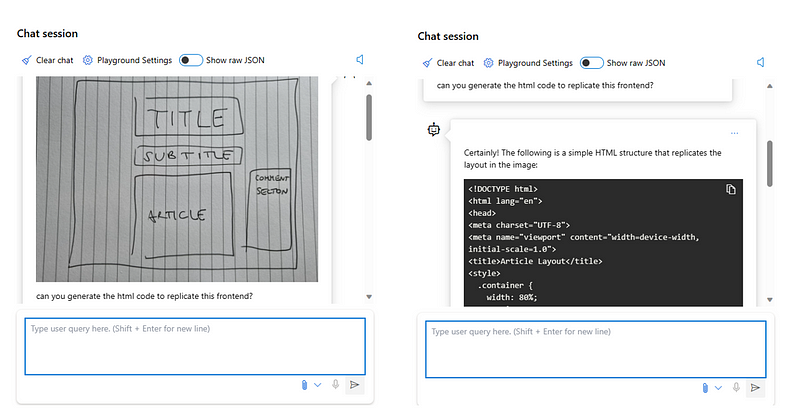
- Generating code from sketches:
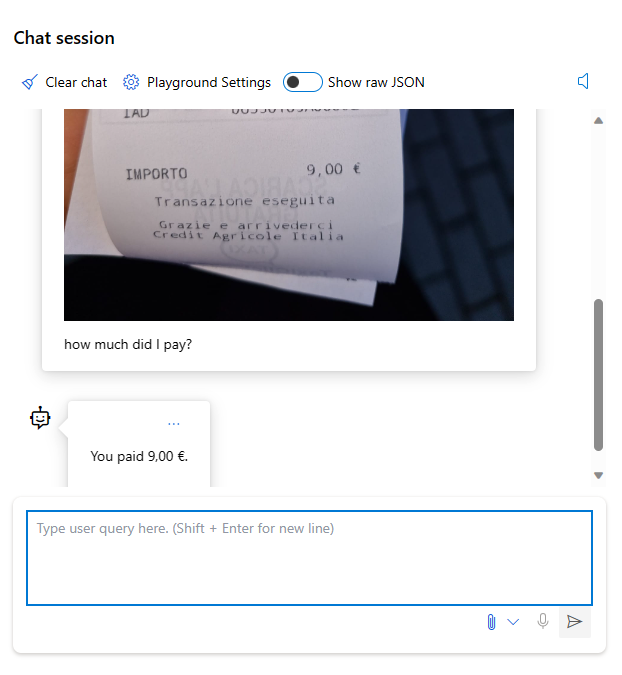
- OCR:
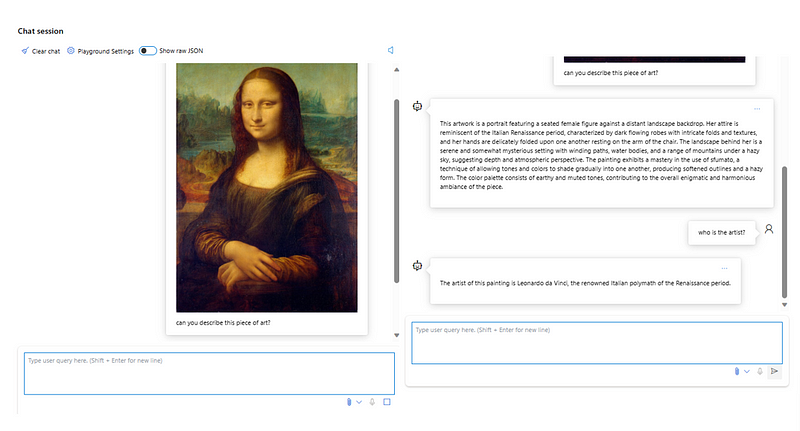
- Description of artistic heritages:
And many others.
In this article, we are going to focus on LMMs’ vision capabilities and how they differ from the standard Computer Vision algorithms.
What is Computer Vision
Computer Vision (CV) is a field of artificial intelligence (AI) that enables computers and systems to derive meaningful information from digital images, videos, and other visual inputs. It uses machine learning and neural networks to teach computers to see, observe, and understand. The goal is to mimic the human visual system, automating tasks that the human visual system can do. For example, computer vision can be used to recognize objects in an image, detect events, estimate 3D poses, and restore images.
Since CV relies on neural networks, that are nothing but mathematical model, we need to convert images into numerical input, so that they can be processed by our models.
An image is a multi-dimensional array of pixels. For a grayscale image, this is a 2D array where each pixel corresponds to a different shade of gray. For a colored image, it’s a 3D array (height, width, and color channels), where each color channel (Red, Green, Blue — RGD) has a separate 2D array of pixel intensities in that color.
Each pixel intensity is a numerical value. The most common scenario is that this value ranges from 0 (black) to 255 (white). The combination of these pixels makes up what we visually perceive as an image.
The following illustration shows an example of a RGD image (note: pixels’ values are meant for examples only and do not represent real values).
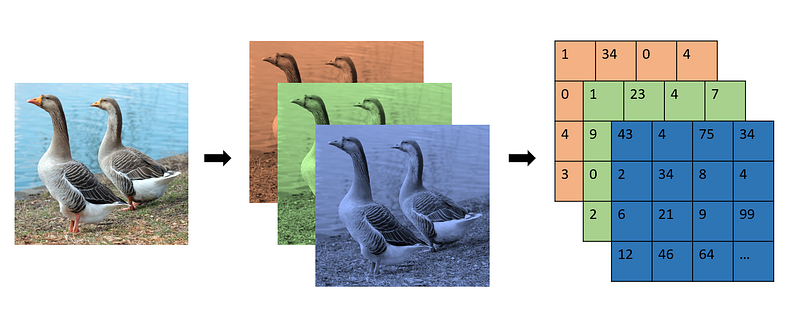
Now, the question is how to pre-process these multi-dimensional array in such a way that the CV model is able to understand them and preserve as much information as possible.
Before the emergence of multimodal models, computer vision used to rely on specialized models that were designed and trained for specific tasks, such as object detection, face recognition, scene segmentation, and optical character recognition. One of the most popular class of models in this field is that of Convolutional Neural Networks.
Convolutional Neural Networks
Convolutional Neural Networks are nothing but Neural Networks that exhibit, in at least one layer, the mathematical operation of convolution.
Convolution is an element-wise multiplication between two matrices (representing, respectively, a filter specialized in detecting specific features and an equally-sized region of the image being processed) with the final summation of the outputs.
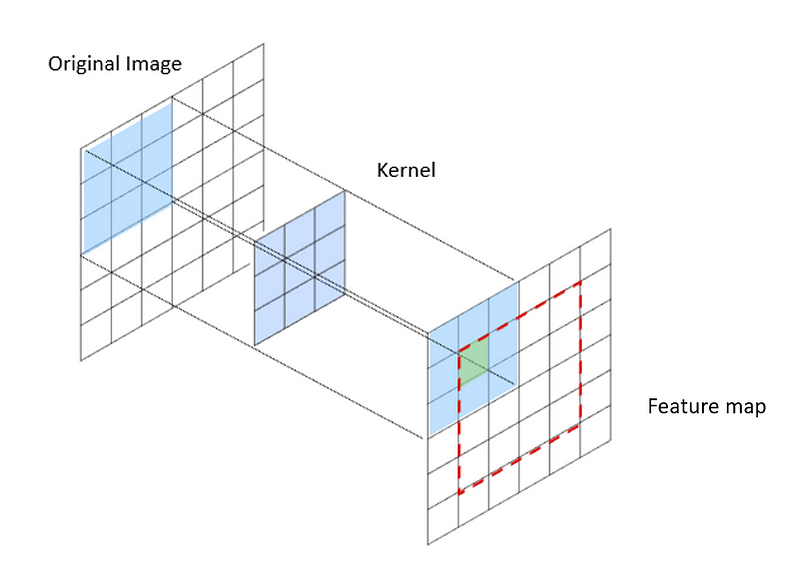
Let’s consider the following illustration as an example.
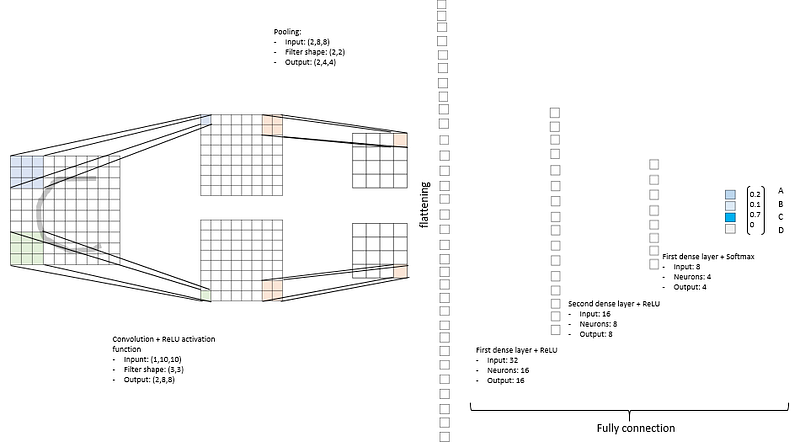
In the picture, I’ve examined an easy task: we have an alphabet of four letters — A, B, C and D — and our algorithm is asked to recognize our input letter (in our case, a ‘C’). The input image is passed through a filter specialized, for example, in corner detection, then reduced in dimensionality, flattened and processed through the fully-connected layers.
Visual Transformer
A first alternative to CNN was introduced with Vision Transformer (original paper here), that share with LLMs the core architecture (encoder/decoder).
As per traditional transformers, also in this case the core mechanism is Attention (original paper here), that allows the model to selectively focus on different parts of the input sequence when making predictions. This concept is applied by teaching the model to focus on certain parts of the input data and disregard others to better solve the task at hand.
The revolutionary aspect of attention in Transformers is that it dispenses with recurrence (read more about Recurrent Neural Networks (RNNs) here) and convolutions, which were extensively relied upon by previous models. The Transformer is the first model relying entirely on attention to compute representations of its input and output without using sequence-aligned RNNs or convolution. This allows the Transformer to capture a wider range of relationships between the words in a sentence and learn a more nuanced representation of the input.
In Vision Transformers, images are processed differently than in CNNs. In fact, an image is divided into so-called patches, typically of the size of 16x16 pixles. Then, each patch is flattened into a 1D vector and tokenized, in the same way we do with text data in a standard transformer like GPT-3.5.

Now, these tokenized patches will be fed into the Vision Tranformer model and further converted into lower-dimensional vectors via a linear projection layer, so that we can work with less memory and computational power while preserving information. Plus, as in standard transformer, each token is associated with an indicator about its position in the overall context of the image via a positional embedding layer.
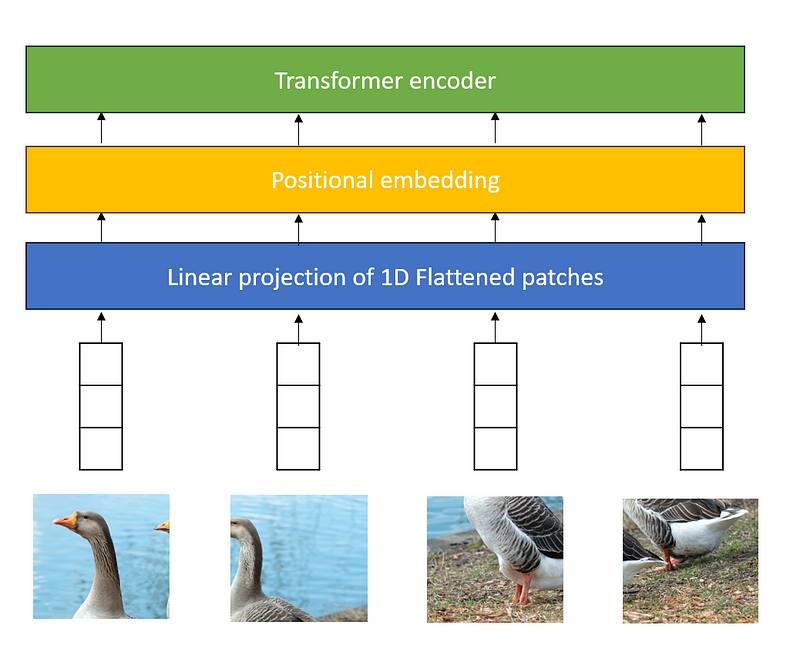
Finally, the positional-embedded tokens are passed into the main block of the model, that is the transformer encoder. Below you can see an illustration of a Vision Transformer (in this case, the scenario is a classification task):
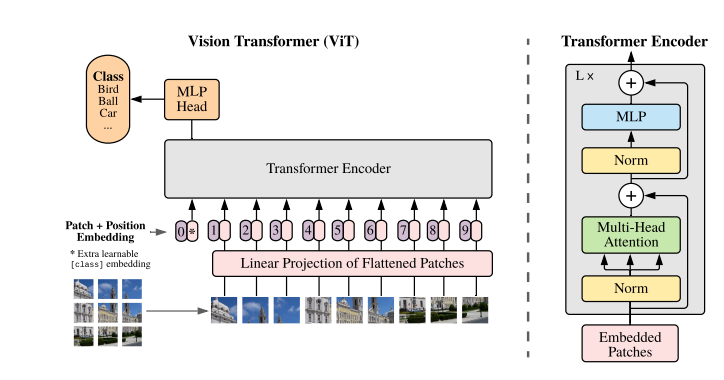
As you can see, the Transformer encoder exhibit the attention mechanism mentioned above.
Putting all together
The idea is that of projecting images’ embeddings in the same latent space as language, so that, given a human input made of image + text, the model is able to gather the relevant context from an embedding space covering both images and texts.
A first example of an image and text model was introduced by OpenAI with CLIP (Contrastive Language-Image Pretraining).
CLIP
CLIP is a model developed by OpenAI that’s designed to understand images and text together. It’s like a bridge that connects the world of images and the world of words.
Imagine you have a bunch of images and sentences, and you want to match each image with the sentence that best describes it. That’s essentially what CLIP does. It’s trained to understand which images and sentences are similar to each other.
The cool thing about CLIP is that it doesn’t need to be specifically trained on a certain task to do well at it. For example, if you have a new set of images and sentences that CLIP has never seen before (in a so-called zero-shot approach), it can still do a pretty good job at matching them up. This is because CLIP has learned a general understanding of images and text from a huge amount of data.
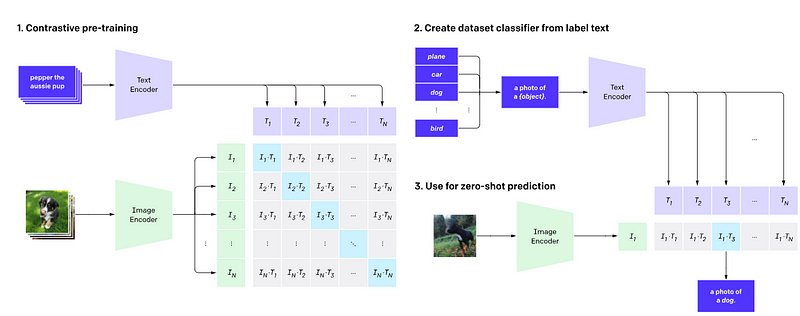
While CLIP was still a predictor model, the state-of-the-art LMMs are meant to interact with humans as AI assistant. In other words, they are instruct models.
LLaVA
A great example of an assistant LMM is the open-source model LLaVA (Large Language and Vision Assistant), that combines the above mentioned CLIP for image encoding and the base LLM Vicuna, for instruction understanding.
The idea of LLaVA is that of having a linear layer to connect image features produced by CLIP into the word embedding space of the language model Vicuna.
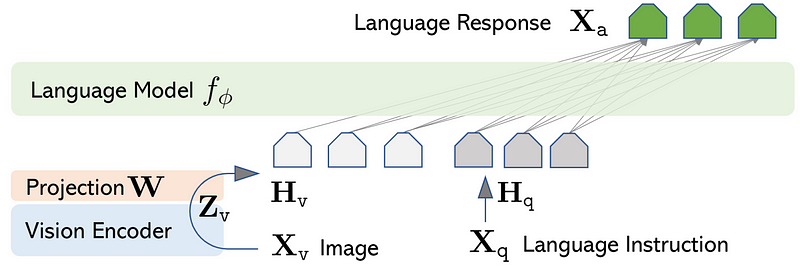
To do so, researchers introduced a trainable projection matrix W that converts image features into embedding vectors of the same dimensions as word embeddings processed by the language model.
Kosmos-1
Another example is Kosmos-1, introduced by Microsoft Research in this paper. The approach behind this model is that of having a transformer decoder that perceives general modalities in a unified way: inputs are flattened into 1D vectors of tokens and tagged with special start and end-of-sequences special tokens (texts as <s>text</s>, images as <image>image</image>). Once tokenized, inputs are encoded via embedding modules (specific per data format), then fed into the decoder.
In their paper, authors describe the training process of the model, that included the following data corpora:
- Monomodal, text corpora →used for representation learning (that is, the ability to produce meaningful representation of language, keeping the underneath semantic structure) and general purpose language tasks, such as instructions-following, in-context learning and similar.
- Image-caption pairs →needed as the bridge for the model to link images with their description
- Interleaved Image-text data →needed to further align the perception of general modalities with language models and improve model’s few-shot ability.
The below picture shows some examples of Kosmos-1 capabilities:
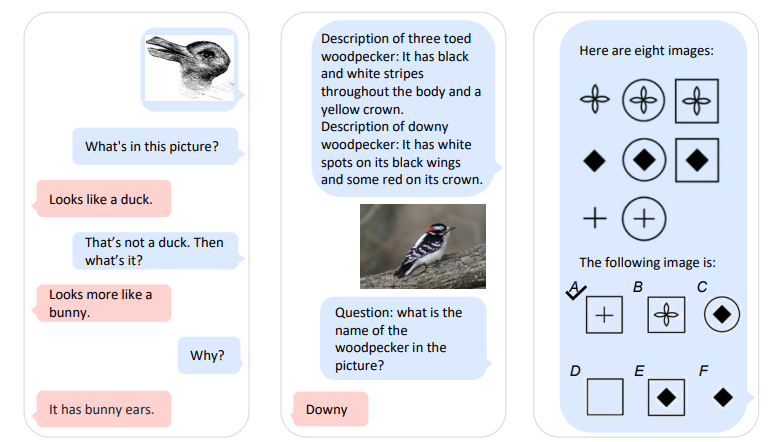
Overall, the trend of creating a common embedding space for both images and words, so that the model can “perceive” both the data formats — texts and images — is paving the way to powerful Large Multimodal Models. Plus, pre-trained models such as CLIP are being widely used to produce image representations, that can be then further converted into the word embedding space.
Beyond vision
Generally speaking, the main idea behind multimodal models is to create consistent representations of a given concept across different modalities. In the previous section, we saw how we can use a Vision Transformer to embed images into lower-dimensional vectors in a latent space. Similarly, we could create encoders for each modality and using an objective function that encourages the models to produce similar embeddings for similar data pairs.
For example, let’s consider the model MACAW-LLM, a multi-modal language model that is able to process images, video, audio, and text data, built upon the foundations of CLIP (images and video), Whisper (audio), and LLaMA (text).
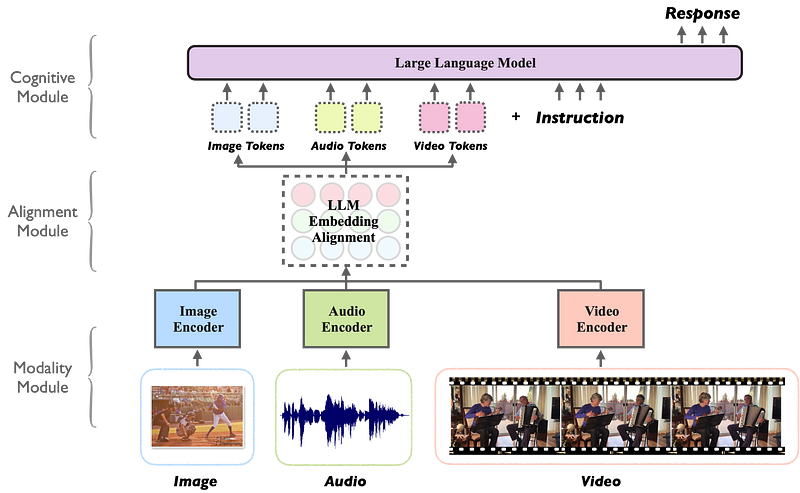
As you can see, different embedding modules are used to produce a “shared” embedding space, which is aligned with the word embedding space used by the LLM (the Meta AI’s LLaMA in this case).
Conclusions
Multi-modality is paving the way towards a new waves of applications and use cases. It is also a further milestone towards the concept of Artificial General Intelligence (AGI), since it is making AI systems more and more prone to “perceive” as humans do.
Needless to say, Large Multimodal Models come with even greater responsabilities in terms of ethical considerations: biases, discriminations, privacy violations and many others risks are at the core of LMMs’ researches, and now more than even Human Alignment is a top priority while developing AI systems.
References
- https://arxiv.org/pdf/2010.11929.pdf
- https://arxiv.org/abs/1706.03762
- https://readmedium.com/recurrent-neural-networks-97f3b034e70
- lyuchenyang/Macaw-LLM: Macaw-LLM: Multi-Modal Language Modeling with Image, Video, Audio, and Text Integration (github.com)
- 2302.14045.pdf (arxiv.org)
- CLIP: Connecting text and images (openai.com)
- https://ai.meta.com/blog/large-language-model-llama-meta-ai/
- https://openai.com/blog/introducing-superalignment
- https://openai.com/blog/our-approach-to-alignment-research





