
Recurrent Neural Networks
Neural Networks are the typical algorithm employed in Deep Learning tasks. In my previous post, I’ve been talking about the basic structure of NNs and the elements (parameters, hyperparameters, and strategies) which one should know before building a Deep Learning model.
Here, I’m going to dive deeper into the field of RNN.
The idea behind RNN is that, given a variable and its corresponding target (the value we want to predict), the output of today might affect the output of tomorrow. For those of you who are familiar with time series analysis, it might sound very similar to Autoregressive Moving Average (ARMA) models: indeed, they take into account p past values of the variable (together with q past error terms if the Moving Average component is included) to predict future outcomes of that variable:
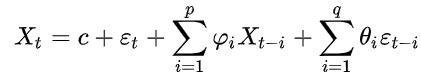
Where φ and θ are the parameters of the model.
So, RNN works with the same ground idea. However, as it is a Deep Learning algorithm, it proceeds through a loop cycle, updating and optimizing its parameters on a rolling base.
Let’s consider the following procedure:
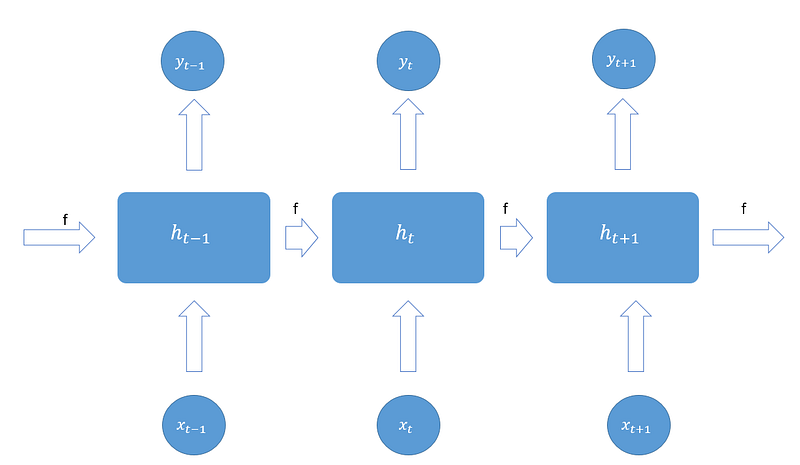
So here we have a first input at time t-1, one hidden layer and one output. However, every output at each time depends on the output of the previous period. How? Thanks to the dependency among hidden layers. Indeed, each hidden layer’s state at time t has kept traces of the previous hidden layer’s state. Hence, the hidden layer at time t is calculated as follows:
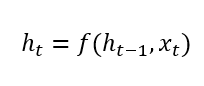
Where the function f() is one of the typical activation functions (Tanh, ReLU and so forth).
So, if we change the representation of the previous chain, we obtain something like that:
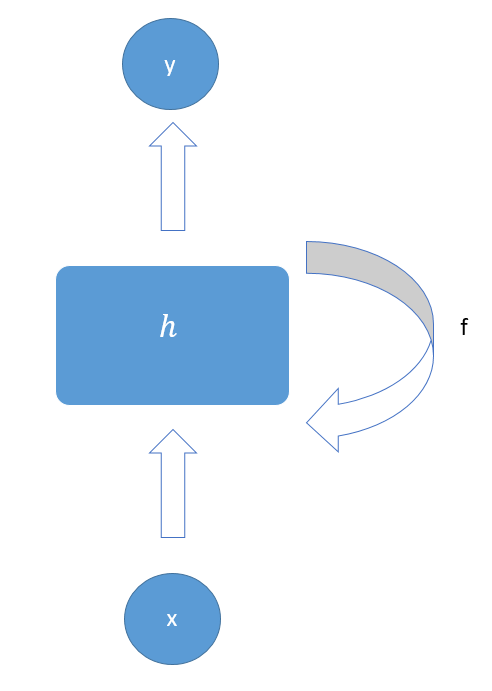
Again, the key difference between RNNs and ARMA models is that the former, like any other ML and DL algorithm, is able to tune its parameters on its own, through an optimization strategy that is based on the Gradient Descent procedure. On the other hand, ARMA models, as they being statistical models, are built through an optimization procedure (the Maximum Likelihood Estimation -MLE), but this optimization occurs once, at the very beginning, then the model can’t update itself: human intervention will be needed.
Anyway, time series analysis is not the only application nor the most popular. Among the many applications, you can think about language modeling and predictions, within the field of Natural Language Processing (NLP). The latter is the field of Artificial Intelligence which implies a deeper interpretation of data, which are provided in the form of human languages.
If you think about how your brain works while reading some pages of a book, you will easily see how the words, sentences, and pages do affect the meaning of the following ones and, since your brain knows that, it will keep them in mind while trying to extrapolate a general meaning.
That’s why RNNs are powerful tools to perform a similar task: while processing words and sentences (once vectorized), they will use the output of one processing as the input of the next processing, since the desired output (let’s say, the comprehension of a whole page so that the model can elaborate an automatic response) cannot be extrapolated only by single, independently-considered words.





