
META’s CICERO: beating humans at diplomacy
A model able to conversate, persuade and beat you in a game of trust and betrayal

Meta introduced a new model called Cicero these days. The new model had a human-like performance in a game called Diplomacy. DeepMind with AlphaGo and AlphaZero has accustomed us to models winning against the best players. Why is Cicero critical? because it is a different story? Let’s discuss it together in this article.
Diplomacy is a strategic board game created in 1954 by Allan B. Callhamer. In this game, seven players compete to control cities on the map called supply centers (SCs). The player who controls the most wins the game (alternately all players may decide on a draw, or if it is finished turns the score is tallied). What distinguishes it from typical board wargames is the negotiation phase. In fact, players spend most of their time negotiating alliances (which can also be betrayed). Negotiation is an integral part of the game and is critical to a player’s winning.
So far, reinforcement learning algorithms have been used to teach a model to learn a game and beat humans. One revolution has been the possibility that to speed up training the model can play against itself (self-play). Games such as chess, go, poker, and StarCraft are called two-player zero-sum (2p0s) settings and by having enough model capacity an artificial intelligence can learn how to excel.
“A major long-term goal for the field of artificial intelligence is to build agents that can plan, coordinate, and negotiate with humans in natural language. “ — source
However, there are games like Diplomacy where cooperation is critical to winning. the self-play approach does not work because the model might converge with a policy incompatible with human interactions (after all, the model learns to play with another artificial intelligence). In fact, previous attempts despite the model understanding the game produced a language that could not be interpreted ( and agents that worked well in 2p0s versions of a game, performed poorly when human players were present).
“An agent that can play at the level of humans in a game as strategically complex as Diplomacy is a true breakthrough for cooperative AI.” — Yann LeCun (source)
In diplomacy, it is critical that the agent is not only capable of playing the game (miscommunication leads to defeat). The messages also produced by the agent must be clear, as the player may not understand them, ask for further explanation, or cooperate against the agent with other players.
As noted further the authors:
Finally, Diplomacy is a particularly challenging domain because success requires building trust with others in an environment that encourages players not to trust anyone. Each turn’s actions occur simultaneously after non-binding, private negotiations. To succeed, an agent must account for the risk that players may not stay true to their word, or that other players may themselves doubt the honesty of the agent. For this reason, an ability to reason about the beliefs, goals, and intentions of others and an ability to persuade and build relationships through dialogue are powerful skills in Diplomacy. — source
The model
Cicero combines both a strategic reasoning module and a dialogue module (there is also a filter to eliminate low-quality messages).
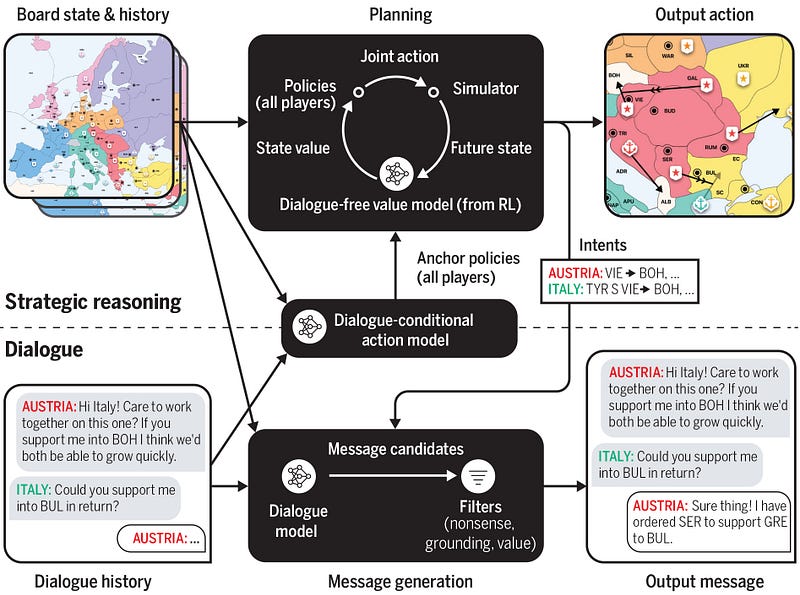
In brief:
- Dialogue, Cicero uses a pre-trained model that has been fine-tuned on Diplomacy dialogues (dialogues acquired in online matches between humans).
- Strategic reasoning, the module uses a reinforcement learning algorithm to understand the intent and actions of other players based on both the state of the game and dialogues. At the same time, it plans the next actions
- Message filtering, there are several filters to avoid using messages that are nonsensical, of poor quality, or without strategic value
Specifically, the researchers acquired a dataset of 125,000 games played online (webDiplomacy.net), containing nearly 50,000 dialogues for a total of about 13 million messages between players.
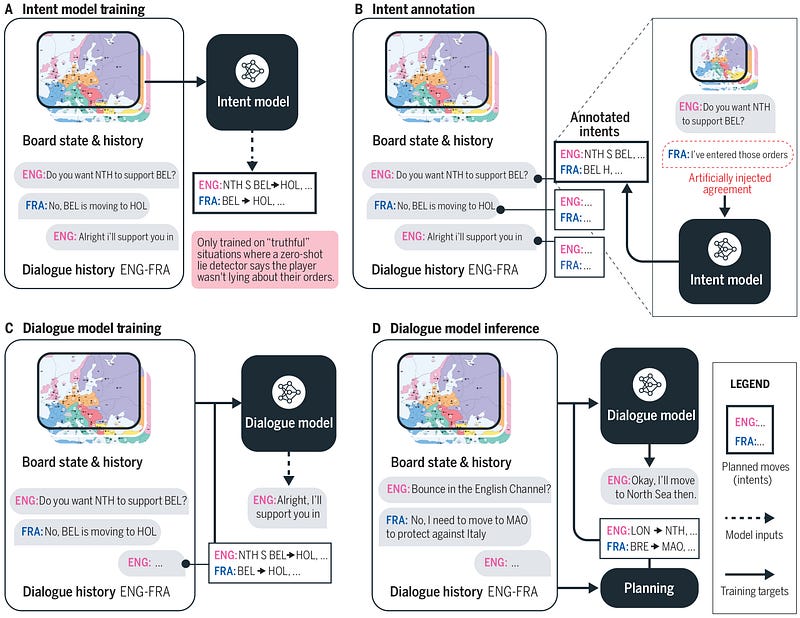
The model used for the Dialogue module is R2C2 ( a 2.7B parameter Transformer-based encoder-decoder model) which was then fine-tuned on the obtained message dataset. To prevent the model from mimicking messages between users, the researchers made the model controllable (the model generates conditional messages according to a specific plan). To do this, the messages were annotated with specific corresponding actions (actions that are related to the strategy).
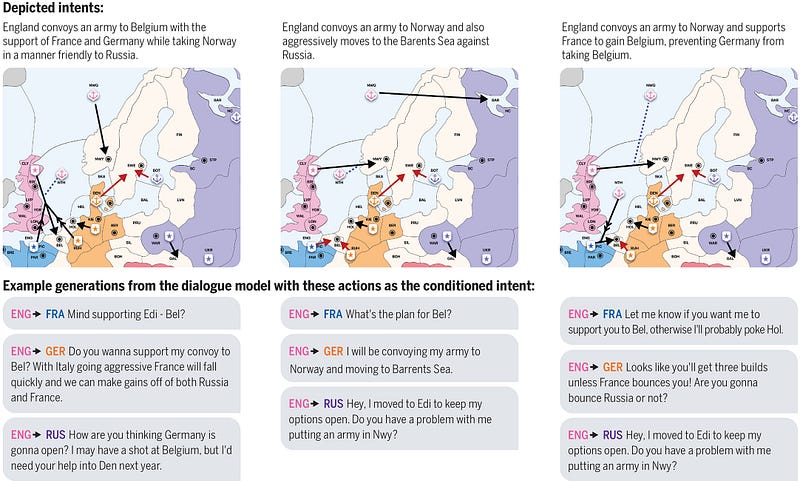
The process however is more sophisticated than it seems because a player can send a message whose content is not honest or can then change his plan. The researchers took these two aspects into account and they annotated the dataset accordingly.
The strategy module maximizes honesty and its ability to coordinate. to prevent the model from leaking information about its intentions (e.g., which territories it wanted to attack), however, mitigation strategies were used. In addition, the model was trained to select among various offers of collaborations that bring the highest expected value for itself.
The results show that the model is capable of messages that are consistent with the state of the game but also with the agent’s plan, and furthermore, these messages are considered to be of high quality by humans.
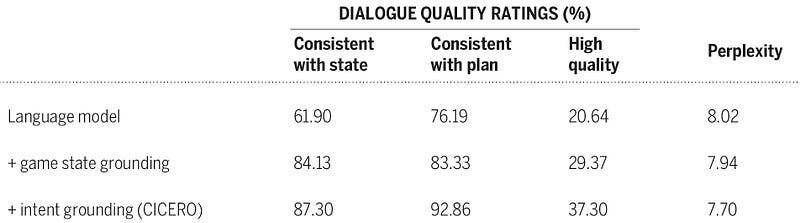
The strategy module takes into account choosing actions both the state of the game and the messages that have been exchanged. Cicero also considers what are the potential policies of other players (the model uses an iterative piKL algorithm instead of supervised learning to avoid learning spurious correlations). As shown in the article image, the algorithm uses the result of the dialogues to choose the best policy:
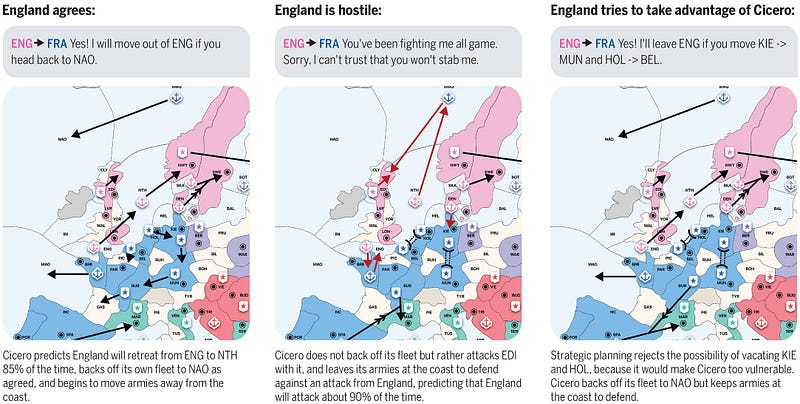
In addition, Cicero takes into account that other players might be deceptive about their plans. Not to mention that Cicero does not have access to other players’ messages, but the model also models their policies.
The researchers used Cicero in an online Diplomacy site, playing 40 games.
Cicero ranked in the top 10% of participants who played more than one game and 2 nd out of 19 participants in the league that played 5 or more games. Across all 40 games, Cicero ‘s mean score was 25.8%, more than double the average score of 12.4% of its 82 opponents. As part of the league, Cicero participated in an 8-game tournament involving 21 participants, 6 of whom played at least 5 games. Participants could play a maximum of 6 games with their rank determined by the average of their best 3 games. Cicero placed 1st in this tournament.
Different players have commented on the model:
“A lot of human players will soften their approach or they’ll start getting motivated by revenge, but Cicero never does that. It just plays the situation as it sees it. So it’s ruthless in executing to its strategy but it’s not ruthless in a way that annoys other players.” — Andrew Goff, three-time Diplomacy world champion (source)
Parting thoughts
AlphaGo has shown that it can win nimbly against a human opponent. On the other hand, an agent that is to be used in the real world must not only move pawns but also be able to negotiate, persuade, and cooperate with people (for example, if an agent is to be used for negotiations, and sales). Cicero has shown in a game of diplomacy that he can cooperate in order to win games (showing that he is among the best 10 percent of players).
Diplomacy was seen as an almost impossible game to play with an AI: the agent must not only move around the boxes but also interact and negotiate with other players using natural language. In diplomacy, an agent must take into account that the opponent may consider an attitude too aggressive to cooperate, bluff, decide to ally with others, and so on.
Cicero has managed to achieve amazing results by mastering not only natural language but strategy:
CICERO is able to speak clearly and persuasively when strategizing with other players. For example, in one demonstration game, CICERO asked one player for immediate support on one part of the board while pressing another to consider an alliance later in the game. — source

On the other hand, the model is still not perfect, showing that there are cases where it can improve. For example, in some cases, he sent nonsense messages or messages that contradicted previous ones. Although in general, most users did not realize they were playing with an AI.
No in-game messages indicated that players believed they were playing with an AI agent. One player mentioned in post-game chat a suspicion that one of Cicero’s accounts might be a bot, but this did not lead to Cicero being detected as an AI agent by other players in the league.
This pattern aside from representing another game in which AI proves capable could have other applications. Meanwhile, it provides an environment in which to study interactions in which the goals are more complex than simply choosing the best move: compromising on the short term to keep an ally, thus being able to improve one’s chances of winning.
In Perspective, the authors have made the code available so that it can be tested by the community. Similar models could revolutionize video games in which non-player characters (NPCs) could converse and plan with the human player. Meta also sees models like Cicero as pieces on the chessboard of the Metaverse, where users can negotiate, learn new skills, and be in a more immersive environment.
On the other hand, such a model poses decisive ethical issues. Such a model could impersonate other people and convince people to do something dangerous or defraud money. What do you think? Do you think it is a breakthrough or a danger? Let me know your thoughts in the comments
code: here, original article: here, official blog post: here
If you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
Or feel free to check out some of my other articles on Medium:





