
|CHATBOT | LLM | ARTIFICIAL INTELLIGENCE|
META LLaMA 2.0: the most disruptive AInimal
Meta LLaMA can reshape the chatbot and LLM usage landscape

Meta announced LLaMA2, which is not only commercially available but has outstanding performance. In this article, we find out what’s new and why it’s important
A new breed of LLaMA

First as can be seen from the announcement, LLaMA 2.0 is a collaboration between META and Microsoft, which is unusual.
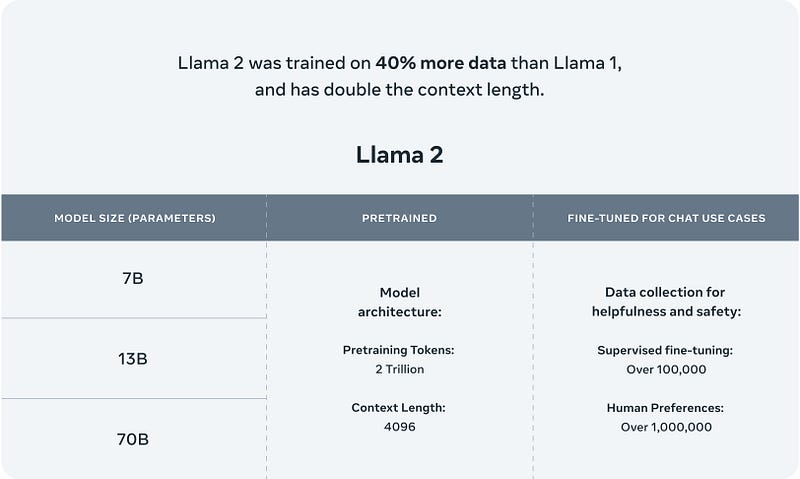
Second, the model is commercially available, can be downloaded freely, and is free to use. LLaMA 1.0, on the other hand, was only for the use of researchers and could only be used after filling out a form (then the model weights are leaked but that is another story). Third, it is trained on much more data and has better performance.
Here, I have discussed the LLaMA 1.0
and here is a summary of the news (do not worry we will discuss it in detail):
To be fair, META and Microsoft have collaborated before. In fact, they have collaborated in setting up Open Neural Network Exchange (ONNX) format, a system that allows a deep learning model to be transposed between formats. In addition, Microsoft also collaborates with PyTorch (which was a project that META bet on). Microsoft has also decided to participate to create immersive experiences for the metaverse. In addition, both META and Microsoft participate together in several initiatives.
Now, with this expanded partnership, Microsoft and Meta are supporting an open approach to provide increased access to foundational AI technologies to the benefits of businesses globally. (source)
So far, though, LLMs are one of the businesses of the future, and it was hard to imagine such a partnership on what is one of the hottest technologies. After all, Microsoft collaborates extensively with OpenAi (provided servers to train the models), invested $10 B in OpenAI, and also used OpenAI models such as ChatGPT and GPT-4. Why is Microsoft collaborating with META’s open-source answer?
Meanwhile, as we said there are not only closed-source models, but several open-source models have come out in recent months (Alpaca, Dolly, Falcon, and so on). This shows the communities are more active than ever and it is difficult to have a monopoly. Not to mention that the future of LLMs is still very uncertain and the battle is open.
Maybe, a hint here:
It’s not just Meta and Microsoft that believe in democratizing access to today’s AI models. We have a broad range of diverse supporters around the world who believe in this approach too — including companies that have given us early feedback and are excited to build new products with Llama 2, cloud providers that will include Llama 2 in their offerings for customers, research institutions who are collaborating with us on the safe and responsible deployment of large generative models, and people across tech, academia, and policy who see the benefits as we do. (source)
META must have noticed the incredible success of LLaMA. Dozens and dozens of articles citing LLaMA have been published, and many companies have decided to use it for internal products, while others have moved toward using other open-source models for models to be released publicly.
Having an open-source and available model, on the one hand, might help competitors (or at least it might seem that way). In reality, if it is much riskier for Google or OpenAI to release Bard or GPT-4 in open-source, for META the risks are much less.
First, META used only public data for LLaMA, so releasing the model has no risk of data leakage. Second, Google and OpenAI are fighting for first place in the race, LLaMA aims to be on the podium instead. While Google and OpenAI aim to have the best-performing model ever at the cost of a huge number of parameters and costs, LLaMA wants at most not to be too inferior (and LLaMA despite using the latest in technology is not aiming for any huge breakthroughs). So while the other two companies lose an advantage in releasing their model recipe, META instead assembles already-known ingredients.
Instead, the advantages are enormous. The research community is skeptical of anything that is not open-source, plus most researchers do not want to pay to use the models. LLaMA can be the hub of an active community that can experiment and create new applications. Second, LLaMA can become the community standard and thus attract more and more companies and researchers. For META it is then a no-brainer to import the published code based on their model and use it for their own internal applications.
So what about Microsoft?
As mentioned, a new open-source model comes out every month, and a standard has not yet been established. It will certainly continue to integrate ChatGPT and GPT-4 into its products, but Microsoft has a cross-sector business and could also use LLaMA (which is a much lighter family of models) in other products.
A LLaMA that is running farer

The architecture of the model is practically the same, apart from some new technical features that allow for greater context length.
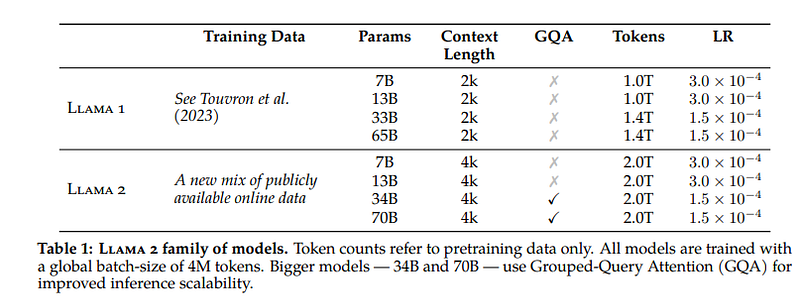
We expand the context window for Llama 2 from 2048 tokens to 4096 tokens. The longer context window enables models to process more information, which is particularly useful for supporting longer histories in chat applications, various summarization tasks, and understanding longer documents. (source)
Now as mentioned, attention has a quadratic cost and this scales with the number of tokens, so it becomes very expensive to double the context length. There are several tricks, though, to be able to succeed in enlarging the context window.
On the one hand, LLaMA 1 already used flash attention, now the authors have added Grouped-Query Attention:
For larger models, where KV cache size becomes a bottleneck, key and value projections can be shared across multiple heads without much degradation of performance (Chowdhery et al., 2022). Either the original multi-query format with a single KV projection (MQA, Shazeer, 2019) or a grouped-query attention variant with 8 KV projections (GQA, Ainslie et al., 2023) can be used. (source)
In this, the authors decided to use a greater amount of data but also an approach of greater attention to quality:
The model was trained on 40% more data than its predecessor. Al-Dahle says there were two sources of training data: data that was scraped online, and a data set fine-tuned and tweaked according to feedback from human annotators to behave in a more desirable way. The company says it did not use Meta user data in LLaMA 2, and excluded data from sites it knew had lots of personal information. (source)
Certainly, the choice of public data was made to be compatible with open-source (as mentioned in turn in LLaMA 1.0) but as the number of lawsuits over the use of data increases, it is also an astute choice to avoid ending up in court.
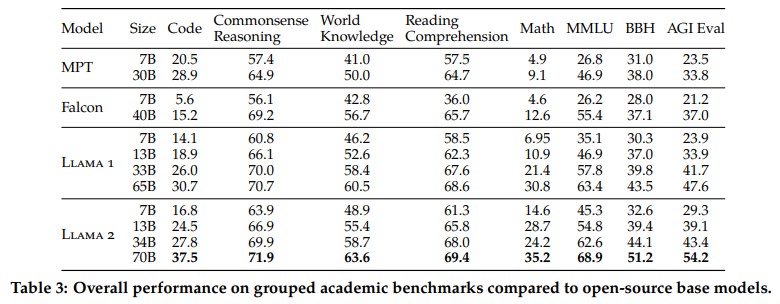
Results show that the approach used has paid off and LLaMA 2.0 is superior to open-source models published on all benchmarks.
On the other hand, LLaMA 2.0 fails to achieve results that are competitive with closed-source models (GPT-4, PalM, PalM 2)
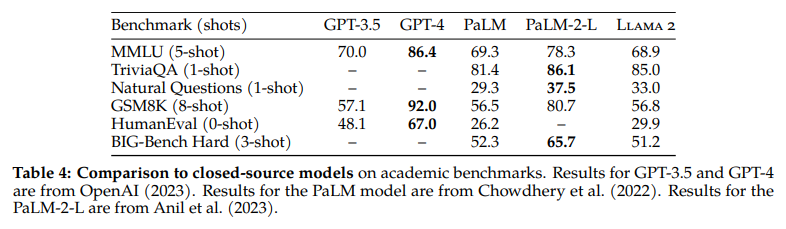
Now actually this was imaginable for a variety of reasons. These models are much fatter (PaLM is 540 B of parameters) or they are not even a single model (GPT-4 is an ensemble of models). Of other models, nothing is even known about either the training or the architecture (PaLM-2). These models have also been trained with data obtained from the Internet and private data, while LLaMA is smaller and trained only with public data.
In any case, LLaMA’s real competitors are open-source models. Moreover, META has every interest in having its models used (fine-tune, adapted for other tasks) so it has released smaller models without participating in the parameter race.
The authors also focused on the safety of the model showing that it is superior to currently available open-source models.
Getting LLaMA 2 ready to launch required a lot of tweaking to make the model safer and less likely to spew toxic falsehoods than its predecessor, Al-Dahle says. (source)
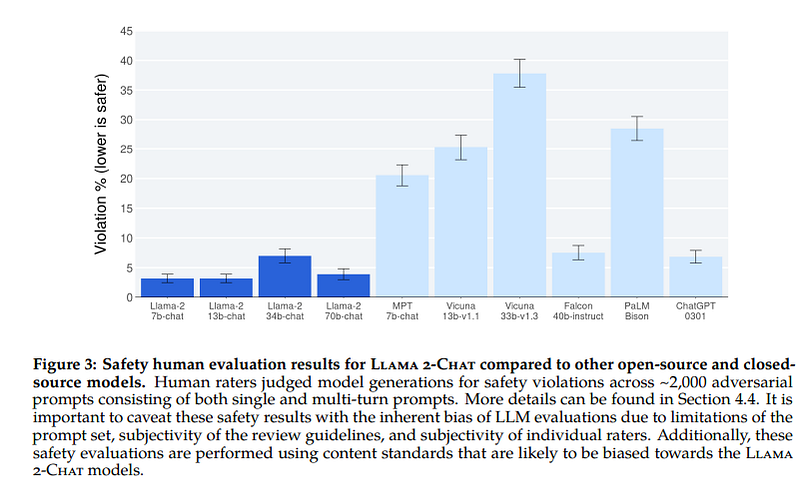
Despite that, LLaMA 2 still spews offensive, harmful, and otherwise problematic language, just like rival models. Meta says it did not remove toxic data from the data set, because leaving it in might help LLaMA 2 detect hate speech better, and removing it could risk accidentally filtering out some demographic groups. (source)
In the end, you can try to mitigate but that still remains a limitation of the transformer and thus of all derived architectures (garbage in, garbage out).
There is one advantage with LLaMa though, the community can test and inspect it in both its parameters and its behaviors, this may allow for a better understanding of where some of its bias and toxic behaviors stem from:
The fact that LLaMA 2 is an open-source model will also allow external researchers and developers to probe it for security flaws, which will make it safer than proprietary models, Al-Dahle says. (source)
An added benefit for META is to allow the community to be active in testing the limitations and proposing solutions to flaws in its model.
LLaMA 2-Chat, giving a speech to the LLaMA

Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release variants of this model with 7B, 13B, and 70B parameters as well. (source)
This is one of the most interesting new features. As mentioned some time ago, Google in an internal memo stated that the company did not have MOAT in the AI market and that open-source could win the race.
LLaMA 2.0 was designed for a very specific reason, to talk to them. As Mark said in an interview with Lex Friedman, the idea is for the model to be integrated into both Instagram and Whatsapp:
Zuckerberg: You’ll have an assistant that you can talk to in WhatsApp. I think in the future, every creator will have kind of an AI agent that can kind of act on their behalf that their fans can talk to. I want to go get to the point where every small business basically has an AI agent that people can talk to to do commerce and customer support and things like that. (source)
In fact, as seen the community has already responded and there are implementations of LLaMA chat already available (for example here or tutorials on how to use it)
Where to try it?

The model will be available through a wide network of resources:
The tool can also run directly on Windows PCs, and will be available through outside providers like Amazon Web Services and Hugging Face. (source)
and also:
We’ve collaborated with Meta to ensure smooth integration into the Hugging Face ecosystem. You can find the 12 open-access models (3 base models & 3 fine-tuned ones with the original Meta checkpoints, plus their corresponding
transformersmodels) on the Hub. (source)
HuggingFace collaborated with META, and the model can be found on the huggingFace site. In theory, you could also download it from the META site, but the fact that it is integrated into the HuggingFace ecosystem helps its use and spread.
It also appears that the model already has the top of HuggingFace’s leaderboard:
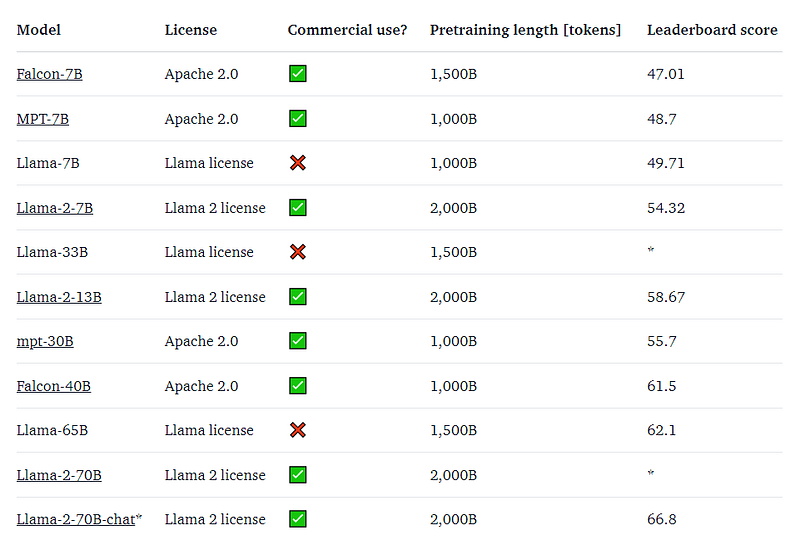
In theory, you can also try the interface on the HuggingFace site but in reality, very often it returns an error

Parting thoughts

As Yann LeCun said LLaMA 2.0 will probably have a big impact on the community.
Few companies can afford to train such models, and the fact that it is released to the public allows the possibility for many derivative applications to be born.
Meta executives say they believe public releases of technologies actually reduce safety risks by harnessing the wisdom of the crowd to identify problems and build resilience into the systems. (source)
Similar models allow researchers to explore the limitations of LLMs and also the potential biases that are present in the model. The study of risk can only be done if a model can be tested.
META plans to integrate it inside Instagram and WhatsApp although it is probably too early for it to be safely used. LLaMA is better than its predecessors but is not without bias.
Google and OpenAI also do well to care about the open-source community. Lots of groups are working and have produced lots of interesting techniques to reduce the cost of inferences and the technical requirements to be able to use a model. Models such as LLaMA 7B may soon be used on a cell phone.
Bard is a very promising model, but ChatGPT is currently more widely used. Microsoft has resurrected Bing through AI. Open-source is lurking, though. How many companies and developers will want to use models they have to pay for when they can use free alternatives?
LLaMA may not have the best performance, but it is good enough and most importantly it is not huge. It can be fine-tuned by anyone and used at any site. There are many developers who could use it to create niches and take the market away from larger companies. Also, lawsuits (even Musk launched one) and new regulations could reduce the advantage of large companies that have used non-open-source data.
The model however is not exactly open-source as revealed later but some commercial applications are restricted:
These critics highlight that Meta’s license places usage restrictions on Llama 2, excluding licensees with over 700 million active daily users (mentioned above) and restricting the use of its outputs to improve other LLMs. (source)
It is certainly better on the security side, but there are still developers who do not like all the censorship added on ChatGPT and might use other models instead of LLaMA 2.0
What do guys think? Let me know in the comments
If you have found this interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, you can become a Medium member to access all its stories (affiliate links of the platform for which I get small revenues without cost to you) and you can also connect or reach me on LinkedIn.
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
or you may be interested in one of my recent articles:
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
🔔 Follow us: Twitter | LinkedIn | Newsletter
🧠 AI Tools ⇒ Become a prompt engineer





