
Mathematical Understanding of ML Algorithms: Linear Regression (Part 1/10)
How does Linear Regression work: Mathematical Approach.
Linear Regression is a cornerstone of data science and statistics, offering a fundamental approach to predictive modeling.
This article aims to demystify the mathematical intricacies of Linear Regression, providing a comprehensive understanding of how this algorithm operates internally.
Whether you’re a budding data scientist, a curious statistician, or just someone fascinated by the world of analytics, this deep dive will equip you with a solid grasp of Linear Regression.
Introduction to Linear Regression
At its core, Linear Regression is a method used to model the linear relationship between a dependent variable and one or more independent variables.
It’s the go-to technique for scenarios where you need to predict the value of a variable based on the value of another.
The Essence of Linear Regression
- Simplicity and Versatility: Despite its simplicity, Linear Regression is incredibly versatile, applicable in fields ranging from finance to healthcare.
- Predictive Modeling: It’s primarily used for predictive modeling and forecasting, making it a valuable tool in any data analyst’s toolkit.
Fundamental Concept
Linear Regression revolves around the concept of fitting a straight line through a set of data points in a way that best expresses the relationship between those points.
The Linear Equation
The backbone of Linear Regression is the linear equation:
Y=aX+b
Here:
- Y is the dependent variable.
- X is the independent variable.
- a is the slope of the line.
- b is the y-intercept.
Understanding the Components
- Slope (a): Indicates how much Y changes for a unit change in X.
- Intercept (b): The value of Y when X is zero.
How Linear Regression Works
The process of Linear Regression involves several key steps, each crucial in developing a model that accurately represents the underlying data.
Step 1: Data Collection and Preparation
- Gathering Data: The first step is collecting relevant data that reflects the variables of interest.
- Cleaning Data: This includes handling missing values, outliers, and ensuring data quality.
Step 2: Choosing Variables
- Dependent Variable: The outcome or the target variable.
- Independent Variable(s): The predictors or features.
Step 3: Plotting the Data
- Perform EDA: Visualising the data can provide initial insights into the relationship between variables. Read here 👇
Step 4: Finding the Best Fit Line
- The crux of Linear Regression is finding the line that best fits the data points.
- This line minimizes the sum of the squared differences between the observed values and the values predicted by the model.
4.1. Mathematical Calculation: Least Squares Method
The least squares method is the mathematical technique used to find the best-fitting line.
4.1.1. The Objective
- Minimize the Residuals: The goal is to minimize the sum of the squares of the residuals (the differences between the observed values and the values predicted by the model).
4.1.2. Example Dataset
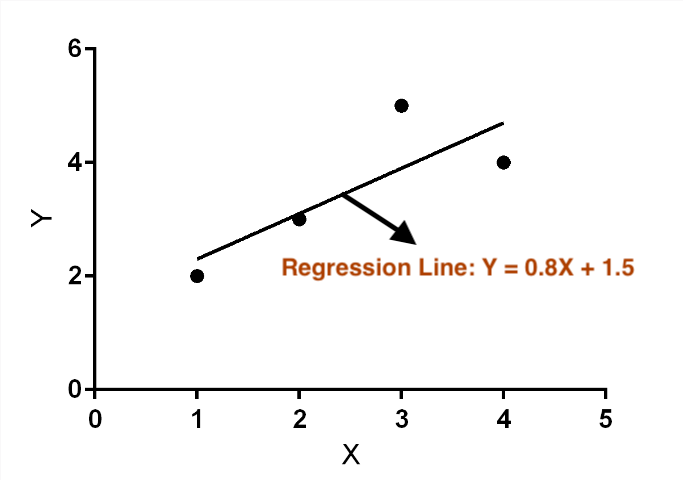
Suppose we have the following dataset of X (independent variable) and Y (dependent variable) values:
X — 1, 2, 3, 4 Y — 2, 3, 5, 4
We want to fit a linear model Y=aX+b to this data.
4.2. Steps to Calculate the Best Fit Line
4.2.1. Calculate the Necessary Sums
First, we calculate the sums of X, Y, X², XY, and the number of data points (n).
∑X = (1+2+3+4) = 10
∑Y = (2+3+5+4) = 14
∑X² = (1²+2²+3²+4²) = (1+4+9+16)= 30
∑XY = (1∗2+2∗3+3∗5+4∗4) = (2+6+15+16)= 39
n = 4
4.2.2. Apply the Formulas for a (Slope) and b (Intercept)
The formulas for the slope (a) and intercept (b) in our linear equation are:
a = (n.(∑XY) — (∑X.∑Y)) / (n.(∑X²) — (∑X)²)
b = ((∑Y.∑X²) — (∑X.∑XY)) / (n.(∑X²) — (∑X)²)
Here you may wonder, How this formula is derived, right?
This is how the formula of (“a”) is derived:

In the same manner, if you take partial derivatives of the sum of the squares w.r.t (“b”) to find the minimum. You will get the exact formula of (“b”) mentioned above.
Plugging in our sums:
a = (4∗39 − 10∗14)/(4∗30 − 10²) = (156 − 140)/(120 − 100) = 16/20 = 0.8
b = (14∗30 − 10∗39)/(4∗30 − 10²) = (420 − 390)/(120 − 100) = 30/20 = 1.5
So, our best fit line is
Y=0.8X+1.5
4.2.3. Interpretation
This line represents the best fit through our data points according to the least squares method.
It means that for every unit increase in X, Y increases by 0.8 units, and when X is 0, the value of Y is approximately 1.5.
4.2.4. Visualizing the Best Fit Line
If you plot these data points and the line Y=0.8X+1.5, you’ll see that the line passes as close as possible to all the points, minimizing the overall distance (residuals) between the line and each point.
Step 5: Evaluating Model Performance
Once the model is built, it’s crucial to evaluate its performance to ensure its predictive accuracy.
5.1. Key Metrics
- Mean Squared Error (MSE): This is the average of the squares of the errors, i.e., the average squared difference between the estimated values and the actual value. A lower MSE indicates a better fit.
- Root Mean Squared Error (RMSE): This is the square root of the MSE. It’s useful because it’s in the same units as the dependent variable, making interpretation easier.
- R-squared Value: This metric indicates the percentage of the variance in the dependent variable that is predictable from the independent variables. R-squared values range from 0 to 1, with higher values indicating a better fit.
Key Assumptions
- Linearity: The relationship between the independent and dependent variables should be linear.
- Independence: The residuals should be independent.
- Homoscedasticity: The residuals should have constant variance.
Limitations
- Oversimplification: May not capture complex relationships.
- Influence of Outliers: Can be significantly affected by outliers.
- Causality: Does not imply causation.
Advanced Variations
Linear Regression has evolved, leading to more sophisticated variations that address its limitations and extend its applicability.
Multiple Linear Regression
- Concept: Extends simple Linear Regression to include multiple independent variables. It’s used when the dependent variable is influenced by more than one factor.
- Equation: Y=a1X1+a2X2+…+anXn+b, where X1,X2,…,Xn are the independent variables.
Polynomial Regression
- Concept: A form of regression analysis in which the relationship between the independent variable and dependent variable is modeled as an nth degree polynomial. It’s useful for capturing non-linear relationships.
- Equation: Y=a1X¹+a2X²+…+an(X^n)+b.
Ridge and Lasso Regression
Ridge Regression (L2 Regularization)
- Concept: Addresses some of the problems of Ordinary Least Squares by imposing a penalty on the size of the coefficients. It’s useful to prevent overfitting and handle multicollinearity.
- Modification: Adds a penalty term equal to the square of the magnitude of the coefficients.
Lasso Regression (L1 Regularization)
- Concept: Similar to Ridge Regression but can completely eliminate the weight of less important features. It’s good for models where some features need to be selected or discarded.
- Modification: The penalty term is the absolute value of the coefficients.
Each of these variations adjusts the basic premise of Linear Regression to better model complex real-world data.
Conclusion
“Linear Regression: A simple line, a powerful story.”
Linear Regression, with its foundation in simple linear equations, offers a powerful tool for predictive modeling.
Understanding its mathematical underpinnings not only enhances your analytical skills but also provides a stepping stone to more complex machine learning algorithms.
Comment down some improvements I can make in the next upcoming parts of this series. Your feedback is much appreciated.
If you enjoy my writings, Support Me:
⭐️ My Gumroad Shop: https://codewarepam.gumroad.com/
Join my newsletter to get regular free eBooks, AI trends, and Data Science Case Studies. Subscribe now! — https://ai-codehub.beehiiv.com/
My Best-selling eBook: Top 50+ ChatGPT Personas for Custom Instructions