
Master Machine Learning And NLP Through SpaceX’s Dragon Launch And… Twitter?
An A-Z guide on how to use NLP for determining public opinion for SpaceX’s most recent launch

May 27th was supposed to mark the day when SpaceX in collaboration with NASA sent the Falcon 9 rocket to the ISS. This mission was different from all the ones before it. After almost a decade, American astronauts were to travel to space again. This became possible due to the Dragon 2 spacecraft, an upgraded model of the original Dragon developed by SpaceX.
Unfortunately, due to bad weather conditions, the launch was canceled for the said date and postponed to Saturday 30, 2020 22:22 GMT+3.
This had an incredible impact on public sentiment across social media. At the time I am writing this article (not even 3 hours after the time the launch was supposed to take place), social media have become full of users expressing their discontent with what has happened. Although the launch is going to take place, the hype created for the specific event, naturally caused anger among many avid supporters of both Elon and SpaceX, but also people in the broader scientific community.
Although exploring public sentiment after the cancellation of the event might be quite interesting, I have decided to rather concentrate on a more trivial project, which is going to entail the monitoring of public sentiment concerning the launch, during the two days that preceded it (March, 25th-March, 26th).
Announcement: After many requests, I have made a Telegram Groupchat where I will be sharing weekly trading signals for FREE. You can instantly join from THIS link.
Project Blueprint

Before being able to lay out a blueprint, a concise objective is needed.
The objective is clear, I will be building a Machine Learning model that will parse through all the tweets related to the launch (that have been posted in the last two days), and it will shed insight on what the public opinion for the mission is.
The steps I will be following are the following:
- Fetch all tweets that have been posted from May 25th to May 26th, for the keyword “SpaceX”.
- Fetch all tweets that have been posted from May 25th to May 26th, for the keyword “Crew Dragon”.
- Fetch all tweets that have been posted from May 25th to May 26th, for the keyword “Falcon 9”.
- Perform sentiment analysis on each individual tweet.
- Find the proportion of the total negative/positive/neutral tweets.
Continue reading to see how you can make your own Machine Learning NLP model!
If you are interested in more content related to Elon Musk, I have written this article which I highly recommend to all my readers:
If you like this article and are interested in receiving exclusive monthly content for free, subscribe to my exclusive mailing list at the end of this article (can be also accessed directly from here).
Performing The Analysis
The first step is to import all of the required libraries.
Now that the libraries have been imported, the tweets are to follow. As they contain different keywords, they are currently stored in three separate “.csv” files. Fortunately, pandas allows us to contact the data with relative ease.
The initial problem that can be dealt with at once, is indexing.

With only a glance, it becomes apparent that there are multiple issues that must be addressed before being able to use the data. These problems can be summed up as the following:
- Too many columns we do not need.
- Special Characters are present.
- Other-than-English languages are also present.
The first problem is undeniably the easiest to tackle. By using pandas’s multitude of functionalities, the “drop” function will be used to remove all unwanted columns.

The dataset now consists of a single column that contains the text of each tweet.
Cleaning the Data
The cleaning of the tweets is a bit more complex, but it can be done by running the following code:

As a result, the values of the dataset can now be read by a model. Before doing so though, there is one more thing that needs to be addressed. By including multiple languages, it becomes impossible for the NLP classifier to present valid results.
Thus, the model should only select the inputs that are written in English. There are multiple ways through which such a language classification could take place. A simple example is the following:

As you can see, the model is able to classify which tweets are not written in the English language and successfully discards them (even if the model detects a wrong language, it is of no importance as it detects that it is not English).
The cleaning of the data has now been completed and the deployment of the model is in order.

Getting the Sentiment Score for each tweet
In order to get the sentiment score for each tweet, the creation of two novel columns is required. The first column is “Subjectivity” and the second column is “Polarity”.

We now have the Subjectivity and Polarity of each tweet! In order for this to make any sense, I will be creating a word cloud containing key-words.

Nothing we would not expect. All of the words are words directly connected with our project.
As of now, the sentiment data are in a difficult to read and comprehend form. To change this, a new column will be created called “Analysis” and it will store the interpretation of the sentiment scores in order to make it more readable for the shake of analysis.

It becomes apparent that such a format is more efficient and comprehensive than using the latter.
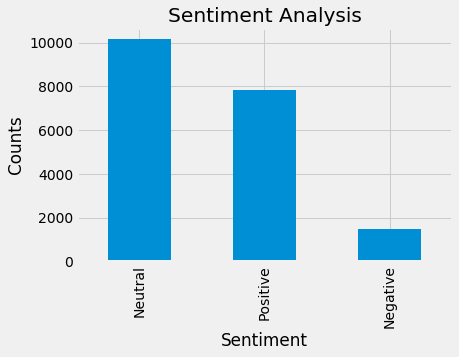
Let’s now see the distribution of the three sentiments across the tweets!
Out of the 19,474 tweets, 40.2% were positive, 7.6% were negative, and the rest were neutral.
This is equivalent to:
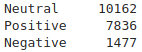
Voila! We have achieved our goal. Nevertheless, graphical representation is always welcome, so I will be plotting the data with a bars-chart.
Do you want to learn more?
If you want to advance your knowledge and are interested in making money using Machine Learning I highly encourage you to follow me and read the articles listed below:





