
Lumiere: A Space-Time Diffusion Model for Video Generation
With the release of Dalle-2 and Midjourney, we pretty much solved the Text-to-Image problem, there are a few minor things here and there, but more or so, we are there, the place where even AI experts can get fooled. So, the logical next step is to have Text-to-Video. In today’s blog, we are going to explore this topic in-depth, adding one more dimension of time really increases the complexity, because now we even have to think about temporal consistency. Text-to-video generation has been the goal of the Computer Vision community for a while, but we should be really cautious about releasing such a model in public, this could have a massive impact on elections, and other illegal adult content.
Table of Contents:
- Introduction
- Text-to-Video Applications
- Problems in Video Generation
- Space-Time U-Net
- Other Important Aspects
Are you looking for AI content that’s both original and insightful instead of repetitive and copy-pasted content? Want to delve deeper into the technological aspects rather than skimming through surface-level tips and tricks? Discover the AIGuys Digest Newsletter.
And if you want to up your AI game, please check my new book on AI, which covers a lot of AI optimizations and hands-on code:
Introduction
Lumiere — is a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse, and coherent motion — a pivotal challenge in video synthesis. To achieve this, it introduces a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution — an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales.
Text-to-Video Applications
Text-to-video can be adapted into a lot of different use cases, and here are a few of them.
Text-to-Video: We give a simple text as a prompt and this creates a small video out of it.

Image-to-Video: Here we give an image as an initial prompt, now this image could be a real one or an AI-generated one doesn’t matter.

The next one we have is called Stylized Generation. Here we give a stylized image and based on that a small video is created.

But here’s an interesting bit, based on the style of the reference image. We get very different styled videos. For instance, when we give the image of water color tree, we get the video where colors are filled as animation. Whereas in other images, it is colored from the beginning and the video is more about the movement of the object. This is a very nice small detail, that we can give the exact same objects drawn in different styles and the video will automatically adapt to a different style.
Why stop at the Stylized generation, why not Video Stylization?

I don’t think that I need to explain what are the differences in all of the different use cases. So, we are just going to provide different GIFs only.
Next, we have Cinemagraphs, here we animate a part of the image based on the user-selected region.

I’m sure that all of you have heard about AI Inpaiting, what about some Video Inpaiting?

And finally, we have Stylized Inpainting.

Given above are all the different use cases of this technology, this work enables novice users to generate visual content creatively and flexibly. However, there is a risk of misuse for creating fake or harmful content with this kind of technology, and it is crucial to develop and apply tools for detecting biases and malicious use cases in order to ensure a safe and fair use.
Problems in video generation
If we talk about other Text-to-Video methods, they synthesize distant keyframes followed by temporal super-resolution — an approach that inherently makes global temporal consistency difficult to achieve. Contrary to the existing method, Lumiere uses both spatial and (importantly) temporal down- and up-sampling, and leveraging a pre-trained text-to-image diffusion model (DALLE-2 or Stable Diffusion), it learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales.
First, let’s try to understand the problem in more detail.

When discussing the efficiency and effectiveness of current Text-to-Video (T2V) models, a significant methodology that surfaces is the implementation of a cascaded framework. This method involves a two-step process where initially, a base model is responsible for creating a sparse set of keyframes. These keyframes act as pivotal points in the video, outlining the primary movements or changes. Following this, Temporal Super-Resolution (TSR) models come into play, filling in the gaps between these keyframes by generating the intermediate frames. This approach is designed to be memory efficient, leveraging the idea that not every frame needs to be generated from scratch, but rather can be interpolated from significant moments.
However, this method encounters several challenges that limit its ability to produce videos with seamless and coherent motion.
Firstly, the base model’s generation of sparsely distributed keyframes can lead to a loss of detail in fast-moving sequences. Since these keyframes are substantially subsampled, rapid motions can become temporally aliased, meaning that the motion’s speed or direction becomes unclear or misrepresented. As a result, the intended motion can become ambiguous when only a limited number of frames are used to represent it.
Secondly, the TSR models operate within narrowly defined temporal contexts. These models are tasked with generating frames in between the keyframes, but their scope is limited to short segments of the video without overlap. This localized focus means that TSR models may not have enough context to accurately interpolate motion over longer sequences, particularly for actions that involve consistent, repetitive movements like walking. In these instances, the model’s limited perspective can result in inconsistencies or inaccuracies in the generated motion, as it cannot fully grasp the motion’s periodic nature across the entire video.
This inconsistency is shown in the below image. So the bottom row is basically one row of the image (on pixel) distributed across a time interval. We see that in the previous method, there is only consistency within keyframes, not across keyframes, this changes in the Lumiere, where there is more consistency between within KeyFrame and across KeyFrame.
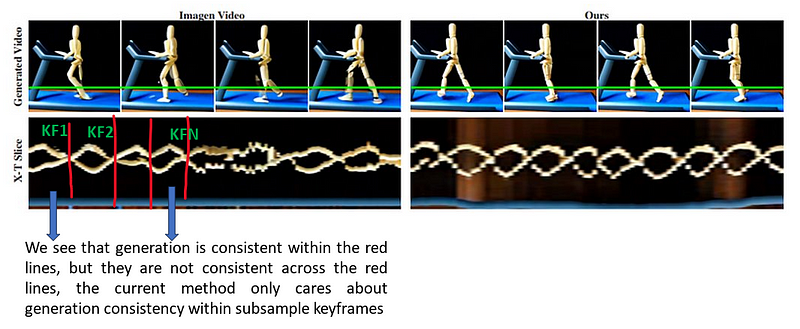
Lastly, the cascaded approach suffers from what’s termed a domain gap during training and inference. In training, TSR models are often fine-tuned using real video frames that have been purposefully downsampled. However, during inference — when these models are applied to generate new frames — the input comes from the base model’s generated keyframes, which may not perfectly align with real video data. This discrepancy can lead to compounded errors as the TSR models attempt to interpolate frames based on potentially inaccurate or unrealistic keyframe inputs, diverging further from the motion’s true dynamics.
Space-Time U-Net (STUNet)
Space-Time U-Net (STUNet) architecture learns to downsample the signal in both space and time, and performs the majority of its computation in a compact space-time representation. This approach allows to generate 80 frames at 16fps (or 5 seconds, which is longer than the average shot duration in most media.
Lumiere uses Google’s T2I (Text-to-Image) model called Imagen for T2V (Text-to-Video). Read more about Imagen here:
I know it’s a bit confusing to wrap your head around this STUNet, it’s different than a normal UNet in two ways. Normal UNet takes a 3D tensor and Normal UNet doesn’t have any T2I embeddings.
So, to make sense of this, just imagine that our video has only 3 frames, and instead of thinking of RGB frames, let’s say our video has greyscale frames, now this would be similar to an RGB image, but instead of having R, G, B channels here, we will have frame at time T1, T2 and T3.
Inflation block
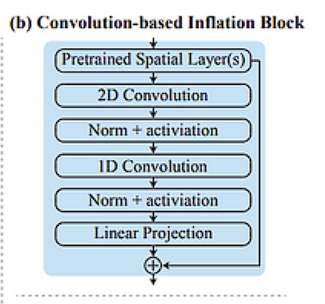
Let’s assume a simple example with specific parameters to understand what happens at each stage of the Convolution-based Inflation Block when processing three grayscale frames (T1, T2, T3):
- Input Frames: Each frame is grayscale with a spatial dimension of
HXW. Since there are three frames, let’s represent our input tensor as3xHxw
2. 2D Convolution: Assume we apply Nfilters of 2D convolution to each frame independently. If we use padding to maintain the spatial dimensions, each frame will now be transformed into an NXHXW tensor. Since we have 3 frames, at this point, our tensor would be 3xNxHxW.
3. Normalization + Activation: These layers don’t change the spatial or temporal dimensions, so our tensor remains 3xNxHxW.
4. 1D Convolution: This is applied across the temporal dimension (the 3 frames). Let’s say we use M filters for the 1D convolution. The output tensor will combine information across the three frames. If we again assume that padding is used to maintain the temporal dimension, the tensor after this stage will be MxHxW.
5. Further Normalization + Activation: These also do not change the tensor size, so it remains MxHxW.
6. Linear Projection: Let’s assume the linear projection reduces the number of features (M filters) to some number P to match the network’s expected structure at the next layer. This layer could also potentially reduce spatial dimensions through methods like striding or pooling, but for simplicity, let’s say it only changes depth. The tensor is now PxHxW.
Putting it all together, after the Convolution-based Inflation Block, you have a tensor where:
- The spatial dimensions HxWhave been preserved.
- The temporal dimension that originally had 3 frames has been encoded into the depth P through the process of 1D convolution and linear projection.
If we had to assign arbitrary numbers to make this more concrete:
- Input size: 3x100x100(3 frames, each 100x100 pixels)
- After 2D convolution with N=16 filters: 3x16xHxW
- After 1D convolution across the temporal dimension with M=32 filters: 32x100x100
- After linear projection to P=64 filters: 64x100x100
The output tensor’s dimension reflects a compressed representation of both the spatial and temporal information suitable for processing by the subsequent layers of STUNet.
The information from the pretrained T2I layers is infused at each stage of the block, ensuring that the spatial features generated are aligned with the text description. The fixed pretrained layers provide a rich set of features that the model leverages to generate the final output, while the rest of the network refines these features to produce coherent video frames.
Now let’s look at the overall structure of STUNet.
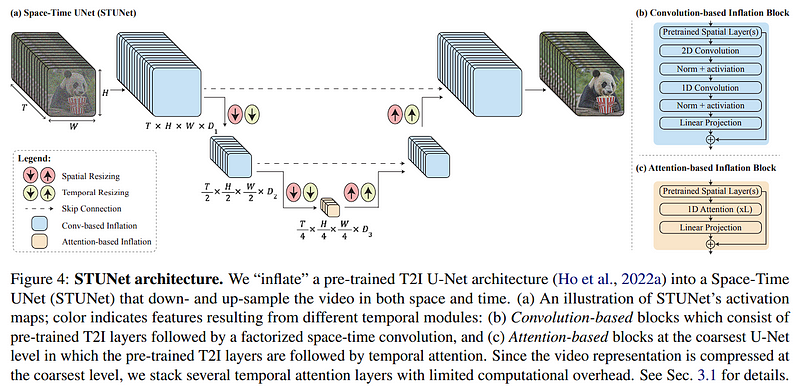
1. Input and Initial Processing: — The input is a grayscale video with 3 frames. — The video is downsampled both spatially and temporally to reduce resolution and number of frames, respectively.
2. STUNet Layers and T2I Embedding Integration: Convolution-based Inflation Blocks: — Applied at each downsampling layer, which includes 2D convolutions on spatial dimensions and 1D convolutions across the temporal dimension. — After convolutions, T2I embeddings are integrated. These embeddings, derived from the textual description, are used to condition the convolution outputs, ensuring that the generated frames will align with the text content.
Attention-based Inflation Blocks: — Utilized at the coarsest downsampling level, where the video data is most compressed. — 1D temporal attention mechanisms selectively focus on important features over time. — Here, T2I embeddings play a crucial role in guiding the attention mechanism to focus on semantically relevant temporal features as indicated by the text.
3. Skip Connections: — Skip connections carry high-resolution spatial information from each downsampling layer to the corresponding upsampling layer, preserving details that might otherwise be lost.
4. Upsampling and Final Generation: — The video is then upsampled, reversing the downsampling process. — T2I embeddings continue to condition the process, ensuring that as the resolution is increased, the added details are consistent with the textual description. — The final output is a denoised grayscale video with 3 frames, where the motion and content have been refined to reflect the text input.
Throughout the STUNet architecture, the T2I embeddings are a constant presence at each layer, influencing the generation of video frames so that the final output not only has coherent motion and spatial detail but also accurately represents the described scene. This ensures the video is not just a random assembly of frames but a meaningful sequence that corresponds to the text description, such as “a cat playing with a ball.”
Other Important Aspects
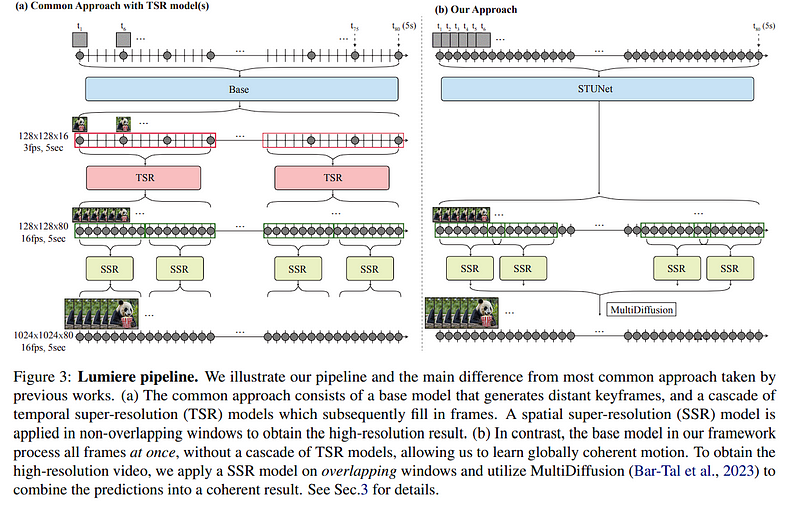
The most important thing to note from the above diagram is that the STUNet doesn’t generate a big-scale output. In fact, it is generating 128x128 sized output, after that step we need to apply Spatial superresolution (SSR) model, this model converts the STUNet output image from 128x128 -> 1024x1024 , but it is slightly different than the traditional T2V techniques, it uses overlapping windows to keep temporal consistency unlike the SSR applied between KeyFrames of the traditional techniques.
In the paper, this is called MultiDiffusion for Spatial Super Resolution.
Stylized Generation
Recall that we only train the newly-added temporal layers and keep the pre-trained T2I weights fixed. Previous work showed that substituting the T2I weights with a model customized for a specific style allows to generate videos with the desired style.
But it was observed that this simple “plug-and-play” approach often results in distorted or static videos (see SM), and hypothesize that this is caused by the significant deviation in the distribution of the input to the temporal layers from the fine-tuned spatial layers.
In the paper they opted to strike a balance between style and motion by linearly interpolating between the fine-tuned T2I weights, Wstyle, and the original T2I weights, Worig. Specifically, we construct the interpolated weights as w_interpolate = alpha x W_stlye + (1-alpha) x W_orig. The interpolation coefficient alpha ∈ [0.5, 1] is chosen manually in our experiments to generate videos that adhere to the style and depict plausible motion.
Conditional Generation
In simple terms, conditional generation refers to creating videos based on additional inputs besides just the text prompt. Here’s how it works:
1. Noisy Video (J): This is the video you start with, and it’s got some intentional noise added to it. Think of it as a rough draft of the video you want to create.
2. Masked Conditioning Video (C): This is another version of the video where certain parts you want to change are covered up (masked). It’s like having a video with stickers placed over the bits you want to update.
3. Binary Mask (M): This is a simple guide that tells the model exactly where those stickers (masks) are. It’s a black and white video where the white parts show where the masks are.
4. Text Prompt: This is the description in words of what you want the video to show.
5. Input Tensor: To make the magic happen, the model takes all these inputs — J, C, M, and the text prompt — and sticks them together into one big bundle of information. This bundle has all the details the model needs to know what parts of the video to keep and what to animate or change.
6. Model Adjustment: The model’s first layer is adjusted to handle this big bundle of inputs by expanding its capacity.
7. Fine-tuning: The model is then fine-tuned, which means it’s trained to clean up the noisy video (J) using the information from the clean, masked video (C) and the binary mask (M). This training process teaches the model to keep the good parts of the video untouched (as shown in C) and only add motion to the parts that were covered by the masks (as indicated by M).
In essence, the model learns to make a new video by keeping the unmasked parts unchanged and adding animation only where you want changes, according to the text description. This way, you can have a video that keeps certain elements static while animating others, creating a custom video based on your specific needs.
There are a few other similar parts given in the paper. Please read, the original paper to know these small details.
Writing such articles is very time-consuming; show some love and respect by clapping and sharing the article. Please support good AI content beyond Hype. Happy learning ❤
Please don’t forget to subscribe to AIGuys Digest Newsletter




