
LLM’s for Enterprises: Why Bigger isn't Always Better?
To drive optimal results on your private data go Deeper than Bigger. Experimentation shows that you can get better results with LLM’s 100x smaller.
By this point, you must have attempted to utilize LLM with your private enterprise data. After initially obtaining intriguing results by assembling boxes and engaging in API-level engineering for (as illustrated in the previous blog about RAG- Retrieval Augmented Generation), the harsh reality sets in that achieving an acceptable level of accuracy with your enterprise data is far more complex than initially perceived.
To optimize your generative AI output, one must concentrate on data and feature engineering, fine-tuning, instructing the database, implementing a human feedback mechanism, and establishing a reward model. These steps necessitate a solid understanding of Data Science fundamentals, and I will address each of them individually. However, before delving into those topics, we must dispel a major misconception. It seems that everyone is fixated on the size of the LLM. However, for an enterprise AI team, the model’s size is an incorrect aspect to focus on. My team has conducted extensive experimentation and research on this matter, and we will soon publish a paper outlining our detailed findings. In summary, what we have learned is that emphasizing the parameter size of the models is misguided when identifying the elements that should truly receive attention instead.
Let me start by drawing a corollary to wisdom often used in military strategy.
Successful generals focus on the strength of the supply chain than on the size of the military. Good data scientists focus on the strength of the ML pipeline than the size of the model.
OpenAI — Instruct DB
Given that OpenAI was instrumental in making LLMs what it is today, it would make sense to highlight their paper first.
OpenAI evaluated various tasks with their GPT3–175B model, then compared the baseline to the 1.3B model with SFT (Supervised Fine Tuning) and then the 1.3B model with RLHF (Reinforcement Learning with Human Feedback).
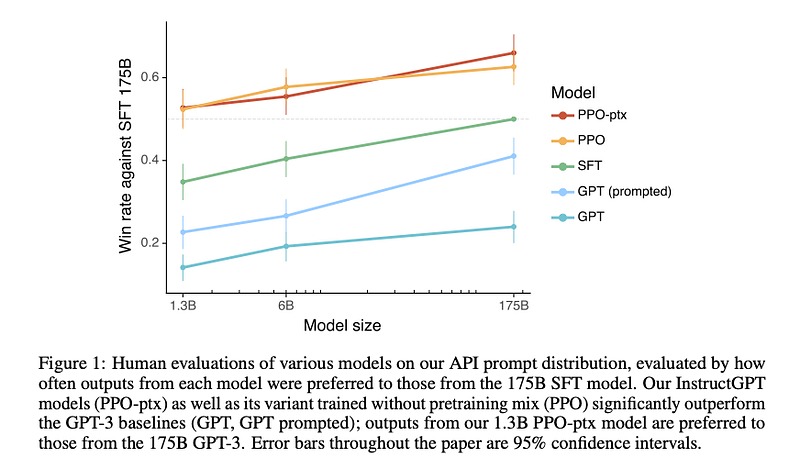
The results as shown above definitely show improvement as size goes up. But even at 1.3B parameters, the Instruct Model outperforms the 175B parameters model, with almost 100x gain in performance.
So the first moral of the story is that the quality of InstructDB is much more important than the model size.
Logically, it makes sense that a machine lacks the ability to distinguish between what is relevant and what is not in terms of generating human-like text. Achieving alignment with human requests is best accomplished by supplementing it with human feedback.
Now, the process of achieving alignment with instructDB-based fine-tuning for enterprise LLMs poses a complex challenge. I have been working on this for the past few weeks and will outline the architecture in the next blog post. However, it is crucial to emphasize the significant impact it has on the success of OpenAI GPT models, outweighing the focus on model size.
IBM Research on Self-Align Mechanism
IBM has published a recent paper on a new method to capture & reinforce human feedback than RLHF used by OpenAI.
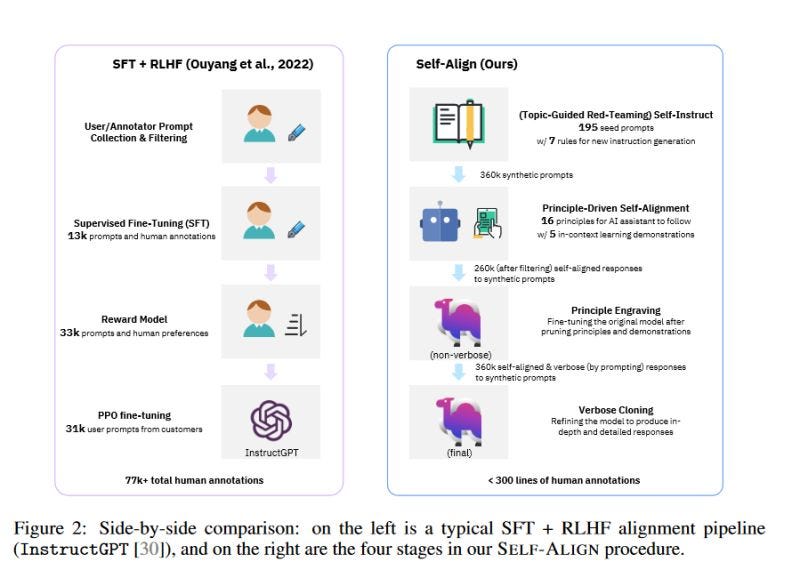
Currently, cutting-edge AI systems heavily rely on supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) to achieve their capabilities. However, the success of these methods hinges on extensive human supervision, which not only incurs high costs but also introduces potential issues such as annotation quality, reliability, diversity, creativity, self-consistency, and undesirable biases.
To overcome the challenges posed by intensive human annotations in aligning language models (LLMs), IBM Research introduced a groundbreaking approach called SELF-ALIGN. This innovative method minimizes the need for human supervision by employing a small set of human-defined principles or rules to guide LLM-based AI agents in generating responses to user queries. As a result, SELF-ALIGN achieves remarkable performance surpassing several state-of-the-art AI systems, including Text-Davinci-003 and Alpaca, across various benchmark datasets and settings.
This underscores the importance of yet another crucial aspect of the LLMs; the human feedback & reward mechanism. It plays an outsized role in LLM performance just like the quality of InstructDB.
Falcon40B — Data is the King
The model which is currently on the leader board chart is Falcom40B. How come a 40B model outperformed models which are much bigger than it?
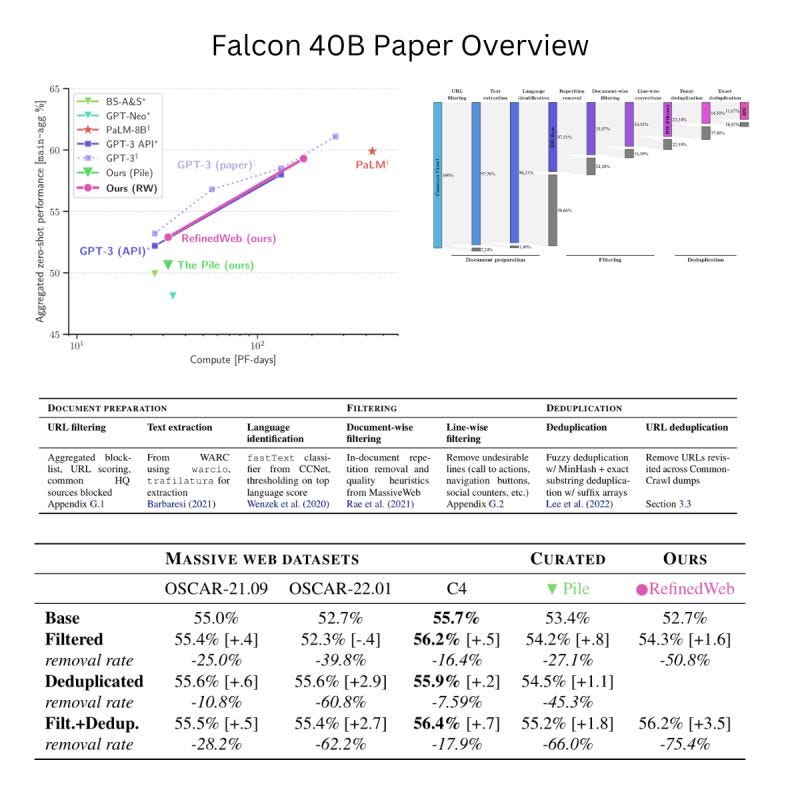
Falcon40B has been trained on a massive web dataset called RefinedWeb, which combines public web crawls with carefully curated sources like research papers and social media conversations. This blend allows the models to achieve exceptional performance, surpassing many other models on NLP benchmarks.
This highlights the cardinal rule in data science, that the quality of data determines the quality of the model. A $1 spent in data engineering saves $9 in data science.
Our Research on Generative Q&A Use-case
My team has been working on finding a general-purpose model for Generative Q&A for an enterprise’s private knowledge base. And in order to find optimal performance we have bench-marked against both public & private datasets.
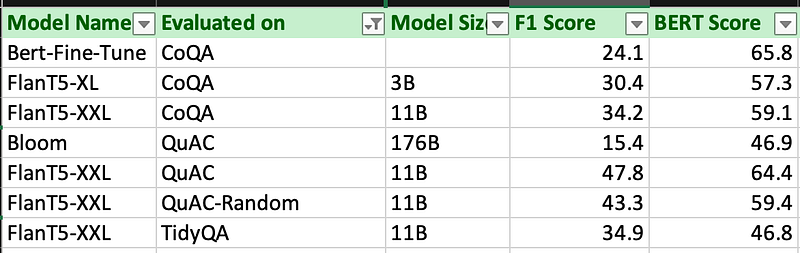
We have used our ML pipeline against the public Q&A datasets like CoQA & QuAC (Question Answer in Context). As you can see for CoQA the gain between a 3B vs 11B model is very marginal. On the other hand, BLOOM-176B performs quite badly on QuAC dataset and is outperformed by Flan-T5 11B models by a wide margin.

Similar results were obtained on the private knowledge base as well. The F1 score is worse for the 176B model than the 3B model.
This should highlight the next key takeaway; finding the right model type for your use case is much more crucial than the size of the model.
Larger the model larger the budget needed
GPUs are currently experiencing a shortage, and even when available, they can be quite expensive. As a rule of thumb, for fine-tuning a 7B parameter model, you would typically require one GPU, while RLHF and larger models may need four GPUs. This places the compute cost at a bare minimum of $15–25K. In the field of enterprise AI, the primary focus is always on creating business value. Therefore, if ten models are fine-tuned to achieve optimal results for a single use case, costing $250K, executives typically expect to see a return on investment (RoI) of 10x that amount. When dealing with multiple use cases, expectations rise, while patience decreases.
In this context, it may be a wise decision to manage costs in enterprise LLM by taking measures such as cleaning your data, finding experts who employ deliberate strategies rather than trial and error for fine-tuning, creating a high-quality instruct DB, constructing the right pipeline, and addressing other essential ML tasks. This approach may prove more effective than diving into one large LLM, which, despite consuming significant computational resources, may still fail to achieve the desired results.
In subsequent blogs I will detail each of these steps and what we have learned.
Follow Towards Generative AI for more technical content related to AI.
Subscribe to the 3 min newsletter to learn about 3 most impactful things in Generative AI every week.