
LLM’s for Enterprise –Generative Q&A on Your Private Knowledge Base
How to construct a cost-effective, secure, and trustworthy Generative AI solution with a purpose-built open architecture using RAG (Retriever Augmented Generation)?
Once upon a time, in a world buzzing with excitement and intellectual curiosity, ChatGPT emerged as a transformative force. Unless you were dwelling on Mars, chances are you had already embarked on a fascinating experience with ChatGPT.
As the wonders of ChatGPT permeated the collective consciousness, enterprises were quick to envision the potential within their own realms. A common desire echoed “I wish we had an internal ChatGPT-like tool for our company.”
While the availability of ChatGPT OpenAI APIs is one option, many companies wonder “Why settle for existing options when we can strive for a purpose-built architecture tailored to our needs?”
Why do you need a private/purpose-built LLM stack?
•Do you want to avoid hallucinations?
•Do you want to fine-tune the model to your enterprise data?
•Do you want to protect your enterprise data from going outside?
•Do you want to let them use your data to improve external LLM (GPT)?
•Do you want control of the inference cost of running LLM?
•Do you want to own your models?
•Do you want to not risk leaking your proprietary data?
•Do you want your models to be copyright issues free?
If the answer to any single one of the above questions is yes, then it matters if you consume LLM in closed architecture from OpenAI or in a truly open & trusted architecture that you can control.
Truly Open LLM Architecture
Harness the power of technology built on an Open Source foundation, enabling you to deploy models effortlessly wherever they’re needed. With the ability to curate training data sets and filter out offensive content, you can ensure the highest standards of ethical AI. Stay vigilant through continuous system monitoring, preventing the generation of harmful content. Embrace a private generative AI platform that puts you in complete control, allowing you to govern data access and finely tune training data to mitigate the risk of leaks.
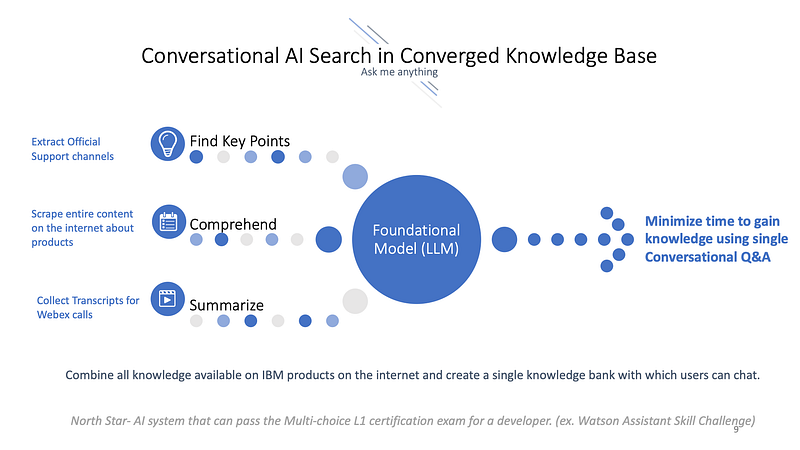
Generative Q&A on Propriety Knowledge base
It is a widely acknowledged reality that knowledge within any company is often fragmented. Official product documentation contains valuable information (which itself is often siloed), but there is also a wealth of knowledge scattered across Slack datasets, internal learning sessions, and articles and blogs published both internally and externally. When faced with technical questions about a company’s product, how can one obtain a definitive and reliable generative answer?
Let’s look at how this problem can be solved step by step, starting with the simplest solution.
A. Grounded Data + Public LLM Model
To address this challenge,embarked on an extensive effort to scrape over a quarter million pages of product documentation, encompassing both external and internal sources. This comprehensive collection forms what is commonly referred to as a grounding set. Whenever a user presents a query, it undergoes an “Information Retrieval search” process using this grounding set. The results are then fed into a large language model as an “in-context/zero-shot” learning approach, enabling the generation of more fluent and articulate answers.
This conceptual architecture serves as an ideal starting point, allowing for swift implementation in as little as one week. By utilizing search results from the grounded set as prompts, the risk of generating erroneous information, or hallucination, is significantly reduced (we will explore how to further mitigate this risk later). However, there are a few limitations to consider.
Firstly, we must address the challenge of ensuring the relevance of search outputs. Merely relying on the top result may lead to the generation of entirely unrelated answers. To overcome this, we introduce an additional component to the architecture known as the Re-Ranker Algorithm.
Secondly, evaluating the effectiveness of our results becomes crucial. We need to establish an evaluation framework to assess the accuracy and quality of the generated answers. Additionally, creating a comprehensive set of question-and-answer prompts, known as an instruct set, is essential to aid in question-answering kits.
Lastly, capturing human feedback on the generated answers is vital. By gathering insights from users and understanding their experiences with the generative answers, we can continually refine and improve the system.
These considerations pave the way for a robust and reliable solution, allowing us to harness the power of generative answers while addressing key challenges and incorporating user feedback throughout the process.
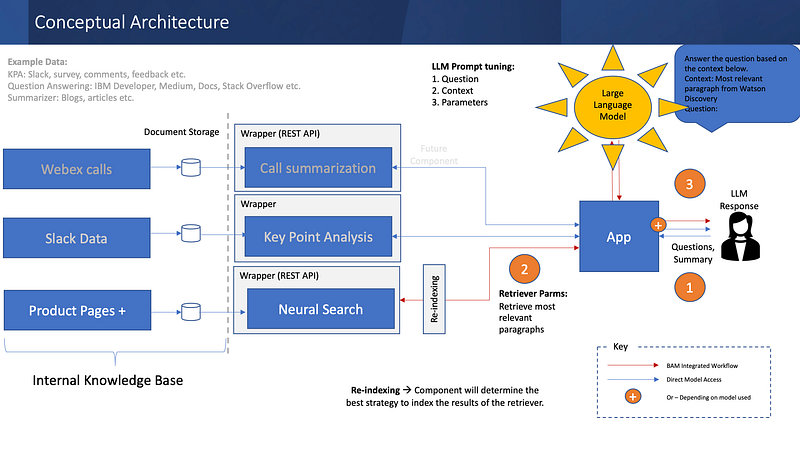
B. Grounded Data+Private LLM Model
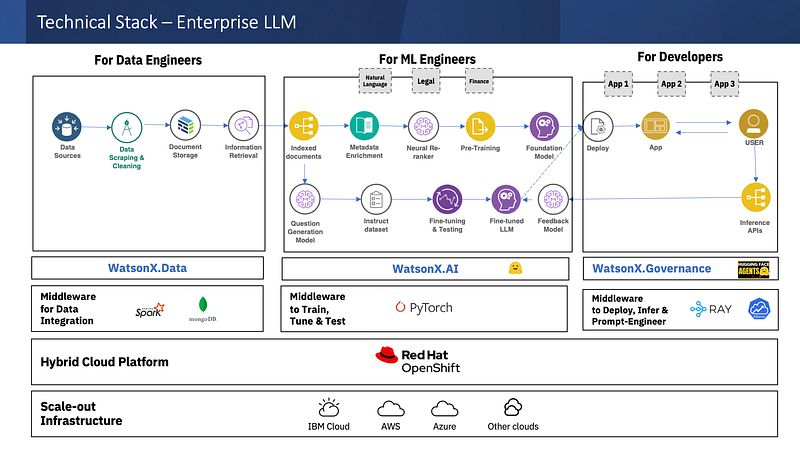
So we enhanced the architecture by adding the below components
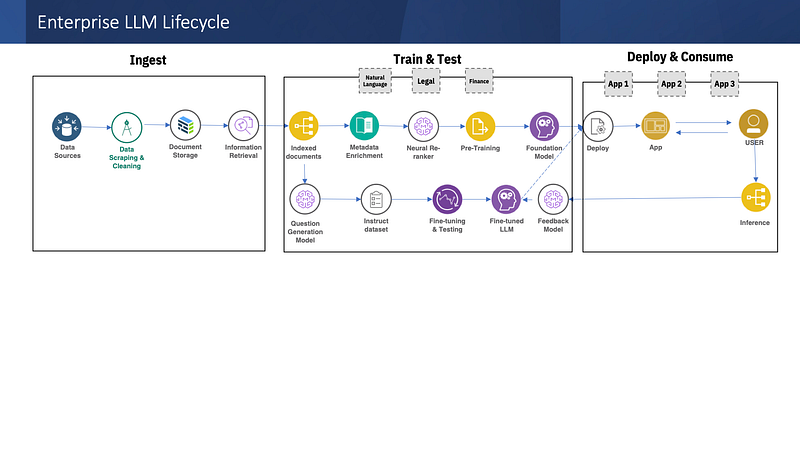
I. Data Ingestion
- Data Collection — The data is scraped, cleaned, and stored. To being with scraped 140K documents with about 250K pages.
- Information Retriever Engine- One of the information retriever options for Watson Discover or Solr or Elastic Search. Index pages and enrich metadata.
II. Train & Test
3. Re-ranker — In this step, we first retriever the search result from our “private dataset” and pass it through a neural re-ranker. We used a ColBERT re-ranker for this purpose. This will re-rank the search results before it is passed into the LLM (BLOOM, FLAN-T5 or more).
4. Instruct DB- An additional model is used to create questions that become part of instruct set. This is combined with other instruct set DB like manually curated answers and a corpus of exams on the internal knowledge base.
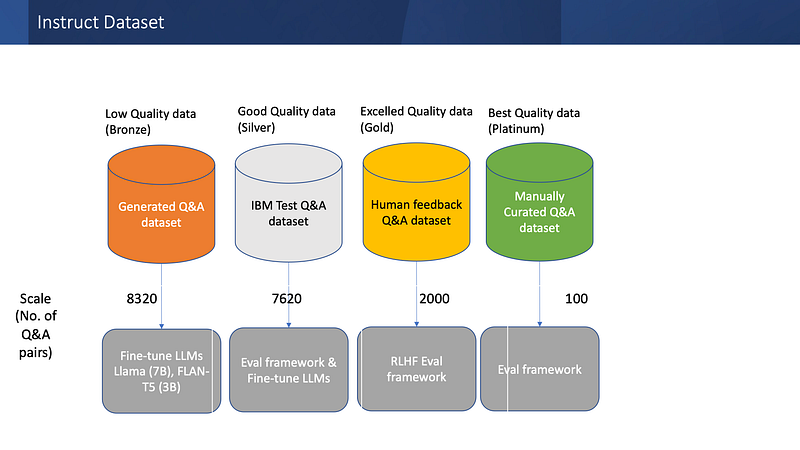
5. Fine-Tuning- An optional workflow is to fine-tune the LLM and create a fine-tuned version of the model that gives better accuracy. (This we will cover on the next blog). If you wish to keep data & models behind your firewall this is the option you need.
6. Evaluation — Eval scripts are processed for standard NLP metrics like BLEU or ROUGUE as well as human metrics on the quality of generated answers like veracity, momentum, manner etc. Automated eval frameworks like Lamini, and PandasLM can also be used.
III. Consume
6. Deploy- In case the model is fine-tuned, you can deploy it in this step. Else consume it in API form with “Model As a Service”.
7. Inference for User App- An user app to provide engage with end-user like ChatGPT.
8. Feedback Model- The human feedback is incredibly important for any generative AI project since there are few quantitative metrics for it’s accuracy. RLHF will go here.
9. AI Governance- User inference can be monitored for concerns of harmful content and ethical considerations.
The above architecture can work relatively well as an MVP and can be deployed with a middleware for workflow orchestration. This can be constructed on the watsonx models.
While the risk of hallucination is reduced in this architecture it is not completely eliminated. You can be sure to get a good answer if an answer exists in the corpus; but if it does not then instead of saying “I don’t know” it may hallucinate. In order to do so you would a model which is trained on data that is trustworthy to begin with. watsonx Foundational Models, designed for air-gapped enterprises is a good option for it. More on that in the next blog.
…
And so, the tale unfolded — a tale where enterprises are in pursuit of a purpose-built LLM architecture for Generative Q&A; forever transforming the way knowledge flowed within their companies.
Check out the next blog on this topic to understand why bigger LLMs don’t always give better results for such Q&A problems. https://readmedium.com/llms-for-enterprises-why-bigger-isnt-always-better-5960ec6ffb9c
Follow Towards Generative AI for more technical content related to AI.
Subscribe to the 3 min newsletter to learn about 3 most impactful things in Generative AI every week.




