
LLM Apps : Why there is no Prod ready RAG w/o Distributor : 2
Let’s build Distributor Today !
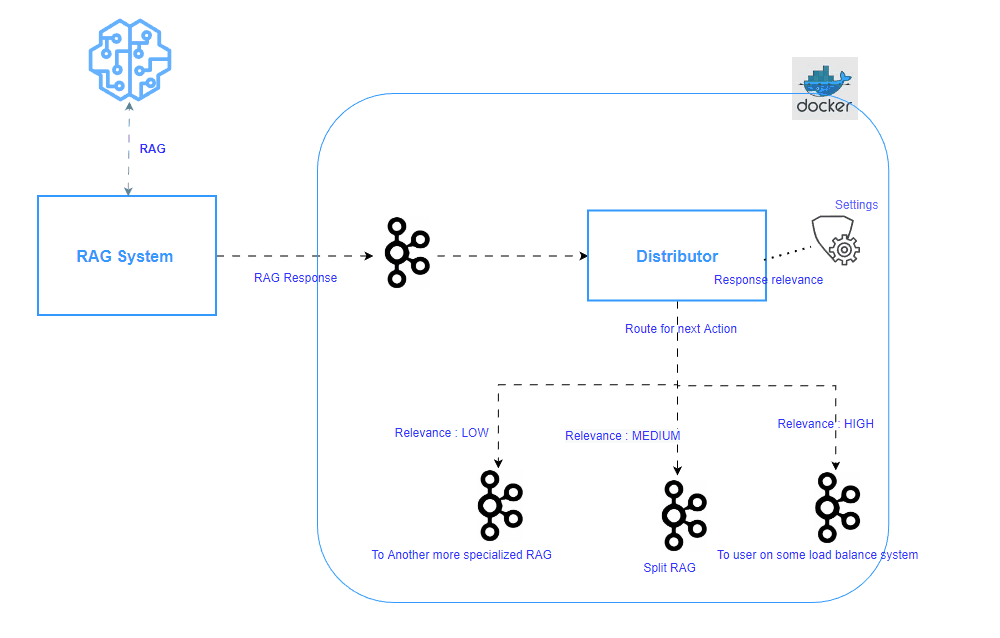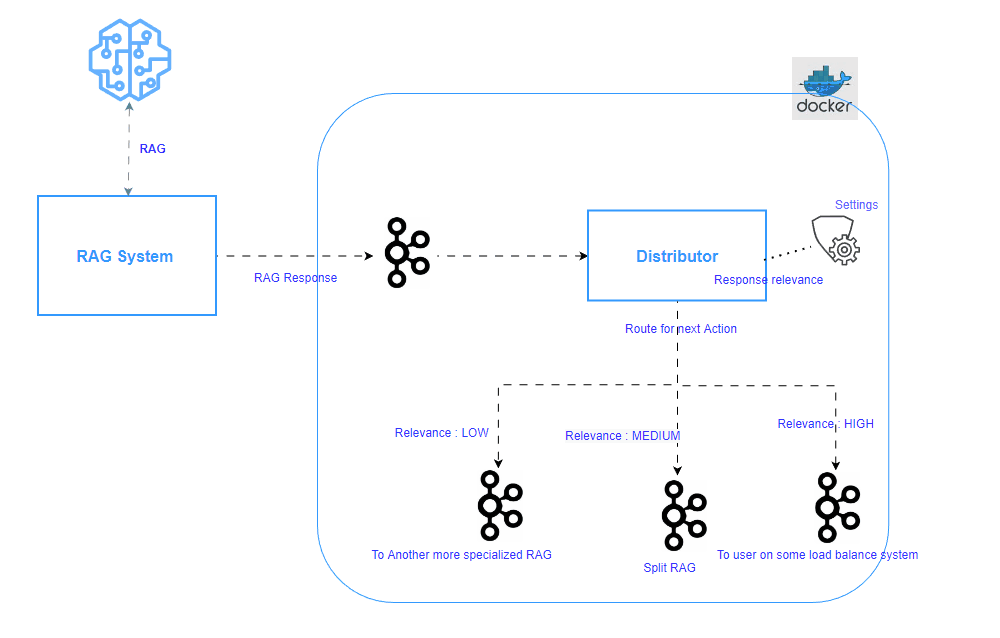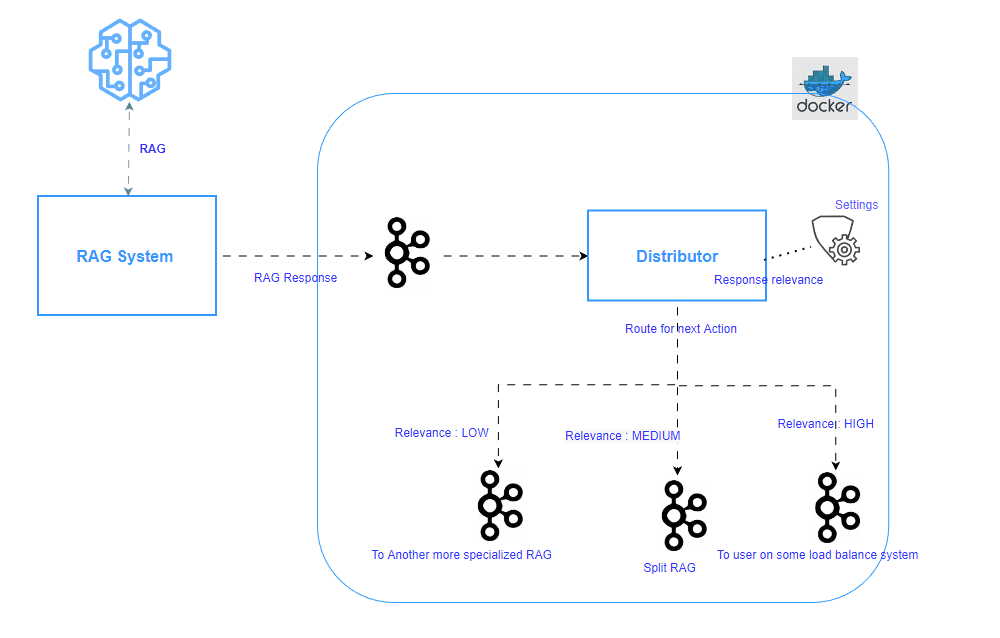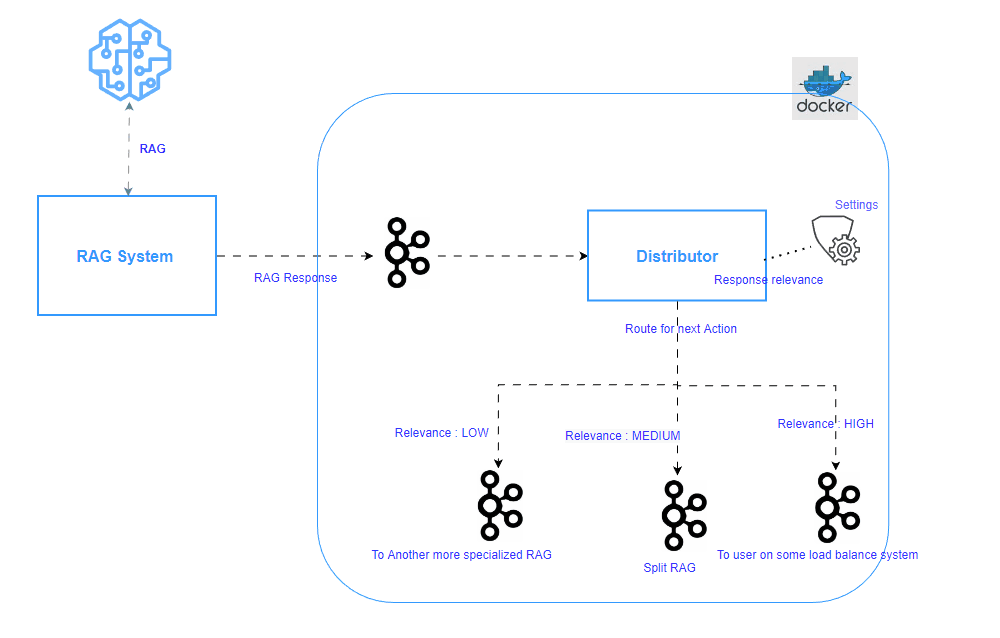
In the first installment of this series ( as below), we delved into the theoretical concepts of a distributor within Retrieval Augmented Generation (RAG) systems. We focused on the value proposition of a Content-Based Router (CBR) to address RAG limitations such as specialization versus accuracy trade-offs and efficient resource use. Now, we’ll shift focus to bring that theory to life with practical code implementation.
Project Structure
For clarity, let’s recap the main project components of our RAG distributor system:
- Docker & Kafka Setup: Leverages Kafka’s pub/sub for reliable message handling among RAG models.
- Shell Creation Script: Automates Kafka’s notoriously verbose, command-line driven topic creation.
- Docker Compose Definition: Orchestrates containers (Zookeeper, Kafka) into a unified system.
- Kafka Streams Distributor Code: Core business logic, written in Java, implementing rules-based filtering of generated responses, routing them to respective topics.
- Testing Methodology: Ensures correct routing using sample responses of differing relevance scores.
Key Reasons for Using Kafka
- Scalable Event Streaming:
- Pub/Sub: Decouples response handling by having RAG models and other system components subscribe to specific topics (highly relevant, moderate, etc.). This promotes system responsiveness and allows you to add new RAG models or change downstream consumers without rewriting core modules.
- Parallelism & Partitioning: Topics in Kafka can be partitioned, meaning you can spread data across multiple brokers within the Kafka cluster. This enables horizontal scaling as you process larger response volumes or deploy to more production-like environments.
2. Fault Tolerance and Reliability:
- Persistent Durable Storage: While messages can be processed in real-time, Kafka writes them to disk immediately. This prevents message loss in case of process failures or downtime. It also supports log retention, providing traceability.
- Replication: Kafka replicates partitions across multiple brokers. If one broker fails, your data is still available without interruption. This is key when maintaining reliability for an entire LLM application.
3. Processing Guarantees:
- Ordered Deliveries: Within a topic’s partition, Kafka guarantees message ordering. This can be critical for certain applications, where it’s important to process LLM responses in the order they were generated for consistency or downstream decision-making.
- Exactly-Once Processing: When combined with proper consumer configuration in your code, Kafka can help ensure messages are processed only once — avoiding unintended side effects or duplication of actions.
4. Real-Time Agility:
- Stream Processing: The core distributor application uses Kafka Streams, a processing framework built on top of Kafka. It allows for powerful, real-time stream transformations — in this case, the filtering and routing of responses.
- Integration Ecosystem: Kafka offers robust integration with numerous other systems (databases, data lakes, etc.), allowing responses to be stored or routed to any destination within your enterprise stack.
Why the Alternatives May Be Less Suited
- Simple Message Queues (RabbitMQ, etc.): While useful, the focus is less on scalable streaming and more on task distribution. They also often lack advanced fault tolerance and log retention features.
- REST APIs: Can be too synchronous and rigid. This approach would mean constant polling, introducing unnecessary overhead and hindering scalability.
Let’s get cooking !
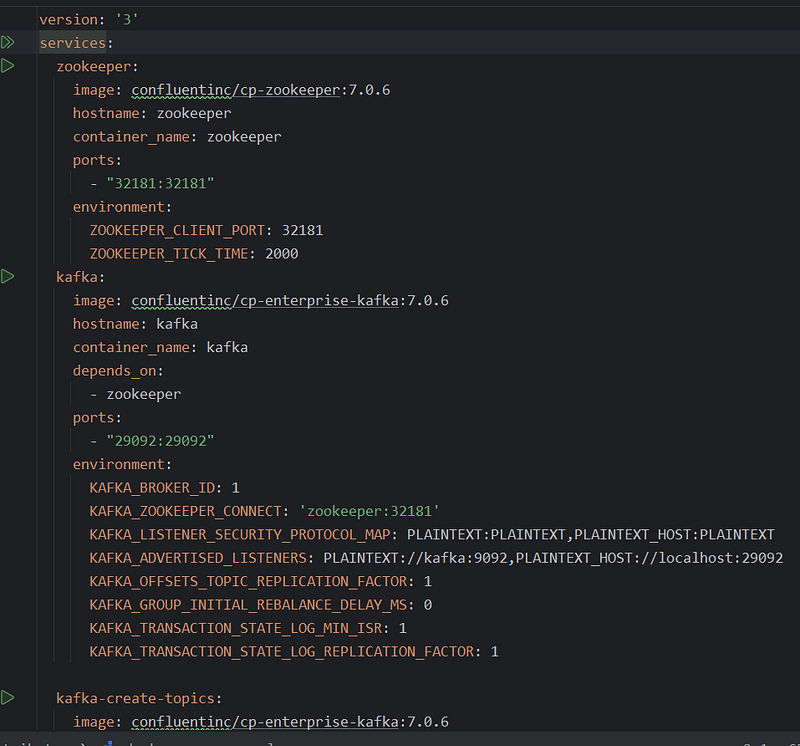
Simple kafka setup
Core component
Some logic showcase
Lets go over code
Overall Purpose
The core function of this code is to implement a system that reads an incoming stream of LLM-generated responses and routes them into separate Kafka topics based on their perceived relevance (e.g., highly relevant, moderately relevant, etc.). To do so, it employs Kafka Streams, a library built on top of Apache Kafka, designed for real-time processing of data streams.
Component Breakdown
- Package Declaration:
package com.test.aniket.core;-- Declares that the code belongs to a package named 'com.test.aniket.core', providing organization and preventing naming conflicts in larger projects.
- Imports:
- Standard Kafka and Kafka Streams-related classes for:
- Consumers (
ConsumerConfig) to configure streaming behavior. - Serializers/Deserializers (
Serdes) for converting messages between bytes and Java objects. - Constructing streams topologies (
StreamsBuilder). - Overall configuration (
StreamsConfig). - Managing the Kafka Streams application lifecycle (
KafkaStreams). - Sending messages to different topics (
Produced).
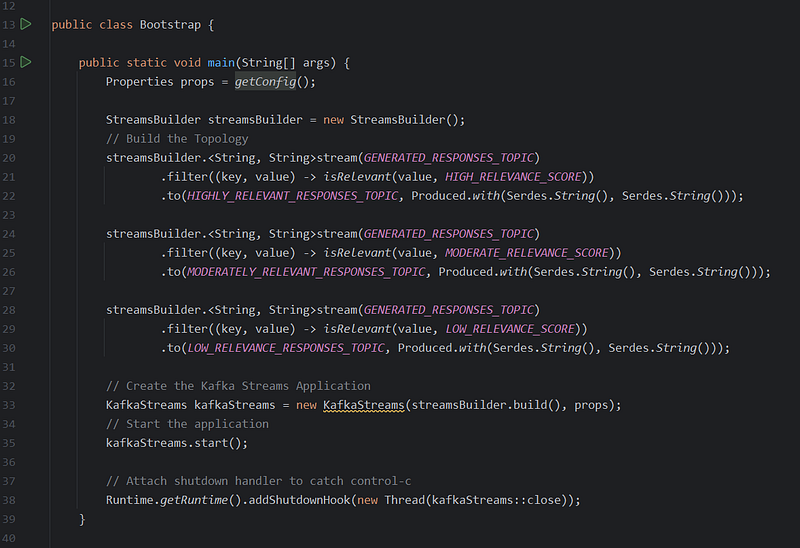
- Public class ‘Bootstrap’:
- Contains the
mainmethod as the entry point of execution for a Java application.
mainMethodgetConfig(): Calls a helper function to retrieve stream processing configuration settings.StreamsBuilderInstance: Creates an instance (streamsBuilder) to establish the processing flow of data within Kafka Streams.- Filtering & Routing Logic (3 Repeated Blocks):
.stream(GENERATED_RESPONSES_TOPIC): Reads data from the specified Kafka topic..filter(...): Applies condition logic (via theisRelevantfunction) to extract messages of a specific relevance tier..to(...): Forwards successfully filtered messages to the appropriate output topic for their level of relevance (e.g.,HIGHLY_RELEVANT_RESPONSES_TOPIC). Note theProduced.withstatement configures how data will be serialized upon being written to the new topic.
KafkaStreamsCreation: Builds aKafkaStreamsobject from the defined topology (streamsBuilder), passing properties fromgetConfig().KafkaStreamsStart: Starts the Kafka Streams application, initiating the flow of data.- Shutdown Hook: Gracefully shut down the
KafkaStreamsinstance using a JVM shutdown hook activated on control+c signal (interruption). getConfig()
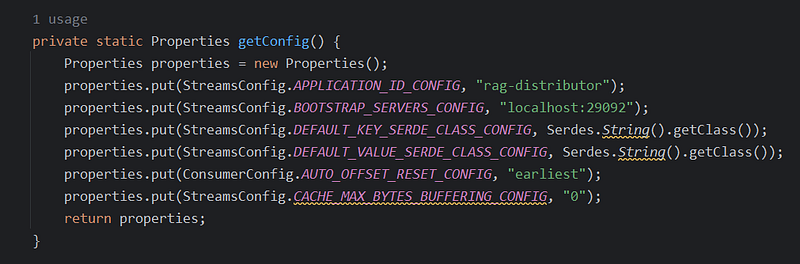
- Creates and populates a
Propertiesobject for Kafka Streams configuration: APPLICATION_ID_CONFIG: A unique identifier for your application, important for tracking behavior.BOOTSTRAP_SERVERS_CONFIG: Specifies brokers of the initial Kafka cluster to connect to.DEFAULT_KEY_SERDE_CLASS_CONFIG&DEFAULT_VALUE_SERDE_CLASS_CONFIG: Default data serialization/deserialization for both keys and data in messages. Here, using basic string serialization.AUTO_OFFSET_RESET_CONFIG: Behavior on startup if no committed offsets for consumer's group – 'earliest' ensures processing from the start of the topic.CACHE_MAX_BYTES_BUFFERING_CONFIG: Buffering of streaming data during processing is disabled (set to 0), meaning messages are routed as soon as possible.
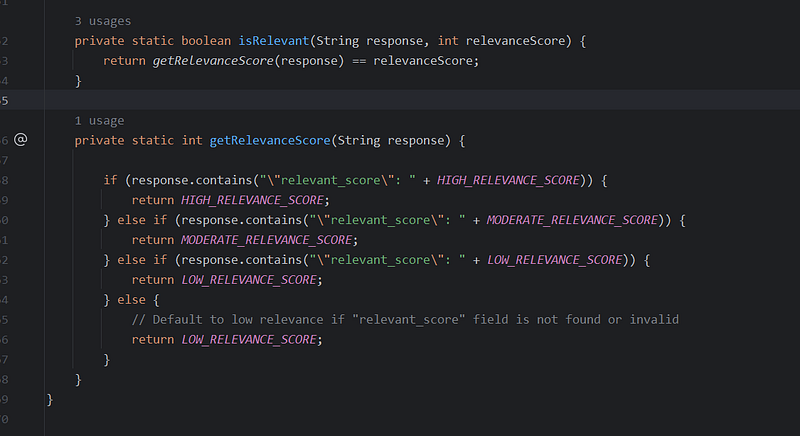
isRelevant()
- Logic to determine if a particular LLM response qualifies for a given relevance tier based on the
relevanceScoreparameter.
getRelevanceScore()
- Inspects JSON-formatted LLM responses to extract a
"relevant_score"field which is pre-assumed to exist within the responses. It returns a numerical relevance score.
It’s Demo Time !

- Start zookeeper container
- Start kafka container
- Start LLM distributor-kafka-create-topic container
- Start Application
Assume RAG response came in ( we mimic by sending those responses on response topic)
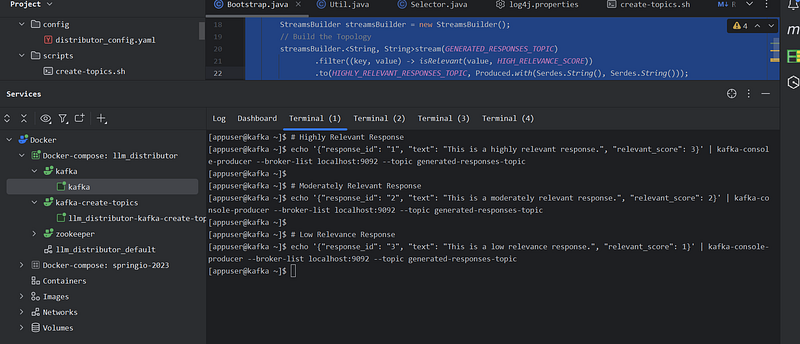
Results of our Distributor Execution



Conclusion
With the successful implementation of this code, we’ve built the core foundation of a scalable RAG distributor system powered by Apache Kafka and its stream processing capabilities. Now, when Retrieval Augmented Generation (RAG) models produce responses, they will be intelligently routed to different relevance-based topics within your Kafka cluster.
This sets the stage for downstream components to act upon the distributed responses in customized ways: highly relevant replies might be sent instantly to end-users, while moderately relevant ones could be flagged for human review, providing greater control over LLM integration into your application.
Future Enhancements
Remember that this is merely the core functionality of a sophisticated distributor. Exciting further directions could include:
- Complex Rule Engine: Replace simple relevance score checks with advanced business logic or even a dedicated rules engine for intricate routing decisions.
- Dynamic Configuration: Allow modification of routing rules without code redeployment, potentially through external databases or UI interactions.
- Ensemble Techniques: Implement scenarios where the distributor combines or selects the best answers from multiple RAG models.





