Introduction to neural networks.
This is the second part of deep learning workshop. The link to lessons will be updated as soon as I write them. Github link of this repo is here.
Index
- Introduction to machine learning and deep learning.
- Introduction to neural networks. < — You are here
- Introduction to python.
- Building our first neural network in keras.
- A comprehensive guide to CNN.
- Image classification with CNN.
Before jumping into neural networks we will first learn about basic building blocks of neural network.
Basic building block of deep learning : -
Perceptron
Perceptron is the building block of neural networks and deep learning is a lot of neural networks stacked together. So before diving into neural networks, let’s take some time to study perceptions. Perceptron takes an input, aggregates it (weighted sum) and returns 1 only if the aggregated sum is more than some threshold else returns 0. A way you can think about the perceptron is that it’s a device that makes decisions by weighing up the evidence. By varying the weights and the threshold, we can get different models of decision-making.
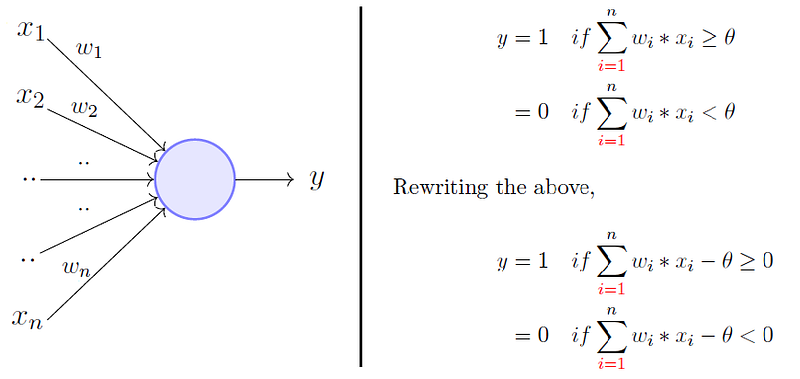
Let’s implement one function to give you more insight to perceptron.
AND Function Using A Perceptron : -
We know the truth table for AND gate. It takes two binary inputs and gives their product as an output. Let us think of weights w1 and w2 and threshold(bias) which will give the correct output.
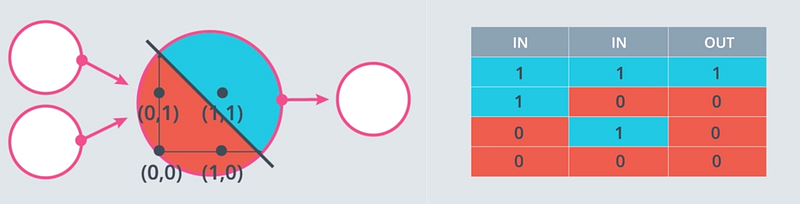
W1 = 1.0 W2 = 1.0 threshold = 2.0 Using these values for each case we get,

Sigmoid neuron
The issue with perceptron is they are very harsh step functions giving output only as 0 or 1 because of this small changes in weights can make a large difference in output, on the other hand in sigmoid neuron small change in weights will make only small change in output. There is a slight difference between the sigmoid neuron and perceptron, instead of using thresholds we use sigmoid function to get output from the weighted sum. Sigmoid function and its output is given by,
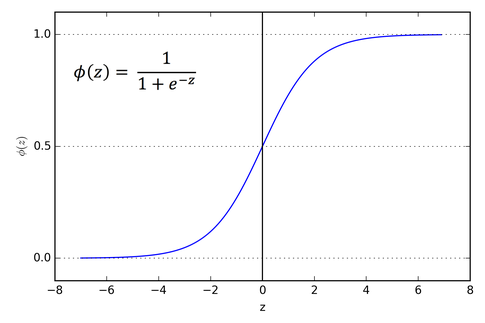
So we get the output as,
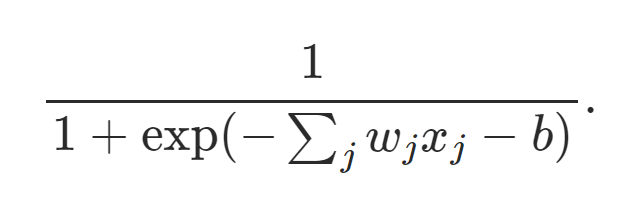
What is neural network?
A neural network also known as artificial neural network(ANN) is the basic building block of deep learning. It consists of layers of sigmoid neuron stacked together to form a bigger architecture.
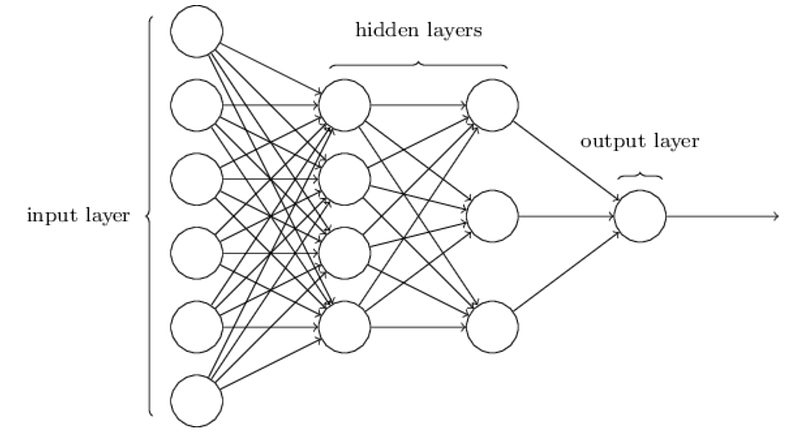
Each circle in the above image is a sigmoid neuron. It consists of 3 types of layers, an input layer, an output layer, and hidden layers. All the previous layers are fully connected with the next layer as can be seen in the image so it is sometimes also referred to as the fully connected neural network. Each neuron has its own weight values. The first layer(input) takes the independent variable of data as input. Output layer predicts the class. The number of hidden layers and number of neurons in hidden layers is not fixed and you can choose any number and tinker to get the best results.
How neural networks learn:-
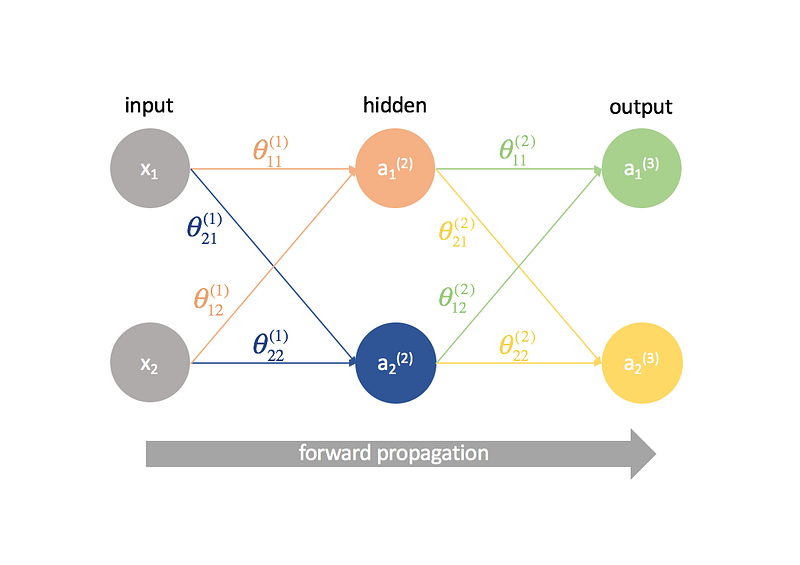
Neural networks are just the weighted sum of the inputs. So the learning of neural networks is based on updating these weights. We need a method to update the weights. It is based on how good the neural network is performing. Performance of the neural network means how good are the predictions based on the actual labels that are to be predicted. The value at the output layer is calculated by crossing through the neural network and finding the value of each neuron. This process of crossing through the neural network is called forward propagation.
For measuring the performance of a neural network we introduce loss function which calculates how bad the neural network is. Loss function depends on the task we are trying to solve, there are plenty of loss functions but we will discuss two most used ones.
- Cross-entropy loss:- It is used for the classification problem and calculates some value using a function based on the true input label and the predicted output label. The function is given by,
cross entropy loss = −(y*log(p)+(1−y)*log(1−p))
Here y is true label and p is predicted label.
2. Mean Squared Error(MSE):- It is used in the regression problem and calculates the distance between the true value and predicted value. It is given as,

Once the loss is calculated we need a method to change the weights of the neural network with respect to the calculated loss. We backpropagate through the neural network and update the weights. based on the relative contribution that each neuron has contributed to the original output. This process is repeated, layer by layer, until all the neurons in the network have received a loss signal that describes their relative contribution to the total loss. The change to be made in weights is calculated using gradient descent. Gradient descent is an important concept to understand the neural network so before going forward please watch this video. The complete learning process of neural network is given as,
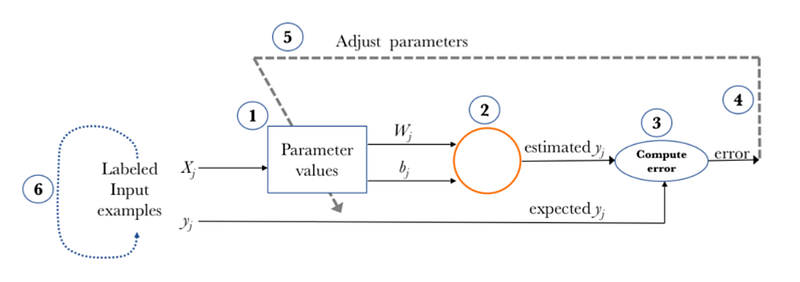
In the later chapters, we will discuss how to improve the neural networks using various techniques and also discuss some better optimization algorithms such as Adam optimizer.
Peace…