
If Neural Network is a Black Box for You, This is What You Need to Realize.
When I was a beginner I found it hard to understand why everything works and why we use it. Why activation functions are activation functions, why CNNs learn the relationships between pixels, why hidden states in RNNs are also context vectors and etc. However, having a background in math, it made so much sense after I paid much more attention to math. Math cannot be neglected or taken for granted, math is never a black box. I hope this works is useful for beginners and I help them understand Neural Networks better. Thank you!
Checkout:
Introduction
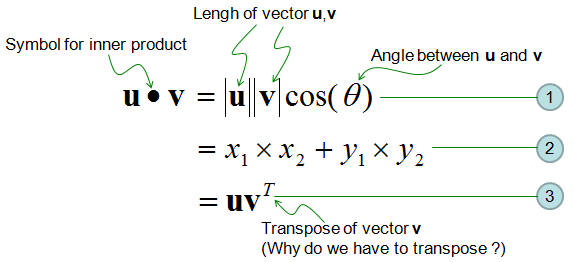
The figure above shows the formula of inner product that we all know pretty well from middle school. We see that the inner product is essentially the multiplication of the lengths of the vectors (u and v) and the cosine of the angle between them. Thus, assuming both vectors, u and v, are l2 normalized (meaning the lengths become 1), the inner product becomes cosine of the angle between vectors. This means the closer the angle towards 0, the greater inner product is (convince yourself). Likewise, if two vectors go in opposite directions, the inner product becomes -1 (min value). Under this assumption, our inner product is also equal to the cosine similarity (or distance) between two vectors.
Linear Layers
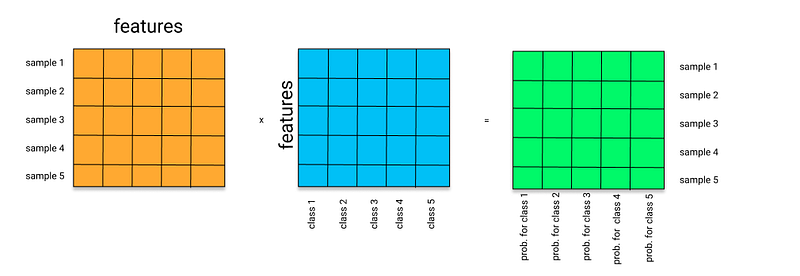
Now let’s extend this concept to simple classification example. Say the orange matrix represents our mini-batch where each row is a separate sample from our dataset each having 5 features. The blue matrix is our classification head (we excluded bias term for simplicity), you can also think of a simple logistic regression. Thus, we simply compute the inner product between every sample and every class vector within our blue matrix. Assuming l2 normalized matrices, it is easy to understand that we want to optimize the cosine similarity by making our class vectors be closer to their corresponding samples (orange matrix) as much as possible. This is why the Gradient Descent algorithm is used for Deep Neural Networks. I don’t want to dive into details of Backpropagation here but if you need to read more about it, I am leaving some articles here.
Get Started:
Approach Complex Functions with a Backpropagation: How I was applying to Yandex?
In Deep Neural Networks, however, we have multiple Linear Layers, meaning we also have hidden layers that come before our classification head. So, what happens there? I believe hidden layers help find and learn useful features from those that we provide as input. This is also why activation functions, such as Sigmoid, Tanh and ReLU, are also useful. Sigmoid function is very nice in terms of interpretability since it outputs values within the range of 0 and 1, so we could see how relevant each feature is towards our goal. However, ReLU is much more common in practice, have you ever wondered why it works? Keep in mind the concept above and think if we really need to keep very negative values.
Convolution Layers

We are taught that kernels learn useful patterns such us corners or circles as in the figure above. But have you ever wondered how it’s possible?
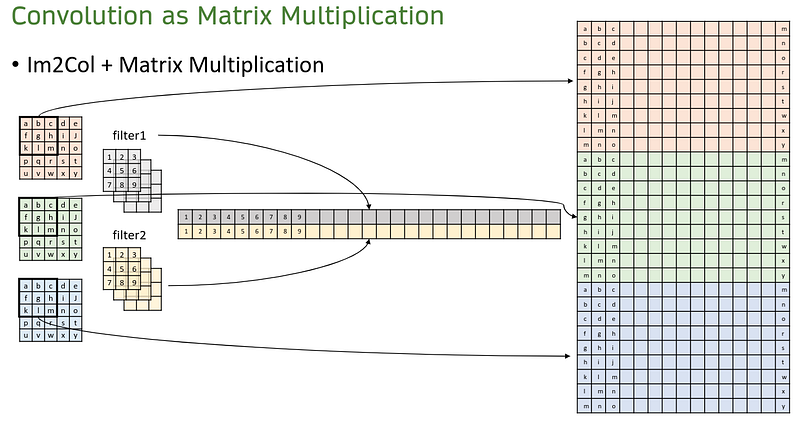
I assume we know how convolution works, so let’s now realize that we can perform it by matrix multiplication. Let’s say filter 1 in the figure learnt to identify circles (say we want to identify circular patterns such as eyes), then representing both filter 1 and some 3 x 3 region of an image as vectors, we can also compute the inner product. If the region does contain circular patterns, then the inner product between them becomes greater. This is how kernels are able to find useful patterns. Moreover, this is why we are taught that CNNs are able to learn relationships between pixels.
Dropout scenario
Furthermore, this is also why we want to use augmentations, such as dropout, to learn as much patterns as possible. Say the region that contained some circular object resulted in a great number after applying kernel 1, after we apply dropout this number might be zeroed. Thus, subsequent kernels now have to learn different patterns instead of solely relying on circular patterns.
Recurrent Neural Networks
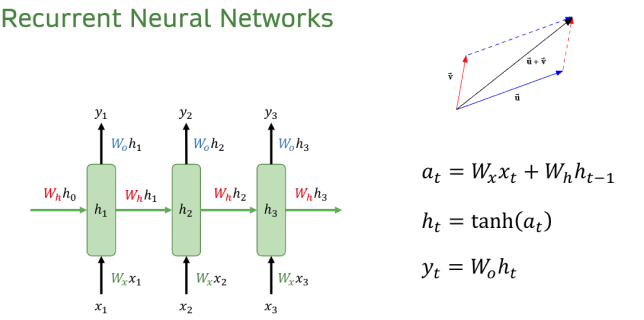
I believe now it might be much easier for you to understand RNNs. But have you ever wondered why hidden state is used to represent the context vector, especially in encoder-decoder architectures? Take a look how hidden state is updated. It is essentially a sum of the past and current information. Also, look at the picture of the sum of two vectors. Thus, the final direction of the hidden state is affected by all the x input vectors along a sequence. Remind yourself that the direction of the vector plays an important role in the inner product. This is why it is a context vector and this is why it works well.
Other Applications
If you look at everything as simply taking inner products, it will make much more sense. This is why Attention blocks are so popular these days. You can read more about attention mechanisms in my article below:
Introduction to Attention Mechanism: Bahdanau and Luong Attention
Some Last Words
I often hear from beginners that Deep Neural Networks is a black box. I mean when I started learning I struggled to. But math cannot be neglected or taken for granted, math is never a black box. I hope this piece finds its readers. This is what I needed to realize when I was a beginner. Thank you for your time reading this work (: