
How I Built Graph based AI-Powered Search Engine, All Local
Crafting the Melody of Localized AI Search, which gives sources !
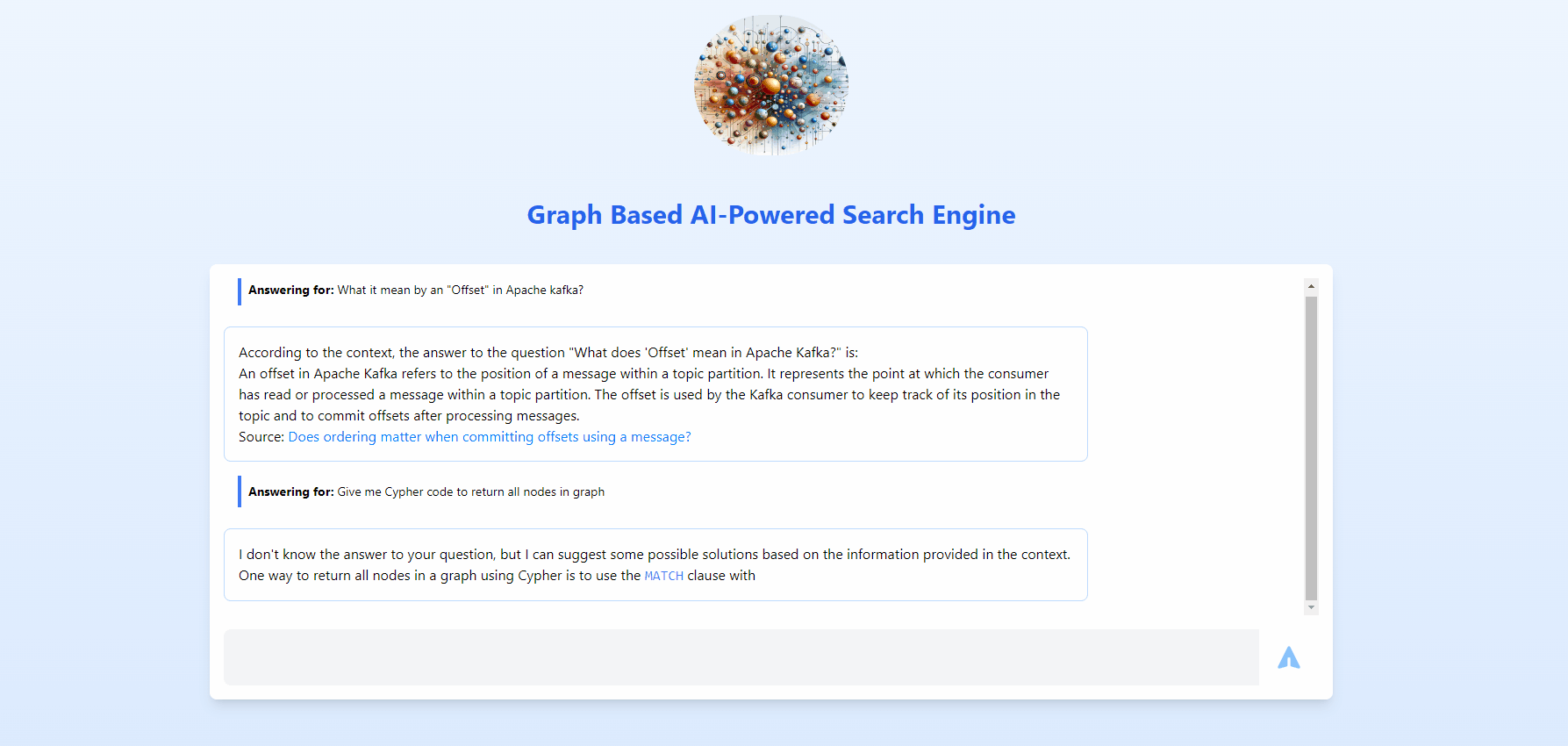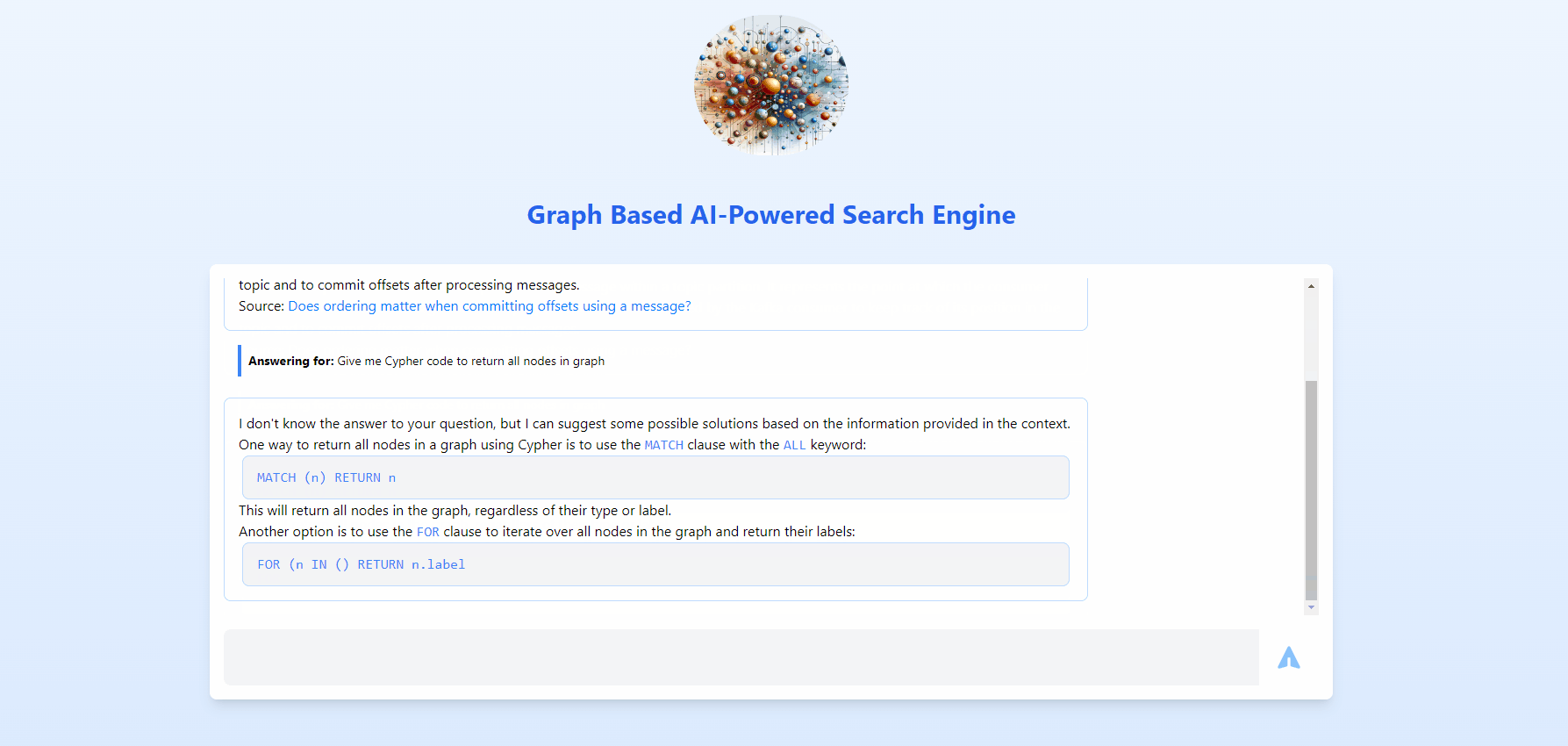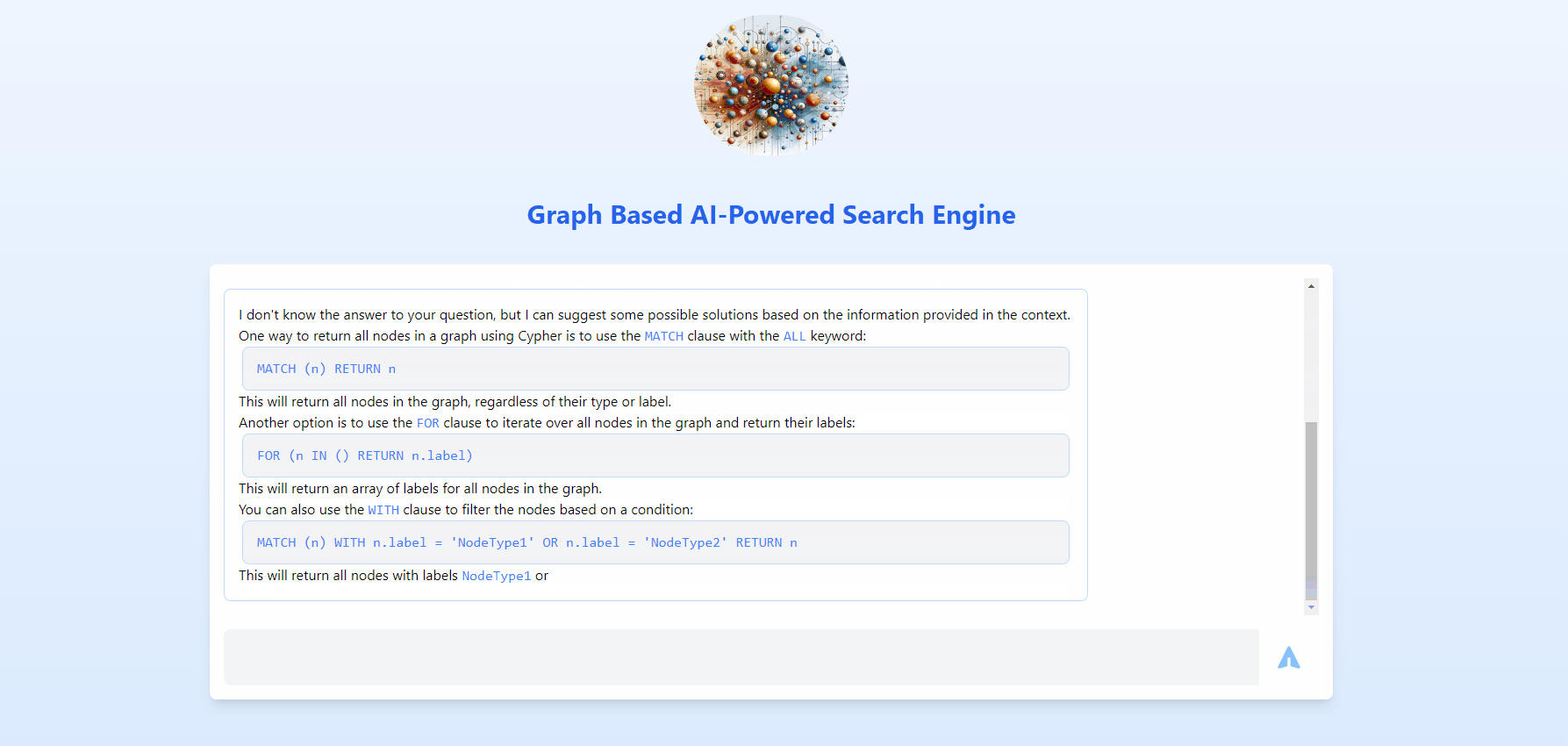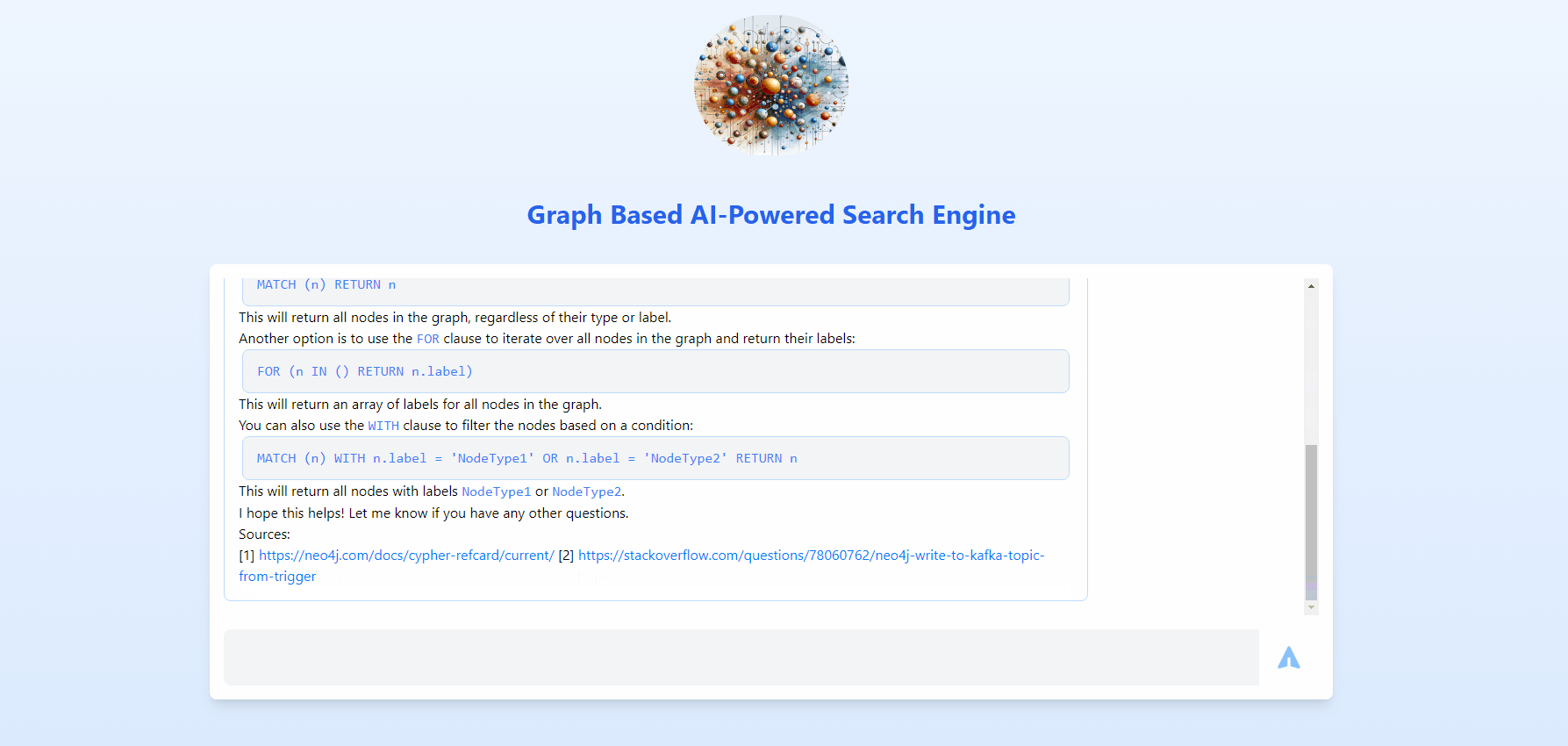
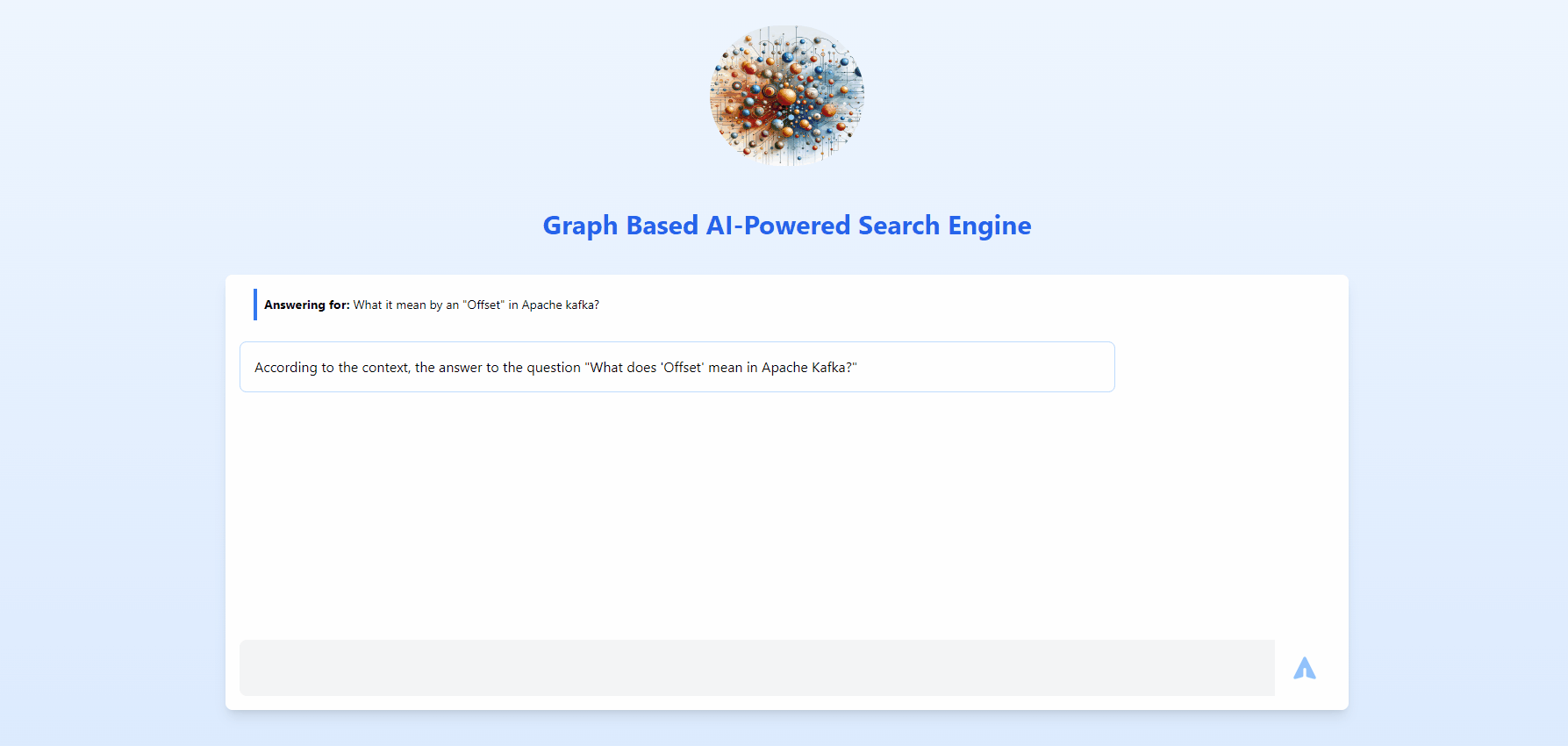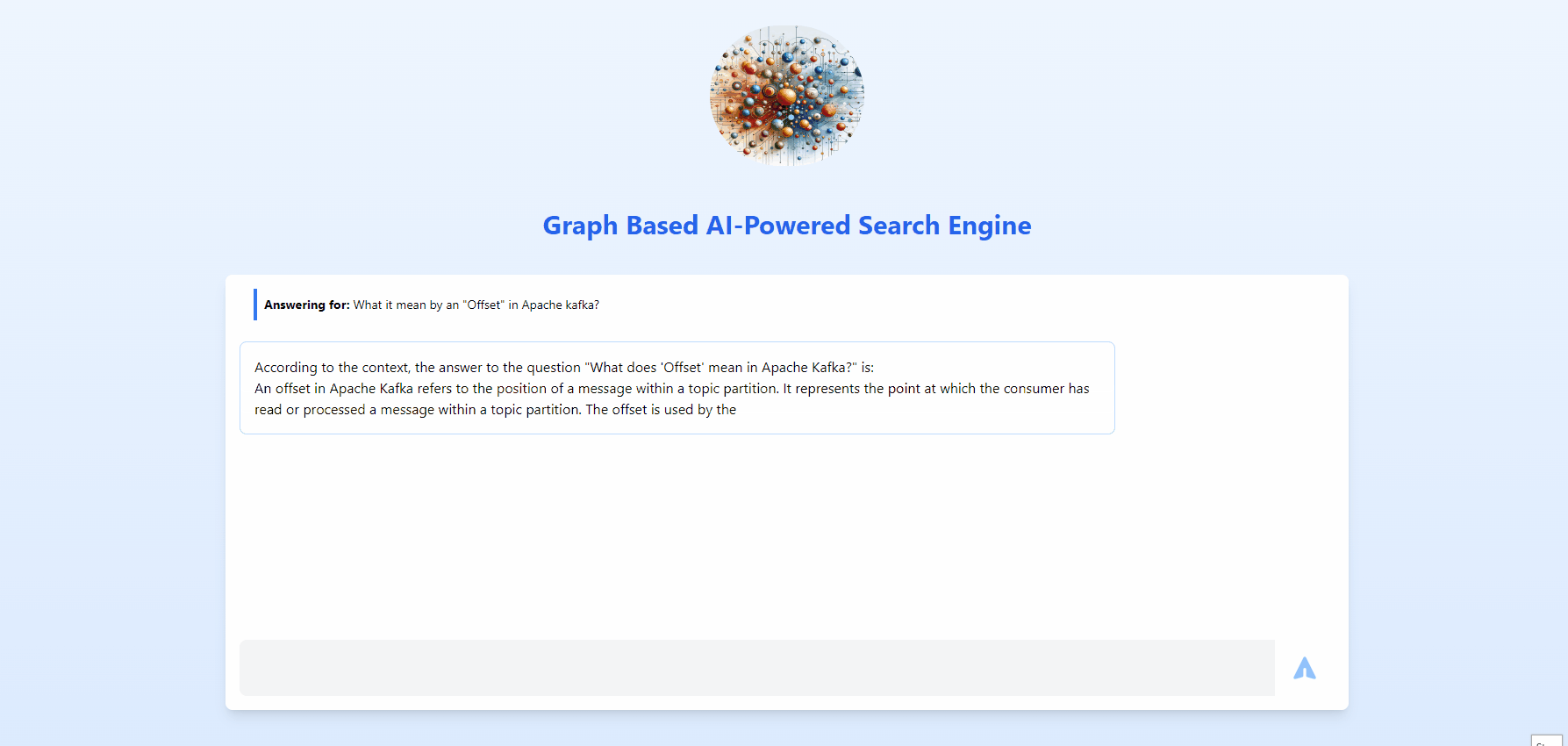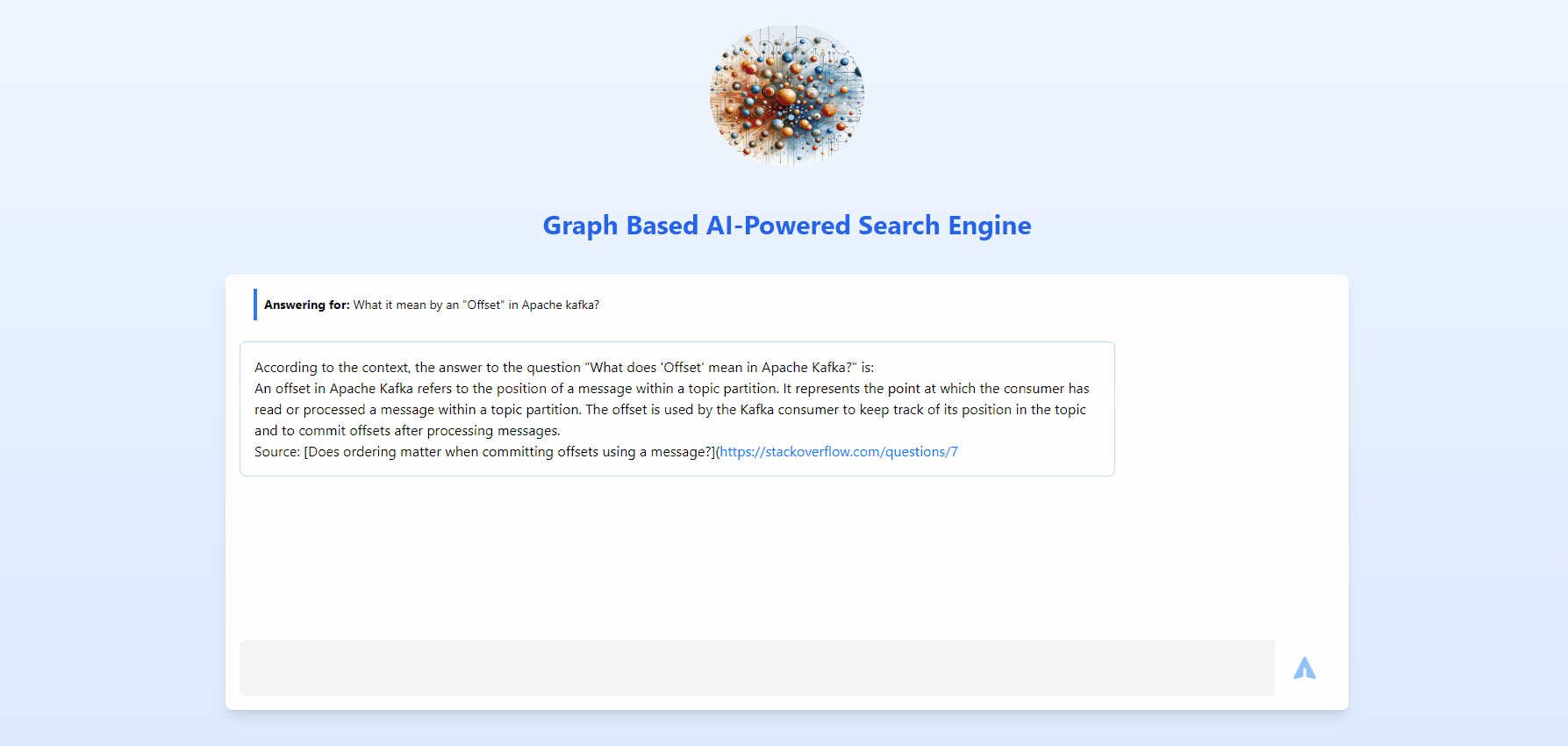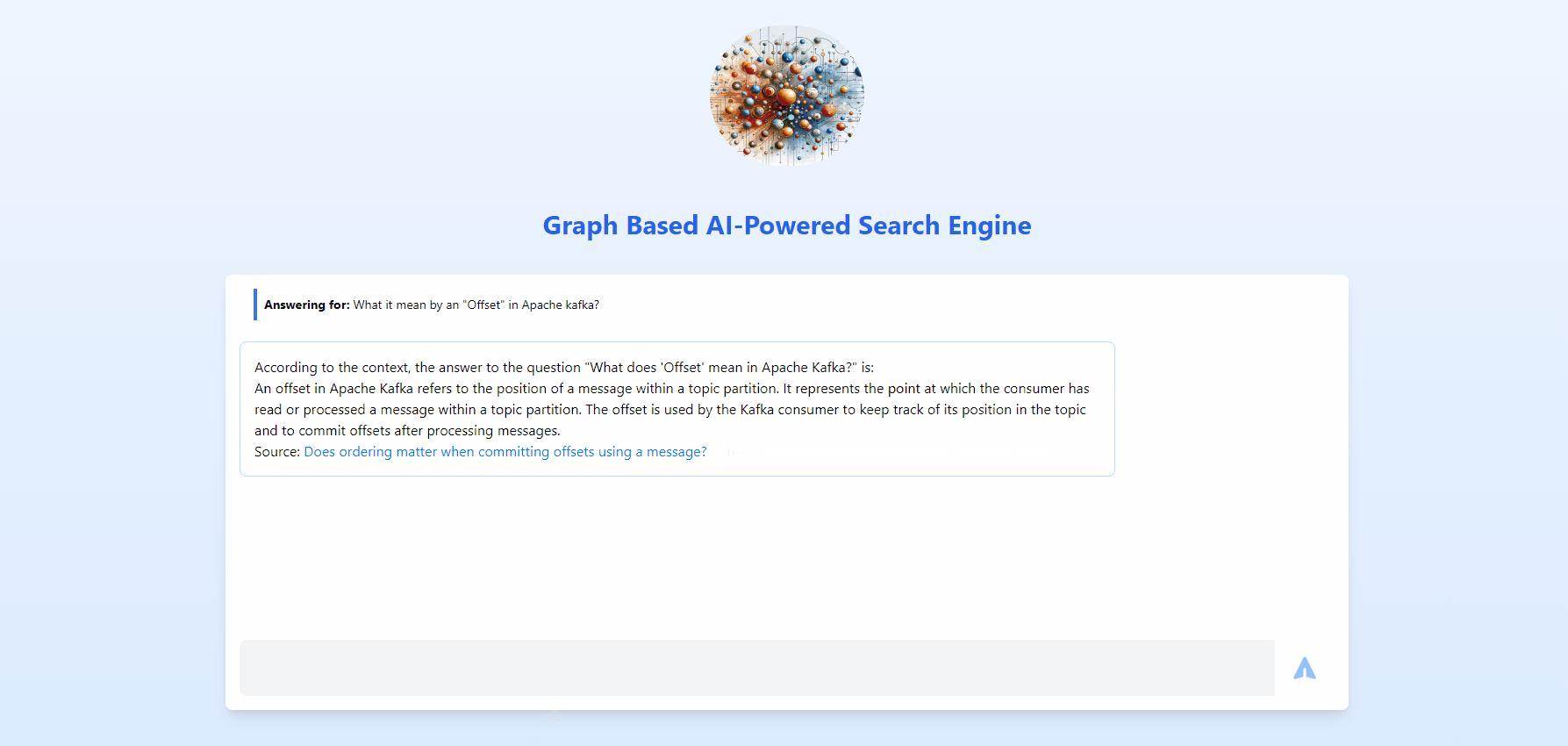
This is going to be an overview, if you need each and every detail with all concepts and modules spelled out, refer below list.
What was my objective ?
On the journey to build a graph-based AI-powered search engine, my goals were clear and simple. Firstly, I aimed to create a solution that didn’t rely on external services like OpenAI, opting instead for open-source tools. This decision ensured we had full control over the engine’s workings.
Next, I wanted to use the latest technologies available. By keeping up with the newest tools and frameworks, we could ensure our search engine was top-notch in terms of speed and accuracy, setting it apart from others.
Moreover, I wanted our engine to be easy to use and able to handle growing demands. This meant making it portable and scalable, capable of adapting to different setups and future needs without hassle.
How I approach it initially ?
To kickstart the project, I focused on building the engine’s foundation step by step. Firstly, I created modules using langchain to help the engine understand and process user queries and data. At the same time, I used lamaindex to organize data efficiently, making sure the engine could handle large amounts of information smoothly.
As the project progressed, I explored vector DB to improve how the engine stores and retrieves data. This helped make the search experience faster and more reliable. I also tried out different RAG techniques to refine how the engine generates search results. Alongside these efforts, I added distributors and API servers to the mix, allowing different parts of the engine to communicate seamlessly. This approach, focusing on building and refining each component, aimed to create a flexible and scalable search engine ready to adapt to changing needs.
What problem I faced, and did a new search for other solution
As I delved deeper into the project, I encountered several hurdles that prompted me to seek alternative solutions. Firstly, writing everything from scratch proved to be exceedingly time-consuming, hindering progress. Additionally, accuracy issues arose, impacting the reliability of the search results. Organizing data and establishing accurate relationships posed further challenges, complicating the engine’s functionality. Moreover, concerns regarding speed and scalability arose, casting doubt on the engine’s ability to handle increasing demands.
In response to these challenges, I started on a new exploration, leading me to discover the Gen AI Stack. This innovative solution offered a structured approach, streamlining the organization of data. Docker emerged as a valuable tool for scalability, facilitating seamless integration with various models to enhance the engine’s accuracy. The inclusion of langchain provided robust language processing capabilities, while the integration of neo4j significantly improved the accuracy of data relationships within the engine. With these new tools and frameworks at my disposal, I found it easier to overcome the challenges I had previously encountered, paving the way for a more efficient and accurate search engine.
“ If I have seen further than others, it is by standing upon the shoulders of giants “ — Sir Isaac Newton
So, how I piece it together ?
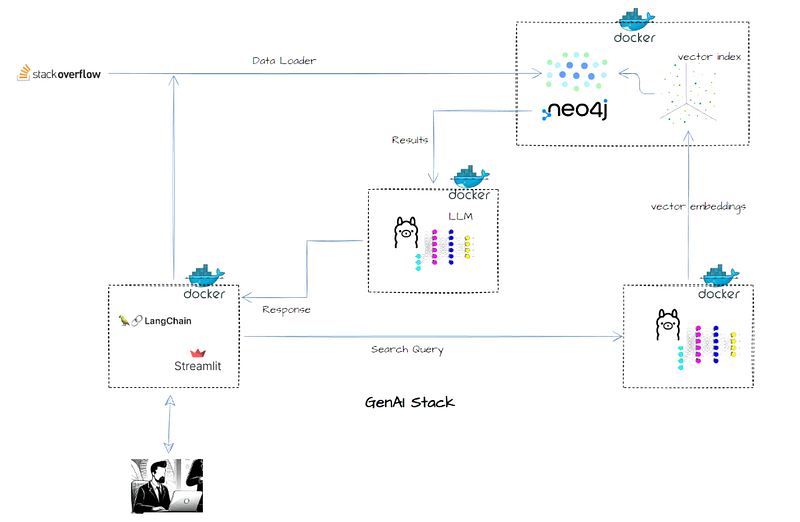
Read more about this here
What’s next ?
- Adding Distributor for Load Balancing : I’m determined to improve the engine by integrating a “Distributor” component. This will help balance the load across various models that I’ve developed earlier. By distributing the workload efficiently, the engine can handle more requests without slowing down. May be I shall use what I built before (ofc w/ further improvising it)
- Utilizing Rust for Model Serving : To optimize the performance of model serving, I’m considering using Rust, a programming language known for its speed and efficiency. By leveraging Rust, the engine can serve models faster and handle requests more efficiently. May be I shall use what I built before (ofc w/ further improvising it)
- Incorporating Multi-Modal Functionality : I plan to enhance the engine’s capabilities by adding support for multi-modal functionality. This means the engine will be able to understand and process different types of data, such as text, images, and videos, to provide more comprehensive search results.
- Introducing Cloud Support : Adding cloud support is on the agenda to make the engine more accessible and scalable. By integrating with cloud services, users can deploy the engine effortlessly and take advantage of cloud resources to handle varying workloads.
- Evaluating with RAGAs or LangSmith for Accuracy : To further improve the accuracy of the engine, I’m exploring the possibility of integrating evaluation tools like RAGAs or LangSmith. These tools will help track the engine’s performance over time and identify areas for improvement, ensuring that it continues to deliver accurate search results.





