
Machine Learning Art
How a neural network hallucinates houses from a single image

The synthesis of individual images has attracted much attention in computer vision and computer graphics. It brings a photograph to life by extrapolating beyond the input pixels and generating new pixels that follow the geometric structure of the scene. At the same time, the generated pixels must be semantically coherent with the existing pixels. Current methods for synthesizing views that learn a 3D geometric representation have shown promising results in generating high-quality new views. However, these approaches can only generate views within a limited range of camera motion. For example, it is a major challenge for current approaches to synthesize what is outside the door of the room.
Project Page (scroll down)
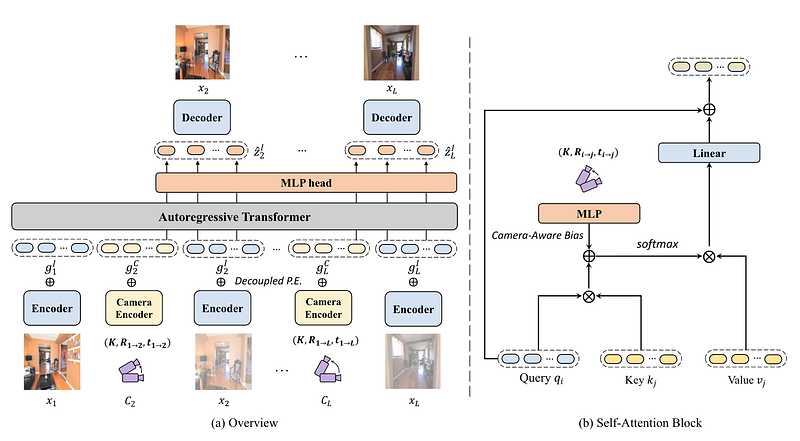
Novel view synthesis from a single image has recently attracted a lot of attention, and it has been primarily advanced by 3D deep learning and rendering techniques. However, most work is still limited by synthesizing new views within relatively small camera motions. In this paper, we propose a novel approach to synthesize a consistent long-term video given a single scene image and a trajectory of large camera motions. Our approach utilizes an autoregressive Transformer to perform sequential modeling of multiple frames, which reasons the relations between multiple frames and the corresponding cameras to predict the next frame. To facilitate learning and ensure consistency among generated frames, we introduce a locality constraint based on the input cameras to guide self-attention among a large number of patches across space and time. Our method outperforms state-of-the-art view synthesis approaches by a large margin, especially when synthesizing long-term future in indoor 3D scenes. During training, images and camera transformations are first encoded to modality-specific tokens. Tokens are then fed into an autoregressive Transformer that predicts images. During inference, given a single image and a camera trajectory, novel views can be generated autoregressively by using the Transformer. https://xuanchiren.com/pub/look-outside-door.pdf

Conclusion An autoregressive Transformer based model to solve novel view synthesis, especially when synthesizing long-term future in indoor 3D scenes. This method leverages a locality constraint based on the input cameras in self-attention to ensure consistency among generated frames. As a result, the process can improve performance in novel view synthesis compared to the state-of-the-art approaches. To conclude, the authors take a further step to explore the capabilities of geometry-free methods and manage to synthesize consistent high-fidelity 3D scenes.
@inproceedings{ren2022look,
title={Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image},
author={Ren, Xuanchi and Wang, Xiaolong},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
Project Page:
Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image
Xuanchi Ren, Xiaolong Wang
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai





