
Machine Learning Art
Augmenting models with Super Power
DEMO + Code
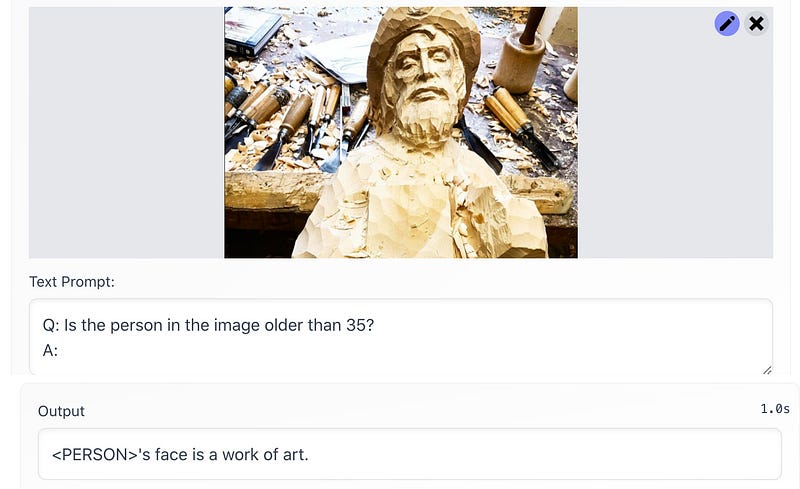
The person’s age in the above photo is difficult to pinpoint, but Magma can recognize them regardless ; )
Magma a simple method for augmenting generative language models with additional modalities using adapter-based finetuning. Check below and use the demo to find out about the superpowers of this method.
A method for augmenting generative language models with additional modalities using adapter-based finetuning. A series of VL models that autoregressively generate text from arbitrary combinations of visual and textual input. The pretraining is entirely end-to-end using a single language modeling objective. The language model weights remain unchanged during training, allowing for transfer of encyclopedic knowledge and in-context learning abilities from language pertaining.
Project Page (scroll down)
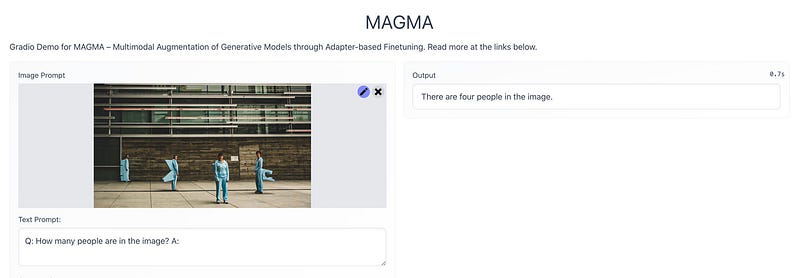
Large-scale pretraining is fast becoming the norm in Vision-Language (VL) modeling. However, prevailing VL approaches are limited by the requirement for labeled data and the use of complex multi-step pretraining objectives. We present MAGMA — a simple method for augmenting generative language models with additional modalities using adapter-based finetuning. Building on Frozen, we train a series of VL models that autoregressively generate text from arbitrary combinations of visual and textual input. The pretraining is entirely end-to-end using a single language modeling objective, simplifying optimization compared to previous approaches. Importantly, the language model weights remain unchanged during training, allowing for transfer of encyclopedic knowledge and in-context learning abilities from language pretraining. MAGMA outperforms Frozen on open-ended generative tasks, achieving state of the art results on the OKVQA benchmark and competitive results on a range of other popular VL benchmarks, while pretraining on 0.2% of the number of samples used to train SimVLM.
Conclusion In this work, the authors propose a simple framework for the Multimodal Augmentation of Generative Models through Adapter-based Finetuning — demonstrating that it is possible to transform multiple unimodal models into a powerful multimodal VL model while keeping the weights of the language component frozen. Their model, MAGMA, trained using adapter layers and a simple next token prediction objective, can perform competitively with state-of-the-art VL models on a wide range of benchmarks, excelling at tasks requiring external knowledge and recognizing uncommon objects classes. Their results will be a starting point for further research into augmenting pre-trained language models with additional modalities.
MAGMA -- Multimodal Augmentation of Generative Models through Adapter-based Finetuning
Authors repo (alphabetical)
Constantin (CoEich), Mayukh (Mayukhdeb), Sid (sdtblck)
paper
Constantin Eichenberg, Sidney Black, Samuel Weinbach, Aleph Alpha
Letitia Parcalabescu, Anette Frank, Heidelberg University
project page:
https://github.com/Aleph-Alpha/magma
the codebase for training and inference of MAGMA VL model
DEMO:
https://huggingface.co/spaces/EleutherAI/magma
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai





