
How Does a Dating App Handle New Profiles? (Part 1)
Using Unsupervised Machine Learning for New Dating Profiles

Dating Applications, such as Tinder, Bumble, Hinge, etc., incorporate their own unique algorithms to match users with one another. These algorithms are generally kept secret and away from prying eyes. But haven’t you ever wondered how these dating apps determined which profiles to show you at a given time? Why are specific dating profiles shown to you and how did the app determine that those profiles are ones you might like?
To answer these questions we will dive into the potential algorithms that these dating apps might use when dealing with a new user/dating profile. In order to understand these algorithms, we will need to develop our own dating algorithm with Unsupervised Machine Learning. The development of this algorithm and its application has already been covered in this article:
With this algorithm already developed and established for us, we can move on to understanding how this algorithm would be able to handle new data/profiles.
Unsupervised Machine Learning: Clustering
The way our dating algorithm was created was through the usage of Hierarchical Agglomerative Clustering to cluster together similar profiles with one another. Afterwards, these profiles would then be narrowed down to the top 10 similar or correlated profiles with each other. For example, any random profile within the dataset would be shown ten similar profiles from their respective cluster.
How these ten profiles were discovered is explained in the following article:
Now that every dating profile can find their own respective “Top 10” profiles with our dating algorithm, we can proceed to the next step — handling new profile data.
Dealing with a New Dating Profile
When it comes to dealing with new data for our unsupervised machine learning algorithm, there are two main approaches:
1. Clustering (again)
2. Classification Modeling
We will be splitting the process of both approaches over two articles.
Clustering (again)
For this first part we will explaining the process of including the new data into a clustering algorithm that we had already used previously. This approach requires the new piece of data, and in our case the new dating profile, to be introduced into the original dataset.
From there we will use the same clustering algorithm we had implemented before. In short, after we cluster the dating profiles with the new dating profile included we will have the cluster that includes our new dating profile.
Classification
The following article covers the classification portion:
Coding the New Dating Profile
To experiment with the process of including new data in our algorithm we will first have to create that new piece of data in the form of a dating profile. Let’s start with loading in some necessary libraries:
The DataFrames we loaded in are shown below:


After importing all the libraries and data we need, we can move forward with creating an interactive input section. This section would function as a very simple user interface that would require a user to write in a new bio for the new dating profile that we would include in our dataset.
Here we will create a new DF that contains the random numbers for the dating interests/categories. The bio will have to be inputted by the user. The simple interface would look like so…

After inputting some text for our bio, we will end up with a new row to include in the original dataset:

Now we have our new piece of data/dating profile to cluster.
Clustering the New Dating Profile
The first step in clustering our new dating profile will be to first append the new piece of data onto our original DataFrame:
# Appending the new data
new_cluster = raw_df.append(new_profile)After appending the new piece of data, the new DF will look like so…

Once we have our DF that includes the new dating profile, we can proceed just like before when clustering our dataset.
Preparing the Dataset for Clustering
To prepare the dataset for clustering, we will need to first scale, vectorize, then perform PCA on the dataset. (A more in-depth examination of this process was explained in the previous article.)
Scaling, Vectorizing, & PCA
In the code above, we will first be scaling only the dating categories using MinMaxScaler(). We scaled the data in order to optimize the clustering performance.
After scaling the dataset, we will then vectorize the bios in our dataset using CountVectorizer(). This will create a larger DF that contains over 100 new features/columns because of the new array of words.
With the scaled and vectorized DataFrame, we will then reduce the dimensionality of the dataset by using Principal Component Analysis — PCA(). This creates a new DataFrame for our clustering algorithm.
Hierarchical Agglomerative Clustering
In order to cluster our new dataset with the new dating profile, we will have to perform Hierarchical Agglomerative Clustering. To do so we must first find the optimum number of clusters for our dataset.
By looping through the amount of clusters to implement, we can find the optimum cluster count by evaluating them with a couple evaluation metrics. The evaluation metrics we will be using are: the Silhouette Coefficient Score and the Davies-Bouldin Score. To know the amount of clusters to use we will create a function the displays the scores for each evaluation metric.
Once we run our function, the following information will be displayed:
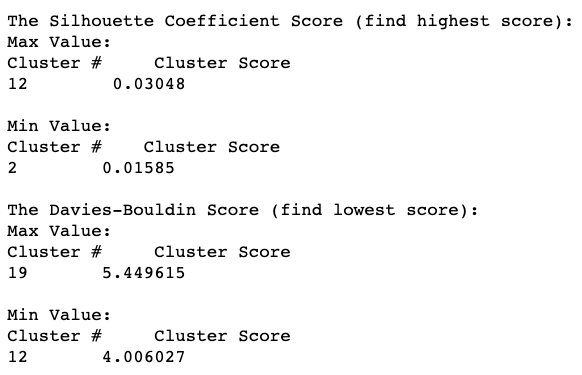
Based on these scores, the optimum number of clusters is 12.
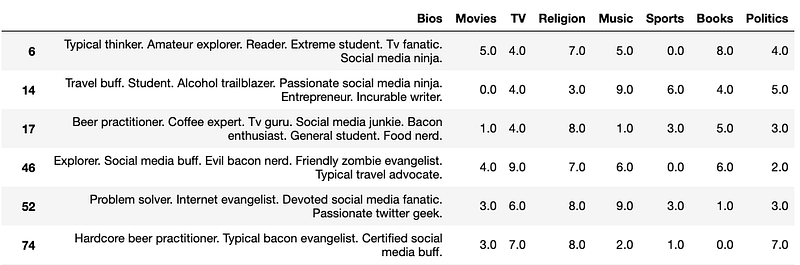
With the number of clusters determined for our clustering algorithm, we can find the cluster for our new dating profile and narrow down the DF to profiles clustered with our new dating profile.
Running the code above will display the DF of the profiles clustered with our new piece of data.
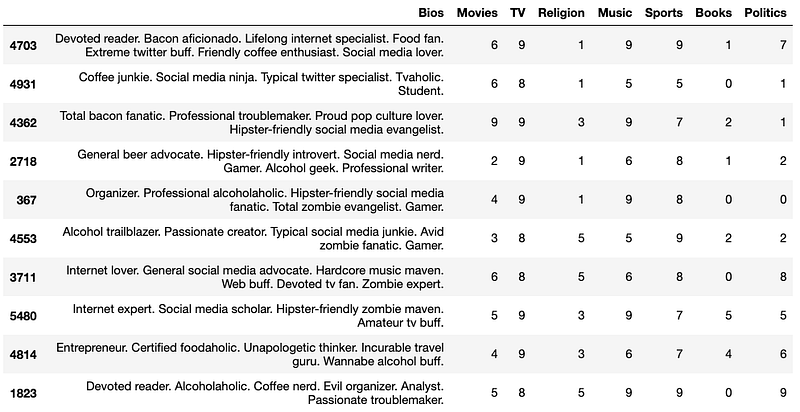
Finding the Top 10 Profiles for Our New Dating Profile
Here we will be doing a brief overview of the process to find the top ten profiles for our new dating profile.
In the code above, we have vectorized our clustered DF and found correlations between the profiles. From there we can find the top ten most correlated profiles to our own.
Next Step (Classification)
By using the same clustering algorithm again we have successfully clustered our new piece of data/dating profile and found the top ten most similar profiles to our own.
In the next article we will be using a machine learning classification model to classify our new data as an alternative to running the clustering algorithm again.





