
HER: How to Build an Effective Retriever for Next-Gen AI Systems (Artificial Contextual Intelligence)
The advent of large language models (LLMs) has enabled a new paradigm in AI system design — Retrieval Augmented Generation (RAG). By combining scalable text retrieval with the few-shot learning capabilities of LLMs, RAG frameworks allow dynamically tapping into vast knowledge sources. As detailed in this overview, this approach is unlocking next-generation conversational applications. Their ability to rapidly adapt and scale makes them far more flexible than static models.
In RAG pipelines, the retriever plays a crucial role. It must identify and retrieve the most relevant information to augment the LLM generator.
Optimizing the retriever holistically across metrics like accuracy, diversity, scale, and speed is key to unleashing the full potential of RAG systems.
This article provides a comprehensive guide to building a high-performance retriever optimized for RAG frameworks.
We cover strategies like hybrid retrieval, rankers, context optimization, efficiency improvements, and iteration loops. By bringing together techniques from information retrieval, model optimization, and more we can create the ideal retriever.
First, hybrid retrieval combines both sparse keyword-based methods like BM25 with dense semantic models based on contextualized embeddings. This provides both strong lexical signals and semantic matching ability. Next, adding a powerful ranker after initial retrieval can further refine relevance. Metadata optimization injects useful document attributes into the search process for personalization and precision.
To maximize what information is provided to the LLM generator, context diversity and strategic ordering ensure the retrieved passages are broad, focused, and positioned for easy attention. For large-scale corpora, efficiency optimizations like approximate indexes and model compression maintain speed and throughput. Finally, continual iteration based on monitoring, evaluation, and user feedback safeguards quality over long-term system usage.
By holistically addressing these aspects of the retriever, we can provide optimal knowledge retrieval and context for the LLM generator.
Well-designed retrieval will become increasingly crucial as RAG systems proliferate across applications.
The rest of this guide dives deep into techniques for each dimension. I will maintain it up-to-date.
I) Types of Retrieval Techniques
Keyword-based Retrieval
This is the most traditional form of information retrieval, often used in search engines like ElasticSearch. It is fast and efficient but lacks semantic understanding.
Embedding-based Retrieval
Semantic matching is the forte of embedding-based retrieval. Techniques like Dense Passage Retrieval (DPR) and Sentence Transformers encode queries and documents into vector embeddings for semantic matching.
Graph-based Retrieval
Knowledge graphs, like those used in Grakn or Neo4j, enable complex multi-hop reasoning. This allows for a deeper understanding and relationship between concepts.
Structured Databases
SQL databases and other structured data sources can be used for retrieval, especially when the information is well-organized and tabulated.
Advantages of Classical Retrieval Techniques
- Well-established: Decades of research have made these techniques reliable.
- Interpretable: Unlike some neural methods, classical approaches are often easier to interpret.
- Leverage Existing Databases: Organizations can use their existing databases efficiently.
- Lower Computational Costs: Compared to neural techniques, classical methods are often less computationally demanding.
II) Optimization in a RAG framework :
There are several strategies to optimize the retriever for a robust and efficient RAG pipeline:
1) Hybrid Retrieval
Combining both sparse lexical retrieval like BM25 and dense semantic retrieval using embeddings provides complementary signals to cover a broad range of query types. Sparse methods excel at keyword matches while dense retrievers capture semantic nuances.
bm25 = BM25Retriever(document_store=doc_store)
dpr = DensePassageRetriever(document_store=doc_store,
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base")
# Retrieve top 10 documents with each retriever
docs_bm25 = bm25.retrieve(query="What is BERT?")
docs_dpr = dpr.retrieve(query="What is BERT?")
# Merge results
from haystack.nodes import JoinDocuments
joiner = JoinDocuments()
docs = joiner.join(docs_bm25, docs_dpr)A hybrid approach combines the strengths of both sparse lexical models like BM25 and dense semantic models based on contextual embeddings.
Sparse Models
- BM25 and TF-IDF match query keywords directly to words in documents
- Work well for queries wanting specific facts, entities, or explicit mentions
- Excel when query and document share similar vocabulary
- No training required — can generalize to any domain
- Robust to out-of-vocabulary queries and named entities
Dense Models
- Encode words based on surrounding context, capturing semantics
- Match conceptual meaning rather than exact keywords
- Better for open-ended queries needing inference
- Require training on domain-specific data
- Struggle with named entities outside training data
Complementary Strengths
- Sparse provides strong signal for keyword matches
- Dense understands conceptual relationships
- Together they cover both lexical and semantic matching
Joint Models
- Approaches like COIL and ColBERT jointly optimize sparse and dense objectives
- Allows backpropagation into sparse lexical component
- Achieves both speed of sparse methods and accuracy of dense
- avoids pitfalls of completely end-to-end dense models
2) Optimization Techniques
a) Fine-tuning
Fine-tuning the retriever on domain-specific data can improve its performance and relevance significantly.
Fine-tuning large language models (LLMs) like BERT on domain-specific data is an effective technique to improve retrieval performance for that domain. The main approaches are:
- Fine-tune the entire LLM architecture: This allows the model to learn domain-specific representations. However, it is computationally expensive.
- Fine-tune only the query/document encoders: Less expensive than full fine-tuning. Enables the model to learn better document and query representations for the domain.
- Incorporate fine-tuned LLM in a RAG system: Fine-tune a small LLM on domain data. Use it as the retriever in a Retrieval Augmented Generation (RAG) system. Combines benefits of pre-trained LLM with fine-tuned domain knowledge.
The fine-tuning data can come from domain-specific QA datasets, relevance judgments, user feedback logs, etc. Typically thousands of examples are sufficient to see significant gains.
Other techniques like using domain-specific vocab, entity linking, and multi-task learning can further improve performance. Overall, fine-tuning even part of the LLM on domain data creates representations better suited for in-domain retrieval.
Frameworks like LlamaIndex and Haystack provide tools to efficiently fine-tune and incorporate LLMs in production retrieval systems.
#Fine-tuning dense retriever
# Load base DPR model
dpr = DensePassageRetriever(document_store=doc_store,
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base")
# Create training data
train_data = [
{"query": "What is BERT?", "positive_id": "doc_123"},
{"query": "How does BERT work?", "positive_id": "doc_456"}
]
# Fine tune on your data
dpr.train(data=train_data)b) Ranking
Using cross-encoder models like Sentence Transformers can further refine the relevance of the retrieved documents.
Adding a layer of cross-encoders after initial retrieval can further refine the relevance ranking before documents reach the generator. Powerful models like SentenceTransformers specialize in semantic similarity ranking.
Cross-Encoders for Ranking
- Cross-encoders process the document and query together rather than individually.
- This allows modelling interactions between the query and document text.
- Cross-encoders use attention to identify most relevant parts.
- They excel at semantic matching and relevance ranking.
Benefits as a Ranker
- More accurate than relevance scores from the initial retriever models.
- Refine the ranking given by first-stage retrievers.
- Put most pertinent documents at the top for the generator.
- Compensate for limitations of two-stage dense retrievers.
- Models like SBERT fine-tuned extensively for ranking.
Efficiency Tradeoffs
- Cross-encoders have higher latency as they process document-query pairs.
- This makes them unviable for initial large-corpus retrieval.
- Adding as final ranker limits the set of documents to re-rank.
- Smaller ranking batches increase throughput.
End-to-End Tradeoffs
- Two-stage systems (retriever + ranker) can have higher overall accuracy.
- But end-to-end dense retrievers like DPR avoid model switching.
- DPR uses special vectors during training to approximate ranking.
- So ranking is a useful bridge between stages in two-stage pipelines.
## Using Cross-Encoders for Re-Ranking
- Cross-encoder models like SentenceTransformers are powerful for semantic similarity ranking between a query and documents.
- They can be added as a re-ranking step after initial retrieval by methods like BM25, dense retrievers etc. This improves relevance of results.
- Cross-encoders take query and document simultaneously as input and output a similarity score. Computationally heavier than bi-encoders.
- Useful when working with small candidate sets (few hundred docs per query). Do not scale to large corpora.
- Pre-trained cross-encoders are available like ms-marco-MiniLM-L-6-v2 fine-tuned on passage ranking data.
- Can be fine-tuned on domain-specific data to get better performance.
- Work well with multi-stage retrieval systems — bi-encoders for candidate generation, cross-encoders for re-ranking top results.
- Significant gains observed over just bi-encoder retrieval in terms of metrics like MRR, NDCG@k.
Cross-encoders are a powerful technique for re-ranking candidate documents to improve retrieval relevance, especially when working with smaller result sets.
c) Context Window
Proper context curation and positioning amplifies the signal provided to the generator while reducing confusion. A strategic context window unlocks the full reasoning capacity of LLMs in RAG frameworks.
Using Haystack components like DiversityRanker and LostInTheMiddleRanker can help in selecting the most relevant and diverse paragraphs.
Diversifying the retrieved context reduces repetitiveness and provides broader coverage of concepts to the generator. The DiversityRanker maximises the diversity of retrieved passages.
Strategically ordering passages in the context window improves the generator’s ability to focus on the most relevant information. The LostInTheMiddleRanker prioritizes placing the strongest signals at the start and end.
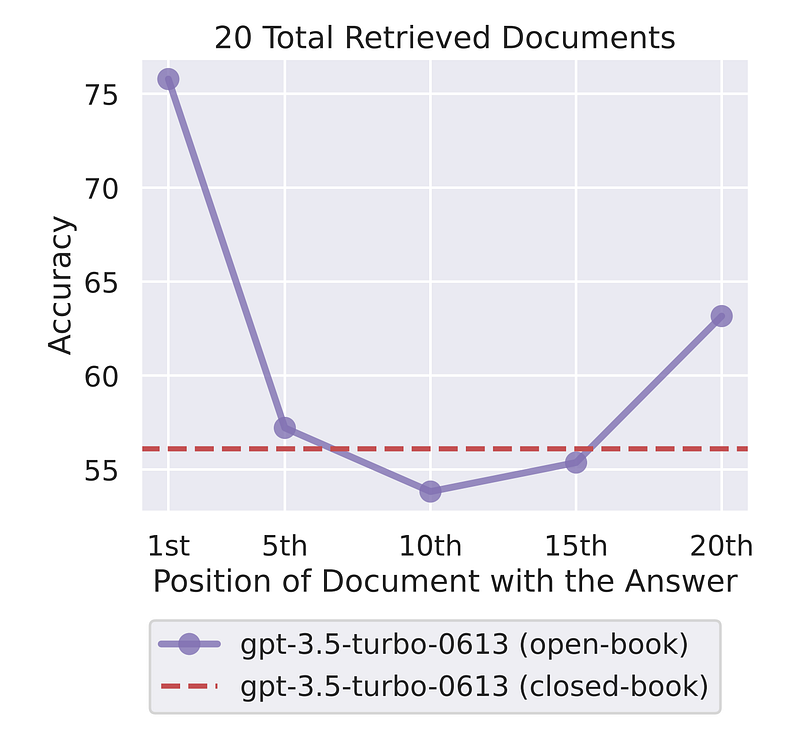
DiversityRanker
- Maximizes diversity of retrieved passages for broader context.
- Uses semantic similarity to minimize repetitive paragraphs.
- Prevents the generator from seeing multiple redundant passages.
- Provides greater coverage of concepts related to the query.
LostInTheMiddleRanker
- Prioritizes placing the most relevant paragraphs at the start and end.
- Pushes less important passages to the middle.
- Mitigates issue of generators focusing on start of context.
- Easy for model to reference key facts in prime positions.
Benefits
- Diverse paragraphs reduce repetitive signal.
- Prioritized order focuses model on key facts.
- Broad, focused signal improves reasoning.
- Guards against context window mismatches.
- Provides fuller picture to generator.
Caveats
- Diversity trades off some precision for coverage.
- Ordering could be further optimized, but complex.
- Additional ranking latency and parameters.
- Must balance diversity, order, relevance.
#Ranker
ranker = SentenceTransformersRanker(model_name_or_path="cross-encoder/ms-marco-MiniLM-L-6-v2")
docs = # retrieved by retriever
answers = ranker.run(query="What is BERT?", docs=docs)
from haystack.nodes import DiversityRanker, LostInTheMiddleRanker
diversity_ranker = DiversityRanker()
lost_in_middle = LostInTheMiddleRanker()
docs = # retrieved by retriever
diverse_docs = diversity_ranker.run(query=query, docs=docs)
ranked_docs = lost_in_middle.run(query=query, docs=diverse_docs)d) Preprocessing :
Effective document preprocessing is crucial for enabling accurate and efficient retrieval. Documents should be cleaned, normalized and split into coherent passages during indexing for optimal performance.
Cleaning involves steps like removing HTML tags, expanding contractions, fixing encodings and other normalization. This reduces “noise” and ensures documents are indexed correctly.
Splitting long documents into shorter passages improves retrieval because semantics are captured within smaller contexts. For example, splitting on sentences or paragraphs rather than arbitrary lengths retains contextual meaning.
preprocessor = PreProcessor(split_length=100,
split_overlap=50,
split_respect_sentence_boundary=True)This splits documents into 100 word passages with 50 word overlaps, retaining complete sentences. Overlapping provides context across passage splits.
The optimal segmentation strategy depends on your data and use case. Keyword-based retrievers can handle longer passages, while for dense retrievers, shorter segments within the model’s input length work better.
Regularly testing different splitting approaches and measuring the impact on relevant metrics like MRR is key to finding the best preprocessing for your needs. Improved retrieval also benefits downstream tasks like QA and summarization.
Thoughtfully indexing documents as cleaned, coherent passages provides a strong foundation for high-quality retrieval. Paying attention to preprocessing ensures your pipeline’s later stages have the optimal content to work with.
#IV) PreprocessDocument
from haystack.nodes import PreProcessor
preprocessor = PreProcessor(
split_length=100,
split_overlap=0,
split_respect_sentence_boundary=True,
clean_empty_lines=True,
clean_whitespace=True
)
doc_dir = "data/docs"
doc_index = "documents"
document_store = ElasticsearchDocumentStore(index=doc_index)
# Preprocess documents into smaller passages
for fname in os.listdir(doc_dir):
with open(os.path.join(doc_dir, fname)) as f:
document = document_store.write_documents(f.read())
passages = preprocessor.process(document)
document_store.update_document_meta(document.id, passages=passages)3) Metadata Optimization
Customizing keyword-based queries to incorporate document metadata can boost retrieval of pertinent results. For example, boosting recent articles for news queries, or favoring authoritative authors for scientific queries.
Metadata can significantly enhance the quality of retrieval. Types of metadata include:
- Temporal: Recency of the document
- Boolean: Features like paywalls or highlights
- Numeric: View counts or other engagement metrics
- Categorical: Tags like ‘Breaking News’ or ‘Featured Article’
#V) Boost with metadata
# Pass custom query to BM25Retriever
bm25 = BM25Retriever(document_store=document_store,
custom_query="""
{
"query": {
...
"functions": [
{
"filter": {"term": {"is_featured": true}},
"weight": 2
},
{
"filter": {"term": {"is_latest": true}},
"weight": 1.5
}
]
}
}
""")
#This boosts documents tagged as featured (weight=2) and latest (weight=1.5) in their metadata. Is_featured could also be numeric page rank.Sample Use Cases
- Boosting recent articles higher for breaking news queries
- Prioritizing academic papers from authors with higher h-index scores for science queries
- Pushing highlighted or featured articles to the top for generic searches
- Demoting paywalled content for queries where access is needed
- Favoring articles tagged as ‘Fact Checked’ or ‘In-Depth’ for research queries
Implementation
- Metadata fields need to be extracted and indexed alongside content.
- Keyword-based queries like BM25 can filter and boost based on metadata through constructs like function_score.
- Terms filters, range filters and boolean clauses filter while weight boosts incorporate as multipliers.
Benefits
-Provides additional contextual signals for relevance beyond just content.
-Query-understanding through metadata like dates and tags.
-Personalization through learned user preferences.
-Ability to adapt retrieval to context like access rights.
-Compensate for model relevance limitations.
4) Evaluation and Monitoring
It’s crucial to continually evaluate the performance of your retrieval system using metrics like Mean Reciprocal Rank (MRR) and recall@k. Monitoring the retrievals can provide insights into common failures and help in further training and optimization.
Evaluation metrics like Mean Reciprocal Rank (MRR) and recall@k are important for quantifying retrieval performance.
MRR measures the average rank of the first relevant result returned. It indicates how highly the system ranks positive results.
Recall@k measures the percentage of total relevant results returned in the top k documents. It quantifies coverage of retrieving all pertinent information.
Together, these metrics capture both precision (with MRR) and coverage (recall@k). Tracking them over iterations shows improvements from optimizations.
Monitoring retrievals
Logging and manually reviewing the paragraphs/documents returned by the retriever for sample queries provides qualitative insights.
Some techniques include:
- Spot checking retrievals for test queries — are they relevant and diverse?
- Looking for query types that commonly fail — are key concepts missed?
- Checking if context provides enough breadth to answer queries.
- Identifying repetitive or redundant passages.
- Reviewing queries with low MRR to understand ranking issues.
- Looking for passages that lead to hallucinated or incorrect answers.
Using insights to improve and optimize
Insights from retrieval monitoring can guide training and optimization:
- Failures indicate areas for improvement via additional training data.
- Repeated irrelevant passages can be flagged to exclude from indexes.
- Identifying struggles with semantics indicates need for dense retriever tuning.
- Lack of diversity suggests tuning passage splitting strategies during indexing.
- Low recall highlights need for expanded metadata to widen search.
6) Efficiency Optimizations
For large corpora, optimizations like approximate nearest neighbor indexes, compressed embedding models, and distributed inference minimize latency while scaling.
teacher_model = DensePassageRetriever(query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base")
student_model = DensePassageRetriever(query_embedding_model="distilbert-base-uncased-distilled-squad",
passage_embedding_model="distilbert-base-uncased-distilled-squad")
student_model.train(teacher_model) # distill knowledge from larger model
# Increase embedding batches
retriever = DensePassageRetriever(query_model=student_model.query_model,
passage_model=student_model.passage_model)
retriever.batch_size = 512 # raise batch size for faster processing
# Enable multiprocessing
retriever.use_gpu = True
retriever.use_multiprocessing = True
retriever.gpu_indices = [0, 1] # use 2 GPUs
# Can also use Predictor for multiprocessing
from haystack.pipeline import Predictor
predictor = Predictor(retriever, multiprocess=True, batch_size=512)
#This indexes documents optimized for writing speed. It compresses the dense retriever model using distillation. It maximizes passage embedding batches and enables multiprocessing via GPUs.Approximate Nearest Neighbor Indexes
Dense retrievers need to find the most similar passages to a query among a large corpus. Exact nearest neighbor search has linear complexity, becoming inefficient at scale.
Approximate methods like HNSW, IVFADC, and ANNOY find near matches much faster through graph traversal, clustering, and hashing approaches. Integrating these indexes cuts latency immensely for corpora over 100k docs.
Compressed Embedding Models
Large transformer models used for passage embeddings lead to high latency and memory costs. Model distillation can compress these down 10–100x smaller by training a compact student model to mimic a larger teacher model.
For example, a BERT-Large teacher of 24 layers (340M parameters) can be distilled down to a DistilBERT student with just 6 layers (82M parameters) while retaining over 97% of its accuracy.
Distributed Inference
Retrieves them in parallel on GPU clusters for massive speedup. Tools like ``` from huggingface hub allow distributing model inferencing across GPU nodes.
Caching
Caching passage embeddings avoids recomputing vectors for previously seen documents. This skips expensive model inference for known passages.
Async Indexing
Updating document indexes asynchronously in a separate thread avoids blocking query processing.
Together these approaches maintain fast response times, high throughput, and low costs even at large scale with hundreds of millions of documents. Optimizing the efficiency of large-scale RAG systems is crucial for real-world usage.
7) Using both a global and local retriever in a pipeline to improve context for retrieval
A global retriever is trained on a large, general corpus to provide broad coverage for queries. However, it may lack specificity when operating on a narrow domain.
A local retriever focuses on embeddings and semantics tailored to a specific document collection. However, it lacks the global context.
Combining them provides complementary benefits:
Global Retriever
- Provides general world knowledge for broad queries
- Helps identify topics and semantics relevant to the query
- Works reasonably well across many domains
- Compact since trained on large general corpus
Local Retriever
- Understands details and nuances within a specific corpus
- Excellent for queries requiring expert domain knowledge
- Much more memory/compute intensive as embeddings customized for narrow domain
A Combined Approach
- Use global retriever to identify generally relevant concepts
- Construct a subset corpus of documents flagged by global model
- Apply local retriever on this smaller, focused corpus
- Merge results from global and local retrievers
The global retriever provides the broad context to “scope down” to a relevant sub-collection. The local retriever then searches in-depth within this subset using custom embeddings tailored to the domain.
The global + local approach maximizes both the breadth (global) and specificity (local) of results. Each retriever compensates for the weaknesses of the other.
global_retriever = DensePassageRetriever(
document_store=global_doc_store,
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base"
)
# Local retriever focused on specific documents
local_retriever = DensePassageRetriever(
document_store=local_doc_store,
query_embedding_model="local_query_model",
passage_embedding_model="local_passage_model"
)
# Retrieve globally
global_results = global_retriever.retrieve(query="What is BERT?")
# Construct local corpus
local_corpus = [doc for doc in local_doc_store.get_all_documents() if doc.id in global_results]
# Update local doc store with relevant docs
local_doc_store.update_documents(local_corpus)
# Retrieve locally
local_results = local_retriever.retrieve(query="What is BERT?")
# Merge global + local results
all_results = merge_results(global_results, local_results)8) Continual Improvement
Monitoring retrievals and iterating based on manual reviews and user feedback identifies edge cases for improvement. Focused fine-tuning continually enhances retrieval quality.
Monitoring Retrievals
As discussed previously, logging and manually reviewing a sample of paragraphs retrieved for test queries provides qualitative insights into the strengths and weaknesses of the current retriever.
Some best practices include:
- Regularly spot checking retrievals after updates to monitor for regressions
- Tracking most common query types that fail
- Reviewing low MRR queries to understand ranking issues
- Looking for redundant or irrelevant paragraphs
- Identifying queries that lead to hallucinated answers
User Feedback
Logging user interactions and collecting explicit feedback also provide signals to further improve the retriever:
- User clicks on documents indicate good relevance judgement
- Time spent reading a document shows engagement
- Explicit ratings and tags highlight the quality of retrievals
- Feedback can be used to generate more training data
Focused Fine-tuning
The insights gathered can guide targeted fine-tuning of the retriever model:
- Additional training data fixes blind spots
- Specialized tuning on failing queries improves that subdomain
- Regular fine-tuning maintains quality as indexes scale up
Continuous Integration
Evaluation metrics and monitoring should be made part of the CI process to catch regressions early. New models can be A/B tested before full deployment.
Regular Iteration
There is no “end state” for the retriever. Continuously integrating improvements through iteration and testing is key to maintaining optimal quality as use cases evolve.
Conclusion :
Optimizing neural retrievers is key to unleashing the full potential of large language models in RAG frameworks. By holistically addressing accuracy, diversity, scale, and latency, an efficient retrieval stage provides the optimal knowledge source for downstream generators.
Hybrid retrieval combines complementary lexical and semantic signals for high recall across query types. Strategic document preprocessing and metadata boosting further enhance the precision and coverage of results. Cross-encoder rankers and optimized context ordering refine relevance for the generator. And continual monitoring, evaluation and iteration safeguard long-term quality.
While dense neural retrieval models open up new capabilities, effectively incorporating them into a robust pipeline requires care and optimization. By following best practices around evaluation, efficiency, metadata and more, the retriever can provide the ideal context for reasoning.
As RAG paradigms spread across applications, well-designed retrieval will only grow in importance for utilizing the strengths of large language models. A high-performance retriever is the linchpin enabling these next-generation AI systems to dynamically tap into vast knowledge and handle multifaceted information needs.

Sources :
https://arxiv.org/abs/2308.03103 https://gpt-index.readthedocs.io https://haystackburgers.com https://arxiv.org/pdf/2308.03103.pdf https://bootcamp.uxdesign.cc/llamaindex-last-version-from-basics-to-advanced-techniques-in-python-part-4-59ddd8d92572 https://www.haystackteam.com https://www.reddit.com/r/LanguageTechnology/comments/11sxkj0/fine_tune_bert_for_domainspecific_information/ https://levelup.gitconnected.com/llamaindex-last-version-from-basics-to-advanced-techniques-in-python-part-1-3036458dc215 https://thehaystackapp.com https://readmedium.com/practitioners-guide-to-fine-tune-llms-for-domain-specific-use-case-part-1-4561714d874f https://towardsdatascience.com/llamaindex-the-ultimate-llm-framework-for-indexing-and-retrieval-fa588d8ca03e https://www.haystack.tv https://blog.ml6.eu/leveraging-llms-on-your-domain-specific-knowledge-base-4441c8837b47 https://medium.datadriveninvestor.com/llamaindex-last-version-from-basics-to-advanced-techniques-in-python-part-2-e9dbc828ceb https://www.haystack.vc https://haystack.deepset.ai/tutorials/02_finetune_a_model_on_your_data https://pub.towardsai.net/llamaindex-last-version-from-basics-to-advanced-techniques-in-python-part-3-c3031acb4ee4 https://en.wikipedia.org/wiki/Haystack_(food) https://aclanthology.org/2020.semeval-1.44.pdf https://www.datacamp.com/tutorial/llama-index-adding-personal-data-to-llms https://www.pinecone.io/learn/series/nlp/retriever-models/ https://www.linkedin.com/posts/llamaindex_building-performant-rag-applications-for-activity-7102748604099964928-EvrA
https://www.sbert.net/examples/applications/cross-encoder/README.html https://www.sbert.net/docs/usage/semantic_textual_similarity.html https://www.sbert.net/examples/applications/retrieve_rerank/README.html https://huggingface.co/tasks/sentence-similarity https://www.sbert.net/docs/package_reference/cross_encoder.html https://towardsdatascience.com/semantic-similarity-using-transformers-8f3cb5bf66d6 https://www.sbert.net/docs/pretrained_cross-encoders.html https://towardsdatascience.com/bert-for-measuring-text-similarity-eec91c6bf9e1 https://huggingface.co/cross-encoder/ms-marco-MiniLM-L-6-v2 https://readmedium.com/hard-mining-negatives-for-semantic-similarity-model-using-sentence-transformers-c3e271af6c25 https://blog.vespa.ai/improving-product-search-with-ltr-part-two/ https://readmedium.com/semantic-search-with-s-bert-is-all-you-need-951bc710e160 https://weaviate.io/blog/cross-encoders-as-reranker https://www.vennify.ai/semantic-similarity-sentence-transformers/ https://www.pinecone.io/learn/series/nlp/sentence-embeddings/



