Hard-Mining Negatives for Semantic Similarity Model using Sentence Transformers

Semantic Similarity
Semantic Similarity is the task of evaluating how similar two texts are in terms of meaning. It plays a vital role in an information retrieval pipeline, whether it is product matching in eCommerce or finding a relevant document for a query.
In product matching of eCommerce, matching relevant or exact products from different eCommerce websites will provide valuable insights into pricing data, market dynamics, and competitor practices.
Training a semantic textual similarity model on eCommerce data helps us to retrieve exact or relevant products by extracting the information from the brand, title, specification, and description of the products. However semantic models suffer from the lack of availability of informative negative examples for model training.
What are actually informative negative samples or hard negatives and how do they help in the training of the model?
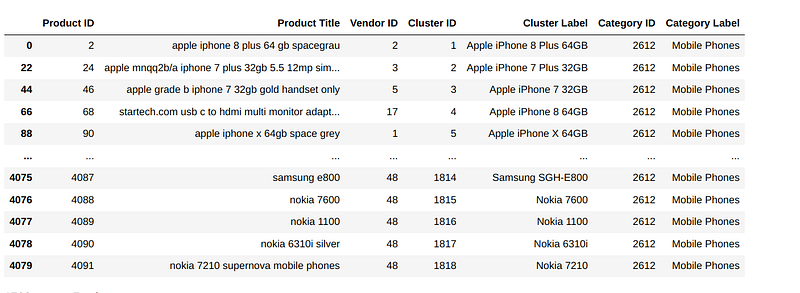
Let's say we have eCommerce product matching task and we have only true labels in our data like the following kaggle dataset which contains only matching product title pairs. The dataset does not provide us with dissimilar pairs because the data was scraped from price comparison websites and they only contain matching pairs. From now on we will be addressing, matching product title pairs as anchor-positive pairs. Where ‘apple iphone 8 plus 64gb’ is an anchor and ‘apple iphone 8 plus 64 gb spacegrau’ will be it's positive.
We can train a semantic similarity model using only anchor-positive pairs with Sentence Transofrmer framework with MultipleNegatives RankingLoss (MNR) Loss. Please check out how Sentence Transformer Library can be used for building better semantic models than other techniques like using a BERT encoder. Training or fine-tuning a semantic similarity model using a sentence transformer is pretty simple with few lines of code.
# Training or Fine Tuning a sentence transformer model with MNR Loss
from sentence_transformers import SentenceTransformer, losses, InputExample
from torch.utils.data import DataLoader
# where all-MiniLM-L6-v2 is a pre-trained sentence-transformer model
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
train_examples = [InputExample(texts=['Anchor 1', 'Positive 1']),
InputExample(texts=['Anchor 2', 'Positive 2'])]
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=32)
train_loss = losses.MultipleNegativesRankingLoss(model=model)
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100)In MNR Loss, for each anchor, it uses all other positives as a negative sample. Here (a1, p1) will be the positive pairs, and p2, p3, and p4 (positive of other anchors) will be made as a negative sample.
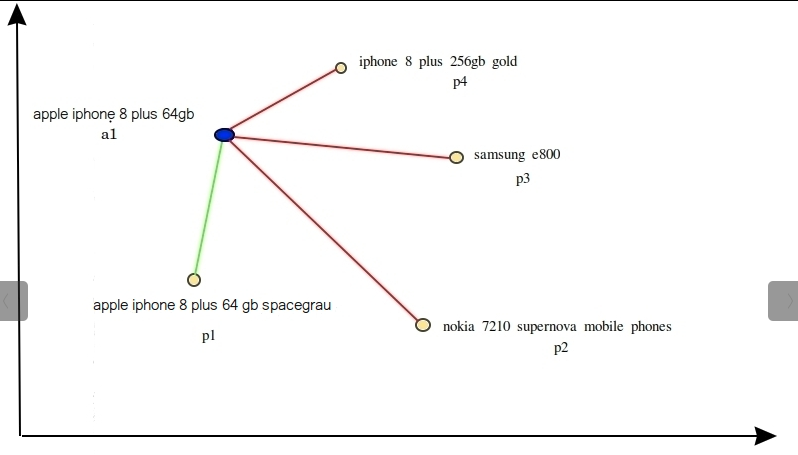
One of the issues with this random assigning or generation of negatives is that model trained using only random negatives, places two dis-similar queries closer to each other in the embedding space, especially when such queries have shared tokens.
Also, hard negatives samples give better performance than random negatives for semantic similarity as detailed by Nils Reimers in the following video.
“A hard-mined negative sample is the one which is similar to anchor but not an exact match with anchor”.
For “apple iphone 7 32gb’” the hard negative sample will be “apple iphone 7 256gb product red’”, since both are similar but not an exact match due to different storage sizes. So it is better than a random negative sample like “samsung -e800” or “nokia 7210 supernova mobile phones”. It will give us a better generalization and performance in identifying the relevant products in the product matching pipeline.
After the generation of hard negatives, we can train our model using Triplet Loss
Given a triplet of (anchor, positive, negative), the loss minimizes the distance between anchor and positive while it maximizes the distance between anchor and negative
loss = max(||anchor — positive|| — ||anchor — negative|| + margin, 0) , where margin is an important hyperparameter and needs to be tuned respectively.
# Training or Fine Tuning a sentence transformer model with Triplet Loss
from sentence_transformers import SentenceTransformer, SentencesDataset, LoggingHandler, losses
from sentence_transformers.readers import InputExample
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
train_examples = [InputExample(texts=['Anchor 1', 'Positive 1', 'Negative 1']),
InputExample(texts=['Anchor 2', 'Positive 2', 'Negative 2'])]
train_dataset = SentencesDataset(train_examples, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=train_batch_size)
train_loss = losses.TripletLoss(model=model)
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100)Mining Hard-Negatives using a naive and simple approach
There are several approaches for generating informative negative samples, like the one which is detailed in the latest paper of amazon science Beyond hard negatives in product search: Semantic matching using one-class classification (SMOCC).
But here, we are following a naive and simple approach to generate hard negative samples with the help of sentence transformer model embeddings and intuitive cosine similarity thresholds. Duplicates were removed from the dataset to avoid the chance of duplicated positive pairs.

Our primary motive is to find the most similar positive sample (from other anchors), which is not an exact match by comparing the cosine similarity of sentence embeddings. We will be using the pre-trained sentence transformer model all-MiniLM-L6-v2 for generating the embeddings for our sentences. Let's dive into code.
from sentence_transformers import SentenceTransformer, util
import numpy as np
class HardMineNegatives():
"""
Hard-mining Negatives for training a semantic similairty task with Triplet Loss.
Here we find the nearest negatives of a query in a search pool
by using sentence transformer model embeddings and cosine similarity ratio.
param: model_path: path of sentence transformer model
param: search_max_threshold: maximimum cosine similarity ratio
param: search_min_threshold: minimum cosine similarity ratio
param: search_limit: total length of data in which we want to search, only if search pool length is very high
param: top_n_results: number of top nearest negative to be returned, default is 1
"""
def __init__(self, model_path: str, **kwargs):
self.model = SentenceTransformer(model_path)
self.search_max_threshold = kwargs['search_max_threshold'],
self.search_min_threshold = kwargs['search_min_threshold']
self.search_limit = kwargs.get('search_limit')
self.top_n_results = kwargs.get('top_n_results') if kwargs.get('top_n_results') else 1
def get_hard_mined_negatives(self, anchor: str, search_pool:np.ndarray):
"""
to retrieve embeddings from sentence transformer model for anchor and sentences in search pool,
find the cosine similairty ratio between the anchor and search pool sentences,
apply search thresholds and return the top nearest negatives based on the highest
cosine similarity scores.
if no data is found in between the self.search_max_threshold and self.search_min_threshold ratios,
we will take the results between 0 and less than self.search_min_threshold ratios (this is an extreme case)
param: anchor: source text to which we need to find the nearest negative
param: search_pool: numpy array of sentences from which
we need to find the cosine similarity ratios with the anchor.
any meta value for sentences can be given after next index of
sentence, in the form
search_pool = array([
['apple iphone 8 256 gb gold', "mobile", "1001"],
['apple iphone 7 plus 32gb silver', "mobile", "1002"]])
where "mobile", "1001" are meta values,
the returned results will contain the respective cosine similarity
ratio at the last index of each sentence array
result = array([
['apple iphone 8 256 gb gold', "mobile", "1001", 69.5],
['apple iphone 7 plus 32gb silver', "mobile", "1002", 70.5]])
where 69.5 and 70.5 are cosine similarity ratios.
"""
self.search_limit = self.search_limit if self.search_limit else search_pool.shape[0]
search_pool = search_pool[: self.search_limit]
# shuffle data to search in random pool of data, in case of search limit less than the total length
np.random.shuffle(search_pool)
sentences = [anchor] + [row[0] for row in search_pool]
embeddings = self.model.encode(sentences, convert_to_tensor=False)
source_vector = embeddings[0]
# calculate the cosine similairty with the other sentences in search pool
similarity = [round(util.cos_sim(source_vector, embed).numpy()[0][0]*100, 2) for embed in embeddings[1:]]
similarity = np.array(similarity)
negative_indices = np.where((similarity <= self.search_max_threshold) & (similarity >= self.search_min_threshold))
if not negative_indices[0].shape[0]:
negative_indices = np.where((similarity < self.search_min_threshold) & (similarity >= 0))
negative_indices = negative_indices[0]
# take respective selected indices
search_pool = np.take(search_pool, negative_indices, axis=0)
similarity = np.take(similarity, negative_indices, axis=0)
# reshape to concatenate with meta values of search pool
similarity = similarity.reshape(-1, 1)
# concat the ratio to the meta values of search pool
search_pool = np.concatenate((search_pool, similarity), axis=1)
# sort the data in descending order
search_pool = search_pool[search_pool[:, -1].argsort()][::-1]
return search_pool[:self.top_n_results]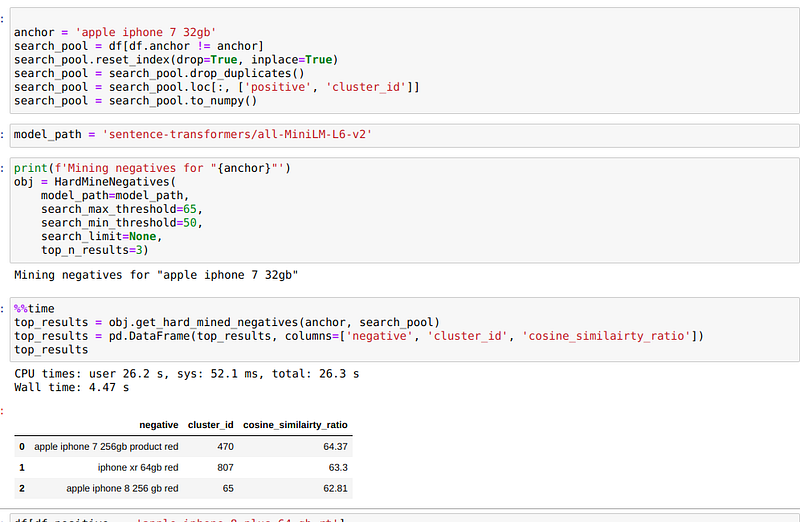
For anchor ‘apple iphone 7 32gb’, we search the negatives in other positive data as in the above code. We got great results like ‘apple iphone 7 256gb product red’ and ‘apple iphone 8 256 gb red’ which are similar and not an exact match (like Virat Kohli doppelgangers 😀). So here we searched for the top 3 similar sentences that have a cosine similarity ratio between 65 and 50.
Other Examples
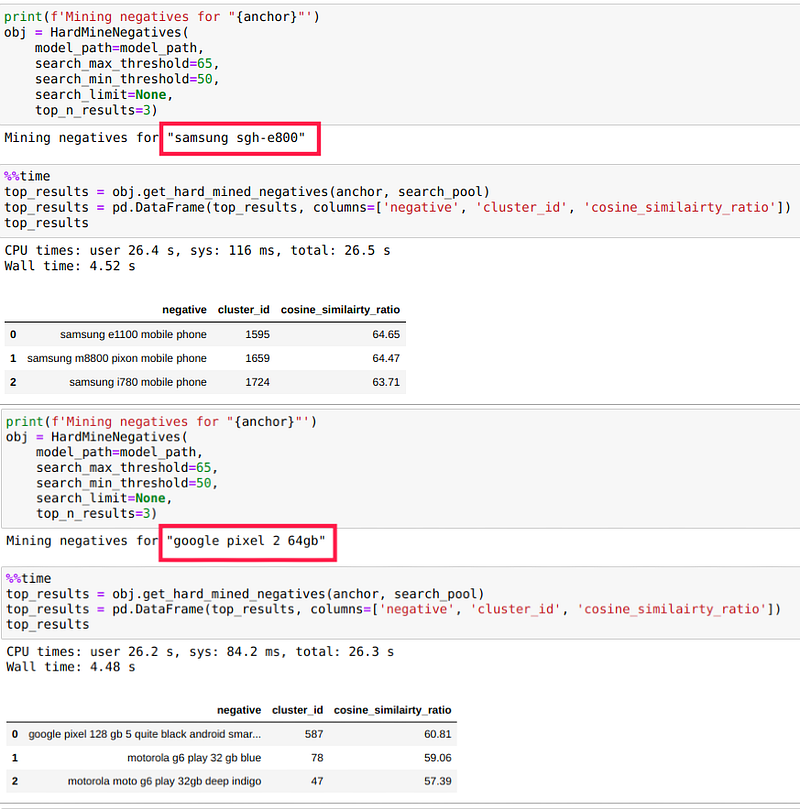
Why we chose a cosine similarity ratio between 65 and 50?
Choosing 65 as a maximum and 50 as a minimum threshold is a rule-based decision or task-specific. Since the sentences that are above 70 or 80, or 90 may contain samples that are an exact match (outliers in data), even if we have unique anchor pairs like the following case.
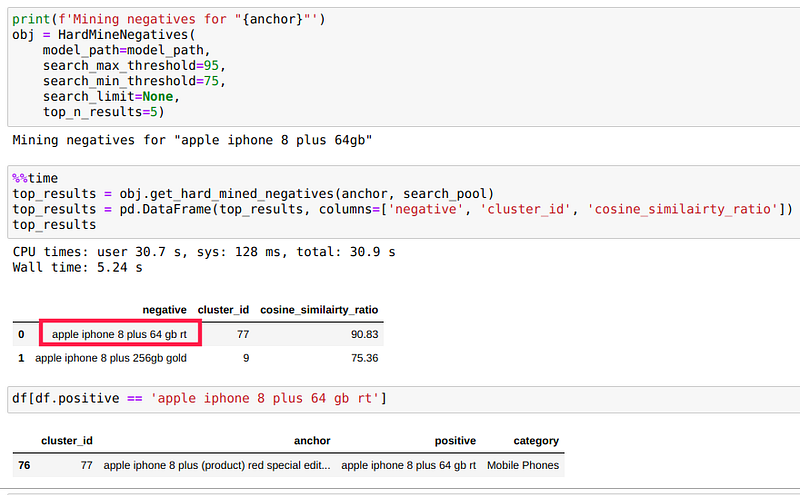
When we set 95 as a maximum threshold and searched for top similar negative samples we got `apple iphone 8 plus 64 gb rt`, a relevant product to anchor ‘apple iphone 8 plus 64gb’. These negative samples can hinder the model performance if their count is high in the training data.
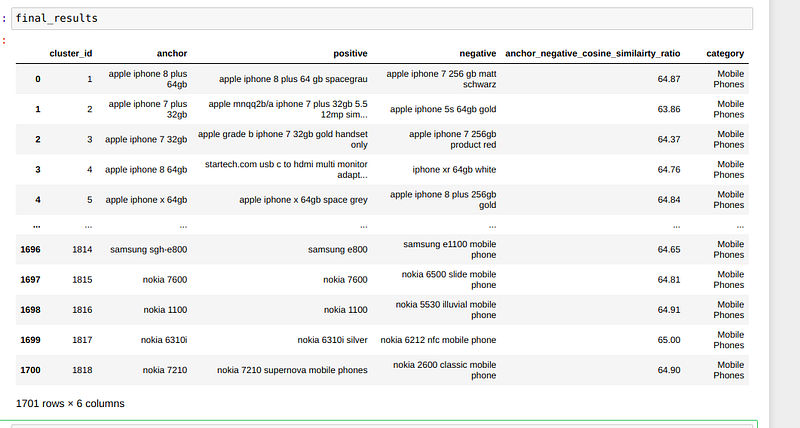
Running whole rows in the CPU had latency issues so I ran the code in the following Kaggle notebook with GPU. So the final results we got are
Conclusion
After mining the negatives we can merge the data to the kaggle dataset and train our model using Sentence Transformer with Triplet Loss as Loss function. All training steps are detailed in the official documentation of Sentence Transformers.
In real-world product matching problems we won't be using title alone for mining hard negatives, we will be using brand, title, specification, and description for the generation of better informative samples. Also, here we took only one category for mining ie `Mobile Phones`. When we have more category data it is preferred to search for negatives in the respective categories since they have the highest probability of having better hard negatives. ie category `Cameras` may not generate better negatives for `Mobile Phones`. It also saves the latency in searching the hard negatives in the search pool.
Please let me know in the comments if you find this article useful and feel free to mention any corrections which I need to make in the future. You can reach out to me on my Linkedin profile
Thanks for reading 😊





