
Google Finally Did It! Gemini 1.5: Best AI Model! Everything you need to know about!
Gemini 1.5 might be the tipping point changing the AI game in 2024! Since the release of ChatGPT in November 2022, Google found itself lagging in the AI race. OpenAI went from zero to more than a billion-dollar revenue in less than a year; meanwhile, Google is still struggling to position itself as a viable alternative. And that’s about to change!
Gemini 1.5 Pro emerges as a model with unique capabilities compared to other models!

TL ; DR
A couple of months after announcing its family of Gemini models, Google announced the release of a new 1.5 version!
This new version, of Gemini models, incorporates all the recent advancements in AI, significantly enhancing the performance of its models.
- It’s a Mixture of Experts, inspired by Mistral’s success.
- It’s multimodal, handling Text, Images, Video, and Audio.
- It has been tested with up to 10M token contexts, whereas, for reference, GPT-4 Turbo has a 128k token context.
- The model boasts near-perfect retrieval ability over large contexts — a big deal!
This leads to Gemini Pro 1.5 performing on the same level as Gemini Ultra!
It does come with some limitations as well, that we highlight in this blog post as well!
Very exciting! Let’s dive into it!
Links:
Gemini 1.5 — A Sparse Mixture of Experts
Gemini 1.5 is not just an incremental update; it’s combination of architecture improvements and optimization!
Gemini 1.5 — A Sparse Mixture of Experts (SMoE): This approach allows models to utilize the specialized capabilities of various smaller models or “experts,” each excelling in different aspects of data processing. The key benefit of this method is its ability to navigate complex language tasks with high precision, by selectively engaging only the most relevant experts for each specific input. This not only enhances the model’s efficiency and performance but also reduces computational overhead, making it a promising direction for future AI developments.
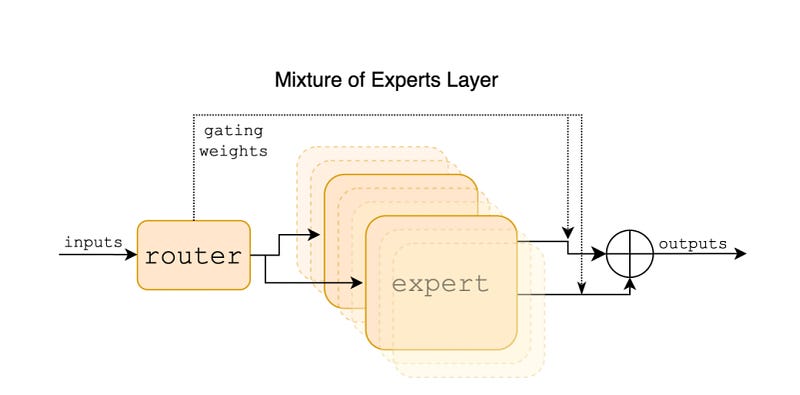
Thanks to this approach: This mid-size multimodal model, aka Gemini 1.5 Pro, matches the performance of its predecessor, 1.0 Ultra (thus surpassing GPT-4!), while requiring less computational power, setting a new standard for AI efficiency and effectiveness.
Gemini 1.5 — Multimodal with up to 10M Token Context!
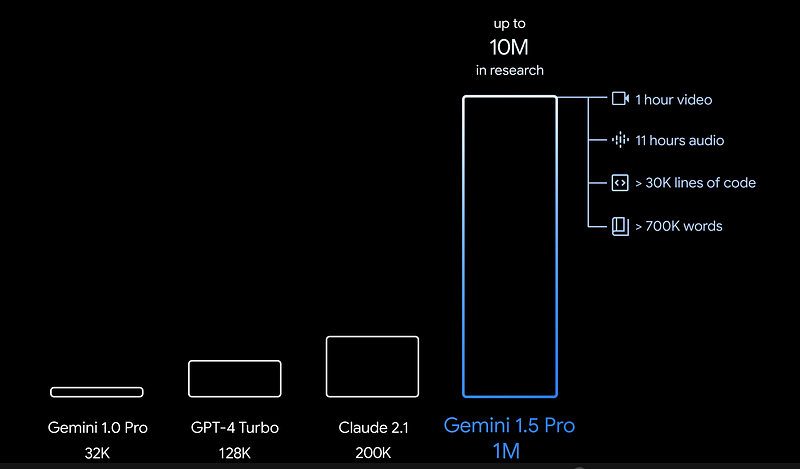
Size of context window available on the market
The size of the context window significantly influences the amount of information a model can process when responding to a query.

A reasonable approximation is to equate 1000 tokens to roughly 750 words, which corresponds to approximately one and a half pages of text. Consequently, with a 32k token context, the model is capable of managing content equivalent to around 48 pages. In contrast, GPT-4’s expansive 128k token context window substantially enhances this capability, enabling the model to process entire books, with the potential to cover texts up to 200 pages in length. This vast context window allows for more comprehensive understanding and analysis of lengthy documents, making GPT-4 adept at handling complex and detailed inquiries that require deep contextual awareness (i.e., full code repo or legal context, etc.).
Gemini 1.5 Pro released with 1M token context with better reasoning across modalities!
In its blog post Google announces Gemini 1.5 Prowith 1M token context (and up tested with up to 10M context window!).
What does it represent?
- 1 hour of video
- 11 hours of audio
- 32k lines of code
- 700k words (i.e., 1000 pages!)
Being the only real multimodal model on the market today, Gemini 1.5, offers a wide range of applications that were until now simply impossible!
Let’s look at the video analysis case. Previously we would need to get the transcript of the video and run it through an LLM to query it. Obviously a tremendous amount of information would be lost in the process.
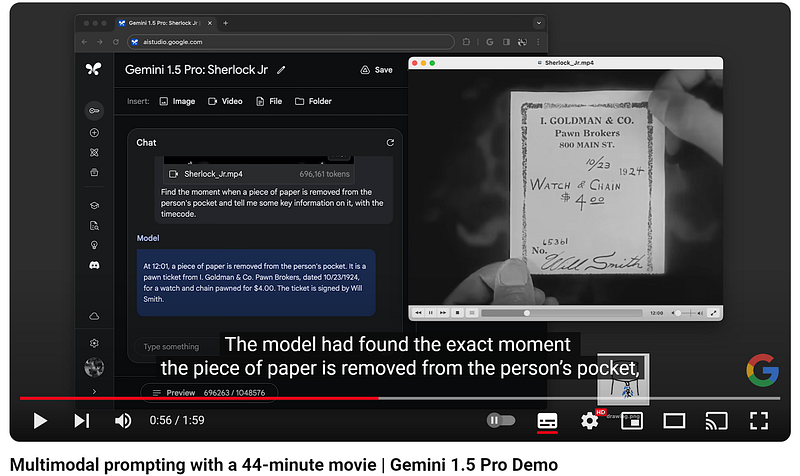
Now let’s look at this example highlighted by Google in its blog post!
The model successfully located a specific moment in the video, taking approximately one minute to deliver its response, which included the precise timestamp to locate the described scene.
It’s worth emphasizing again: Gemini 1.5 Pro currently stands as the sole model equipped to manage these types of tasks !
Information Retrieval Capabilities — RAG Killer?
Near perfect retrieval across modalities even at large context windows!
Returning to practical scenarios that can affect all businesses, prior research indicated that models often struggle with long context windows, tending to overlook much of the information in the middle and focusing primarily on the initial and final parts of a prompt.
These scenarios are especially relevant for intent and data extraction from documents or various inputs, showcasing their significance in practical applications.
How does Gemini 1.5 Pro perform in this regard?
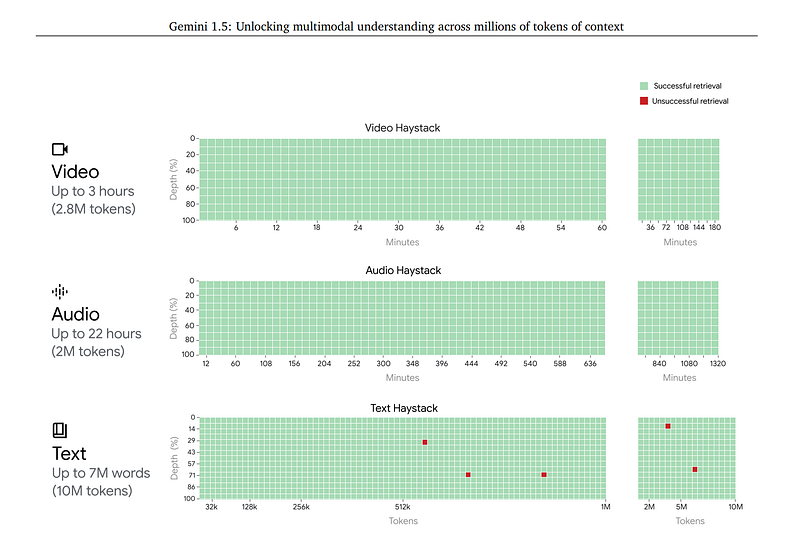
In the image above, we see Google Gemini’s ability to reason and extract information across modalities.
The reported results highlight a near perfect retrieval across modalities even at large context windows!
Prompting a 1300 pages book with an drawing to find a specific scene?
This example highlights the capability for highly efficient data retrieval across different modalities. The model processed 1382 pages of “Les Misérables”, equivalent to 732,000 tokens, and was then given an image prompt. It was tasked with locating the specific paragraph within the book that described the scene depicted in the image.
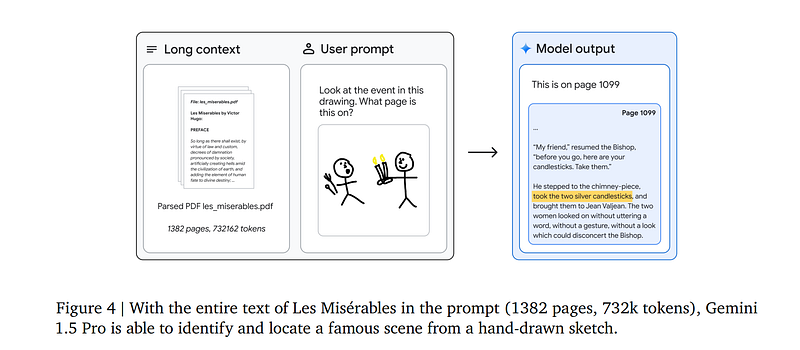
Can large context windows in information retrieval serve as a replacement for Retrieval-Augmented Generation (RAG)?
Well… it depends!
RAG will remain a preferred alternative for scenarios where lower latency and cost are critical, despite the advancements in models that address RAG’s shortcomings such as missed context retrieval and possible hallucinations.
While Gemini 1.5 Pro shows impressive results in data extraction accuracy, their viability is challenged by two main limitations:
- Latency: The use of very large context windows in these advanced models leads to longer processing times, with analysis of queries taking up to 50–60 seconds. This makes real-time applications impractical, as the delay is too significant for scenarios requiring immediate responses.
- Cost: Given the pricing of GPT-4 Turbo, which is around $1 for 100,000 tokens, it’s reasonable to expect similar pricing for these advanced models. While this cost might be justified in certain high-value applications, such as contract conformity analysis where the alternative could be significantly more expensive (e.g., hiring a lawyer), it may be prohibitive for many business scenarios. The expense could outweigh the benefits, especially in applications where large-scale or frequent analysis is required.
Therefore, despite the superior data extraction capabilities of these new models, RAG’s lower latency and cost make it a more suitable choice for a wide range of applications, particularly those that need to balance performance with operational efficiency and budget constraints.
Conclusion and Coming Next
There’s a lot more to unpack about Gemini 1.5 Pro’s capabilities, and I’m eager to dive deeper in a future post.
For now, it’s clear that Google might just have a game-changer on their hands. It’s refreshing to see such a promising contender that could stand toe-to-toe with OpenAI’s GPT-4. The potential for Gemini 1.5 Pro to shake things up is undeniable, and it’s definitely something worth exploring further.
And there’s more good news on the horizon — Google has hinted at upcoming improvements to reduce latency, which could make Gemini 1.5 Pro even more appealing. It’s an exciting time in the AI world, and I can’t wait to see where this leads.
Stay tuned for more in-depth analysis and insights in my next post!