
Exploring Google’s Gemini: A Leap Beyond GPT-4? Everything you need to know!

Google’s recent announcement of Gemini, a family of highly capable multimodal models, has stirred the AI community, prompting comparisons with OpenAI’s GPT-4.
In a detailed analysis of Gemini, based on Google’s 60-page technical report, media interviews, and press releases, several key aspects of this new AI model have been highlighted!
UPDATES — 02/08/2023 Google announces the official release of Gemini Ultra! Bard, Google’s ChatGPT, becomes Gemini, and you can access Gemini Ultra via https://gemini.google.com/app
TL;DR
Gemini is a family of models that range form a mobile optimized models (Nano) to its largest and most capable model (Ultra).
In terms or architecture, Gemini models come with a single unified transformer model with
- Inputs: text, images, video and audio
- Outputs: text and images. This means it can generate images & text!
Google’s evaluations of their models seem to indicate that Gemini Ultra outperforms all other models, across all modalities!
Yet there are some concerns regarding some of the results. Namely, there might be data contamination (i.e., benchmark data might have been, at least partially, used in the training dataset), and choices of metrics might be questionable since they do not match the metrics used by GPT-4 for instance.
Remains the unanswered question: once released, will Gemini Ultra beat OpenAI’s new Q* models? Not sure…
Everything you need to know, in the blog post below!
What is Gemini?
Gemini, a family of models
Gemini is not an AGI (Artificial General Intelligence), but it’s a significant step forward in AI capabilities. It comprises three models: Ultra, Pro, and Nano, each designed for different applications.

- Nano is optimized for mobile devices, already integrated in Google’s new Pixel 8 smartphone! Relying on small sized models (1.8B parameters for Nano-1, and 3.25B parameters for Nano-2), users will be able to use Gemini offline on their phone for text summarization for instance.
- Pro is a more advanced version, and comparable to GPT-3.5 (or even slightly better). Gemini Pro is already available for free through Bard.
- Ultra, its most capable model, is set to be a direct competitor to GPT-4. The models was not released yet. Expect it early next year.
Gemini, different sizes with different capabilities
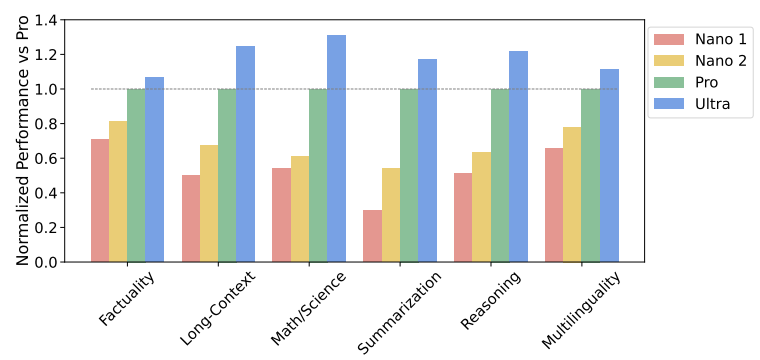
Upon normalizing results over 50 benchmarks covering capabilities like factuality, long-context, reasoning, math, science and multilinguality, it’s evident that the Gemini Ultra model outperforms the other models in the family.
It is worth noting however that despite its smaller size, the Nano 2 model (3.25B parameters) demonstrates remarkable capabilities, particularly in the math dataset where it outshines LLaMA 2 70B (more than 20 times larger!) with a 22.8% performance rate compared to LLaMA’s 13.5%. This indicates that while Ultra leads with strength across the board, the more compact Nano version holds its own in specialized tasks.
Alreay embedding in Google new Pixel 8 pro smartphone, users will be able to rely on it for tasks such as summarization and data extraction offline! You can also expect Google to update its smartphone with more capable models soon, while remaining small and fast!
We just entered the era of offline LLMs running on our smartphones!
Gemini’s Multimodal Capabilities
Gemini was build as a “multimodal model from the ground up”. With capabilities spanning text, images, video and speech in a single model!
What does “multi model from the ground up” mean? In a nutshell, recent multimodal models are just different models stitched together. Gemini was designed as a single model, trained with all modalities.
The main advantage is enabling models to “see” the world and learn across modalities all at once!
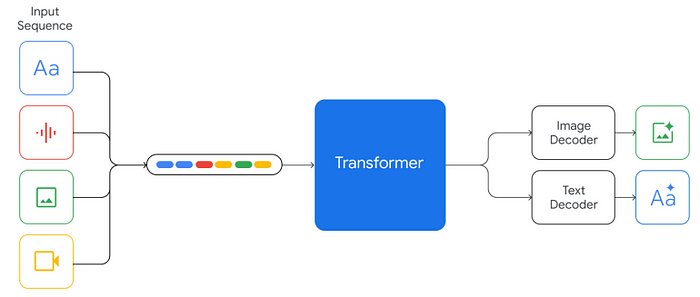
Model Card Summary: Multimodal Abilities and high level comparaison with OpenAI models!
Google announces a model that outperforms
- GPT-4 in text & image understanding,
- Is capable of video understanding (unlike GPT-4),
- and beats OpenAI’s Whisper 3 models when it comes to speech recognition benchmarks!
- Gemini, can also generate images via the same model!
Dataset: This is attributed to its training, which includes data from web documents, books, code, and includes image, audio, and video data.
Unfortunately we don’t know much more about the training data for now.
DeepDive — Gemini: An Announced GPT-4’s Killer?
Gemini seems to consistently outperform OpenAI models across all modalities, yet… is it really the next generation model?
Text & Code Based Performances
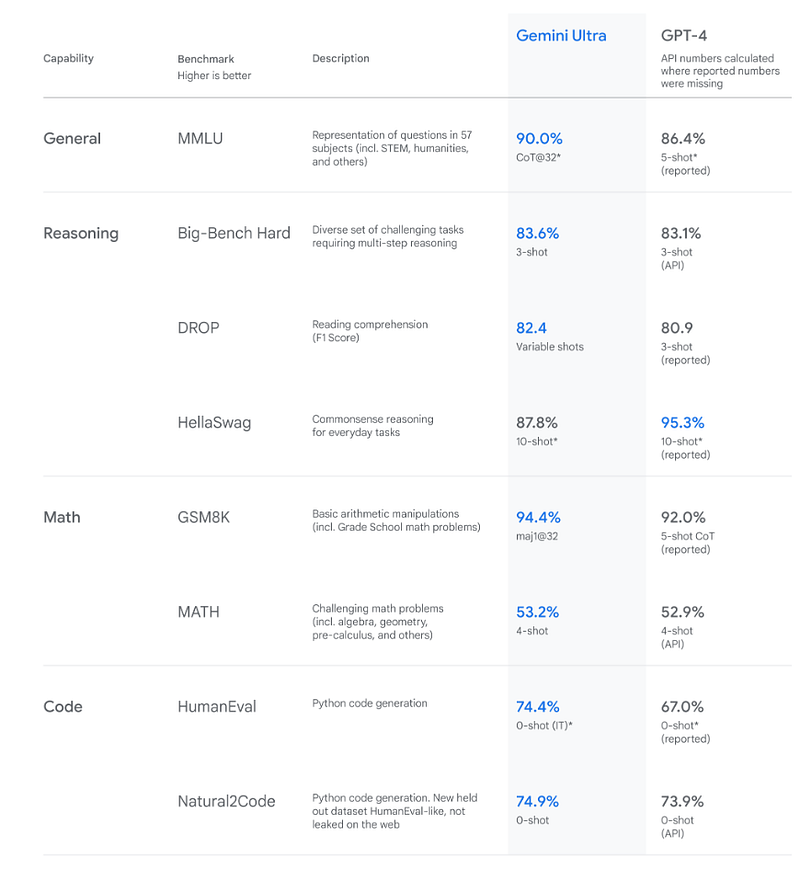
Gemini Ultra model have been evaluated on various academic benchmarks, demonstrating state of the art performances in comparison to other leading AI models such as GPT-3.5 and GPT-4.
- MMLU/Beating Human Experts: A key highlight from the evaluation is Gemini Ultra’s performance on the MMLU benchmark, covering general knowledge related capabilities, where it achieved a 90.04% accuracy. This is a significant result, as it not only outperforms its predecessors like GPT-3.5 and GPT-4 but also surpasses human expert performance in multiple-choice questions across 57 subjects.
- Chain Of Thought (CoT) Reasoning: The superior performance of Gemini Ultra is largely attributed to an approach known as “uncertainty-routed chain-of-thought”, which employs a majority vote among 32 CoT samples, guided by threshold or greedy sample choices. This method appears to enhance the model’s reasoning capabilities, particularly in areas requiring specialized knowledge.
Note: It does also question the result since we know that the performance of a model varies based on prompt engineering ; As a matter of fact, Gemini is compared to GPT-4 “basic” 5 shot results ; however GPT-4 prompted with CoT was also able to reach 89% accuracy on this dataset!
Nevertheless, Gemini remains the best multimodal models out there. When it comes to other benchmarks, Gemini Ultra also exhibits strong results.
- In the GSM8K, which is focused on grade-school math, Gemini Ultra records a 94.4% accuracy.
- In reading comprehension, assessed via the DROP benchmark, Gemini Ultra shows an 82.4% accuracy rate, slightly outperforming GPT-4 with only 80.9% accuracy rate
- Common Sense: one important exception though: the HellaSwag benchmark, that tests common-sense reasoning, Gemini Ultra’s only performance is at 87.8% whereas GPT-4 scores 95.4%! Success on this task indicates a model’s ability to understand and reason about everyday situations, a critical aspect of human-like language understanding.
Note: despite these strong performances, the paper notes some minor concerns regarding data contamination. We’ll have to wait for further independent tests on unpublished dataset to better assess these models capabilities.
Beyond Text Capabilities: Visual & Speech capabilities
Gemini is not only capable of handling image inputs, it also can understand videos. It gives it a wider range of actions compared to GPT-4.
Check the video below to better understand what we should expect from this models and why everyone is excited about it!
Disclamer — video demo: this impressive video showcases Gemini’s (promised) abilities to interact with videos in real time. It’s worth mentioning that for the demo, this video was edited, to remove Gemini’s slow response time or lengthy answers ; Thus it doesn’t represent Gemini’s current capabilities, but rather what it should be capable of doing in the near future.
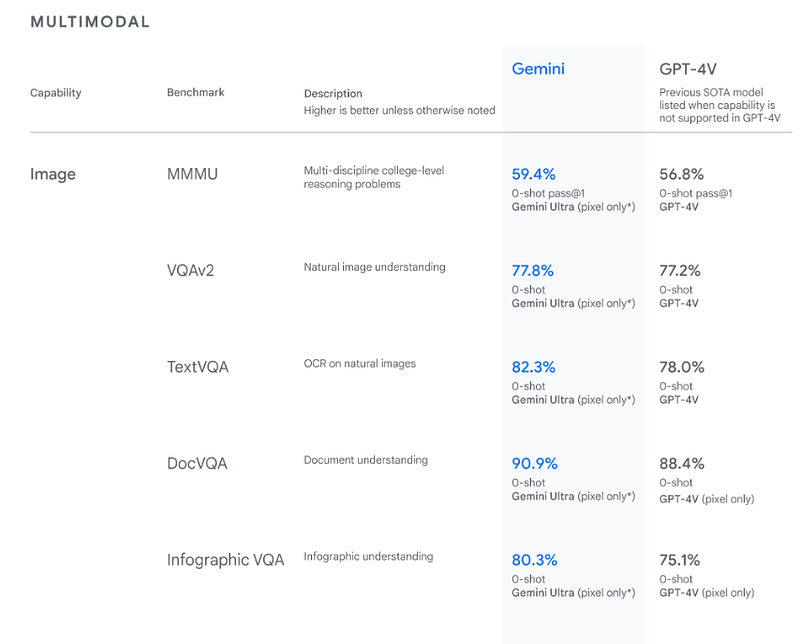
Image Understanding
On image reasoning, understanding, data extraction, document and graphic understanding, Gemini outperforms GPT-4 on all standard academic benchmarks!
Here’s an example provided in the technical report where we can see how Gemini can analyse a visual document with graphics.
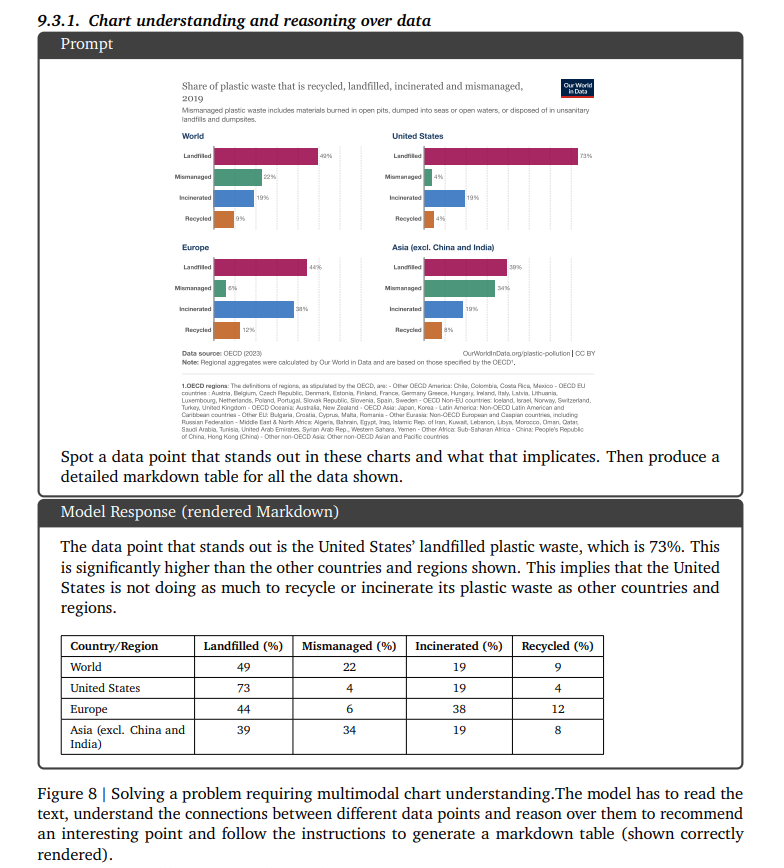
This second example shows it capabilities to handle multimodal multilingual reasoning tasks!
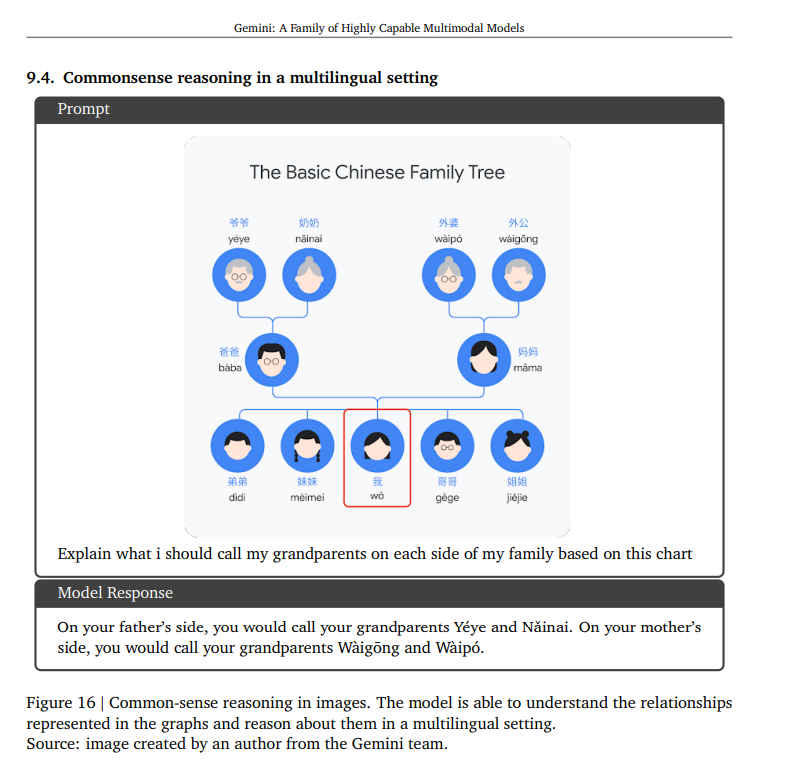
Gemini — Video and Speech Performances
On these modalities, we can’t compare Gemini to GPT-4 since the latter can’t manipulate audio or Video.
Google does provide however a comparaison with other state of the art models, beating all of them, as well, on all standard benchmarks!
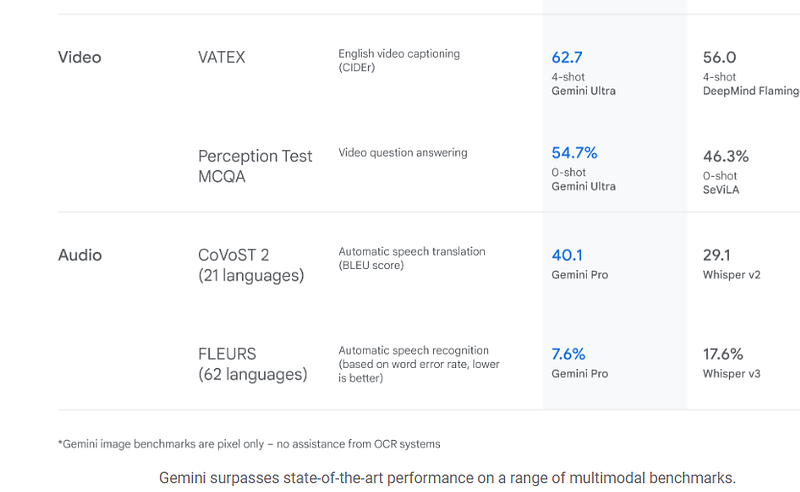
Gemini leads in five out of five speech recognition and translation benchmarks, indicating its strength in processing and understanding spoken language.
This is particularly important for languages like Mandarin, where tone and nuance play a crucial role. Gemini’s ability to differentiate subtle variations in pronunciation is a notable achievement.
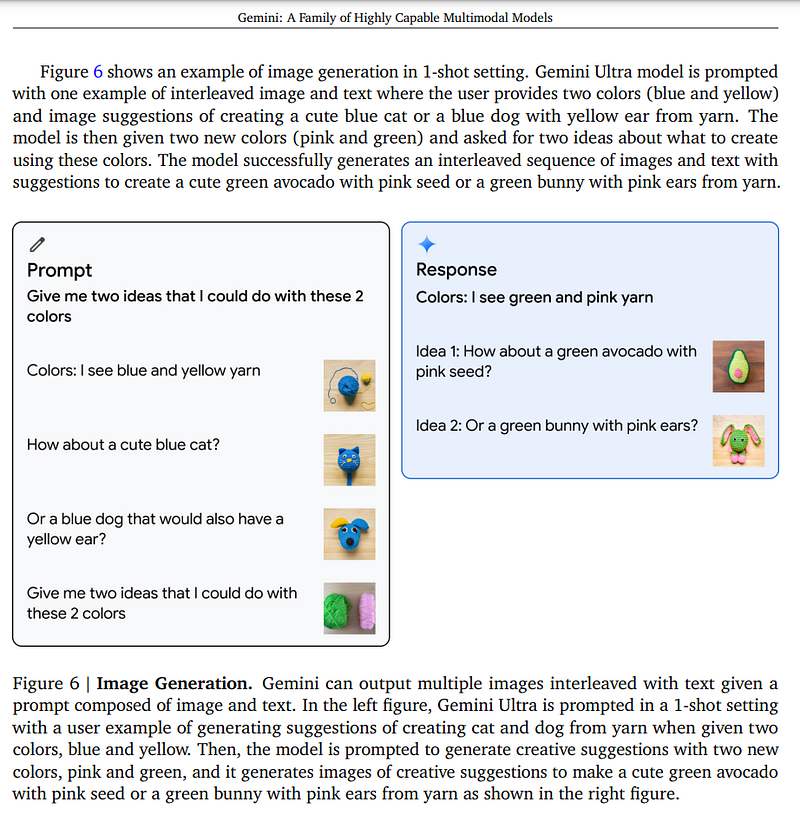
Image Generation Capabilities
Unlike all other models on the market, Gemini can also generate images with a single model. Leveraging it’s ability to understand and reason based on text, audio, images and videos, it can understand complex input and answer with both text and images!
Check this example provided in Google’s technical report
Criticisms and Concerns
- Lack of Transparency: There’s criticism over the lack of detailed information about the datasets used for training Gemini, which raises questions about the model’s generalizability and bias.
- Methodological Differences: The different methodologies used in testing and comparing Gemini with other models like GPT-4 make it challenging to draw definitive conclusions about its superiority.
- External Factors: Some of the delays and challenges in Gemini’s development, such as issues related to cosmic rays, have been highlighted, though their impact on the model’s performance is not entirely clear.
Future Directions
Google DeepMind’s CEO, Demis Hassabis, hinted at future developments where Gemini might be combined with robotics to physically interact with the world, indicating a push towards truly multimodal AI systems.
Check my previous blog post on LLM integrated in Robots:
Conclusion
In summary, Google’s Gemini marks a significant leap in the field of artificial intelligence with its array of advanced capabilities that distinguish it from existing models. The key features that set Gemini apart include:
- Multimodal Input Handling: Gemini is a single model that natively processes a variety of inputs including text, images, audio, and videos. This versatility allows it to function across different types of data seamlessly.
- Dual Output Generation: Unlike most current models, Gemini has the unique capability to generate both text and images. This feature expands its utility, allowing for a wider range of creative and analytical applications.
- Intrinsic Multilingual Design: Designed with multilingual capabilities from the outset, Gemini can understand and interact in multiple languages, making it a truly global AI model.
- Superior Performance Across Modalities: Gemini stands out for its performance, outshining all available models in various benchmarks, regardless of the modality. Whether it’s handling text, images, audio, or video, Gemini demonstrates exceptional accuracy and efficiency.
These groundbreaking features of Gemini underscore its potential to redefine the landscape of artificial intelligence, offering unprecedented versatility and power in AI applications.
Yet… OpenAI is still winning!
- Google Gemini Pro is comparable to GPT3.5 (or slightly better), and it’s most capable model, Gemini Ultra, is still unavailable.
- Meanwhile, in less than a year, OpenAI built a solid business from the ground up, generating more than a 1B$ annually, relying on both ChatGPT plus subscription and its APIs! A business that keeps growing overtime.
To Be Continued…





