
From Good to Great: How Pre-processing Documents Supercharges AI’s Output
Retrieval Augmented Generation will work only with quality data: learn how to clean your documents for better results.

As the saying goes… Garbage In — Garbage Out.
While Language Models (LLMs) are incredibly powerful, they do have some limitations. They can struggle when it comes to processing large amounts of text at once and referencing specific information. Recent research has even shown that LLM performance tends to be highest when relevant information is located at the beginning or end of the input context. When models have to access important information buried in the middle of lengthy contexts, their performance can significantly degrade.
In this article we will approach a simple strategy to pre-process our documents and to make them ready for a high-performance retrieval.
Why Do We Need Retrieval-Augmented Generation (RAG)?
To overcome these limitations, techniques like Retrieval-Augmented Generation (RAG) have emerged. RAG enables more efficient and effective processing of large documents and broader information retrieval, making it a valuable tool.
RAG follows a really simple mechanism: the context that contains the facts to reply to a Question are injected in the prompt together with the Question itself. In this way the Generative AI Model, your preferred LLM, will check ONLY the given context to provide you the Answer.
- Since LLMs training is fixed in time your Language Model cannot know everything.
- Moreover if you work on a really specific knowledge domain (medicine, engineering, finance…) it is likely that the AI cannot find the information required to reply to your questions.
- Hallucinations are aa very high risk: this means that occasionally, when uncertain, LLMs can produce statements that sound true but are not entirely accurate. They might even provide irrelevant responses to fill in gaps.

Why we need Pre-processing?
When it comes to leveraging Natural Language Processing (NLP) for real-world applications, most papers, tasks, and pipelines assume that we’re working with clean, unaltered texts.
However, in reality, many of the texts we encounter, including a majority of legal documents like contracts and legal codes, are far from clean. Instead, they come in the form of visually structured documents (VSDs), commonly known as PDFs. While PDFs are versatile and preserve the visual integrity of documents, they often pose a significant challenge when it comes to extracting and manipulating their contents.
In this article we will use plain TXT files from Medium articles as a showcase of the significance of document pre-processing: with text file the process is not complex, and also gives few guidelines to be applied also to PDFs.
Let’s have a look at one Medium article in brute plain text: I used a Chrome extension to get it (Page Plain Text extension). For this example I used a really cool article by Christophe Atten: 5 Opportunities and Pitfalls of GenAI (ChatGPT and LLMs) Navigating the Frontier of GenAI: Five Insights for Business Leaders.
In google Colab we can load the text file and run the tokenizer of Zephyr7b to count the raw text weights.
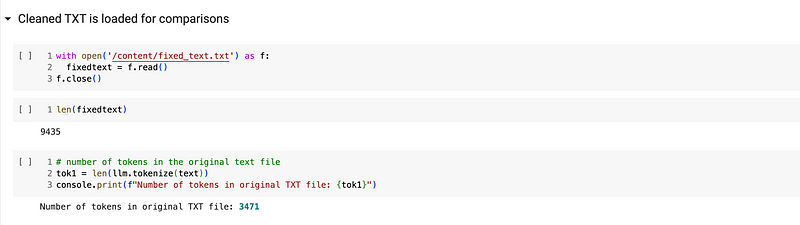
It is essential to remove all the noise in the text: for plain text you will not have to worry about headers, footers and page numbers, but even with a webloader you will get a lot of futile metadata, non-readable references and links. Look at the very same example:
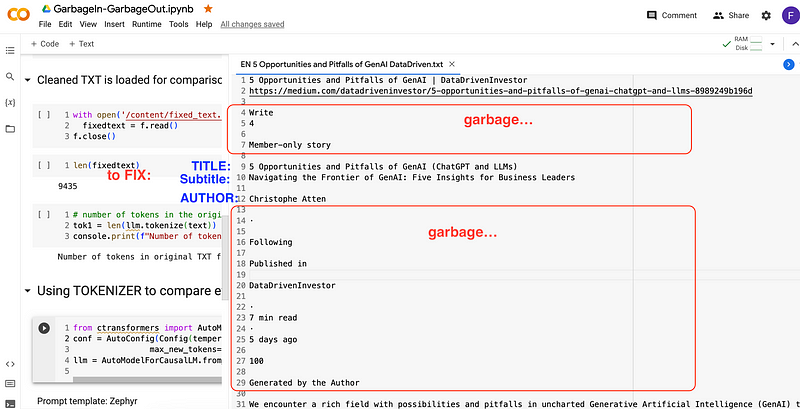
In Colab itself you can edit the TXT file: here I removed already 20 lines, words, number and punctuations not relevant for analysis. At the same time it is recommended to include tags for Title, Author and Article URL.
Going on it is good to look at what happens at the end of the articles: there may be a lot additional links and references not giving us any benefit for the Retrieval Augmented Generation process…
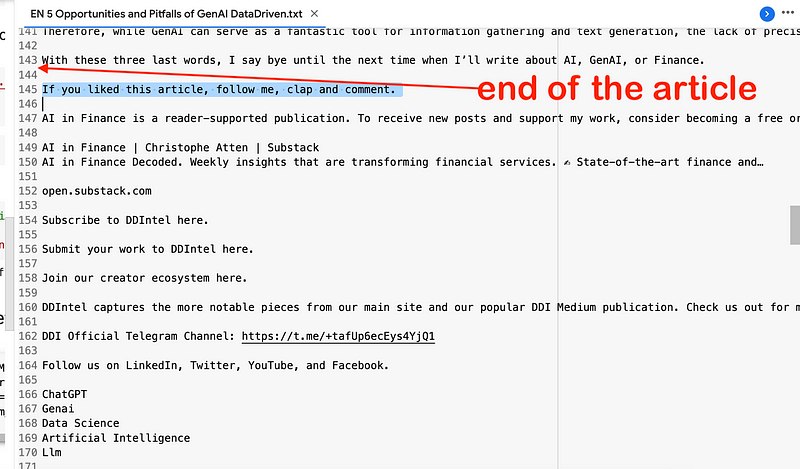
From row 144 to 363 basically there is nothing more related to the content of the article itself: better delete everything.
I know that this process to you seems really unproductive: but believe me that it is naive to believe that the LLM is able to do all of this cleaning without and drawbacks (in terms of time or costs).
I recently read an amazing article on Medium written by Soner Yıldırım, titled Only Use LLMs If You Know How to Do the Task on Your Own (Otherwise you may end up with silent mistakes or harsh consequences). Even if AI can do something, doesn’t mean that it is doing it right!
So after the first cleaning the results are already remarkable: we saved 1200 tokens, that in terms of context and generation it is really a lot!

The issues with PDFs
Have you ever tried to load a PDF in LangChain? What the Document loader does is the parse the text from the PDF… without a real structure.

The prerequisite of a GREAT Retrieval-Augmented Generation is that your text is well organized and cleaned. However 95% of the PDFs we work with are not text-only layered PDFs. Parsing (reading and transforming into text) these types of PDFs is far from a straightforward task due to their inherent complexities.
- Complexity of the layout: PDFs can have intricate layouts, including multi-column text, tables, images, and complex formatting. This diversity in layout makes it challenging to extract structured data accurately.
- Fonts and Encoding: PDFs use various font encoding systems, and some of these systems don’t directly map to Unicode. As a result, extracting the text from PDFs with precision can be difficult, leading to potential inaccuracies.
- Messy text arrangement : Instead of storing text in the order it appears visually, PDFs store text in objects that can be placed anywhere on the page. As a result, the underlying code may not match the visual order of the text, adding another layer of complexity to the parsing process.
- Spaces: In certain PDFs, spaces between words are used inconsistently or not at all. This inconsistency can make it challenging to identify word boundaries correctly, further complicating text extraction.
There are few online resources, accessible through an API call from python: LayoutPDFReader is one of those. Feel free to use it, but in my idea of AI application the data manipulation and extraction must be completely segregated from the NLP process: the first one must follows the strict privacy and mostly reside on your Computer/Network, the second one can be your online hosted LLM (that you can reach out through and API call).
NOTE: my suggestion here is to use a pdf loader to get the plain text of the PDF. After that apply the rules we explored in the previous section to clean up the data.
How much do we save?
All the things said so far are only words. Let’s have a look at the numbers.
RAG performance mainly relies on the retrieval accuracy and the LLM Generation.
The Retrieval part consists in splitting the document into small chunks and apply an embeddings model to vectorize the chunk. This is required because the sentence-transformer embeddings wants to translate in numerical weights the meaning of the text: it is the machine way to understand the language.

These vectors (of very high dimensions and accuracy) are stored into a database (like FAISS, ChromaDB etc…) to be easily accessible multiple times.
When we ask a question to the LLM what happens is that our query is compared to the vector database looking for semantic similarity. The relevant chunks (with highest similarity score) are collected and then given to the LLM as a context for the generation.
Since LLMs have a limited “memory”, called context, we cannot give and entire book or an entire article: we usually pick the 3 or 4 more relevant chunks, or in any case only that much context that can fit into the maximum context available for every specific model.
Example: Llama 2 7B has 4000 tokens of context window. This means that our prompt + the answer must fit this number. I we leave room for 1000 token to the generation, we have 3000 tokens available for the prompt and the context.
Let’s compare the previous figures:
Original Article: 3471 tokens
Pre-processed Article: 2240 tokensSo in theory, using Llama2 we can easily feed the entire Pre-processed article to the model as context for the generation: the same approach was not possible without our cleaning exercises.
For bigger documents, as well, the benefits are huge:
- we do not have noises in the text
- the number of chunks are highly reduced, keeping good quality
- less tokens equals to less inference time (and computational costs) — this is extremely useful if you can use only CPU resources
Conclusions
I really hope these easy techniques will be helpful. I had to find myself with a lot of trials and errors that leaving tools like LangChain or LlamaIndex to do the job for you was not enough.
Data quality is always the starting point for any NLP task.
Cleaning up our documents will help to increase the accuracy and the performance of any Language Model during Retrieval Augmented Generation process.
If this story provided value and you like the topics consider subscribing to Medium to unlock more resources. Medium is a big community with high quality content: you can certainly find here what you need.
- Sign up for a Medium membership using my link — ($5/month to read unlimited Medium stories)
- Follow me on Medium
- Highlight what you want to remember and if you have doubts or suggestions simply drop a comment to the article: I will promptly reply to you
- Read my latest articles https://medium.com/@fabio.matricardi
Don you want to read more? Here some topics





