
Exploring OpenAI Whisper on Hugging Face
OpenAI Whisper is a general-purpose speech recognition model

Introduction
Whisper is another OpenAI product. It is a general-purpose speech recognition model, which is trained on various speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection. It is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
OpenAI released Whisper on September 2022. Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. It is a leap from the existing speech recognition technologies.
The Whisper architecture is a simple end-to-end approach, implemented as an encoder-decoder Transformer. Input audio is split into 30-second chunks, converted into a log-Mel spectrogram, and then passed into an encoder. A decoder is trained to predict the corresponding text caption, intermixed with special tokens that direct the single model to perform tasks such as language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation. The details are demonstrated by the following diagram:

Hugging Face is an open-source and platform provider of machine learning technologies. It is an AI community that builds, trains, and deploys state of the art models powered by referencing open source in machine learning. It transforms complicated machine learning models into simple applications.
We use Hugging Face apps to explore OpenAI Whisper.
Whisper Demo on Hugging Face
openai/whisper is a Whisper demo on hugging face, which cuts audio after around 30 seconds. Here is the user interface:
This English recording has been perfectly transcribed to “It is a beautiful world where bold and innovative artwork flourishes in art renaissance, despite some legal and social challenges.”

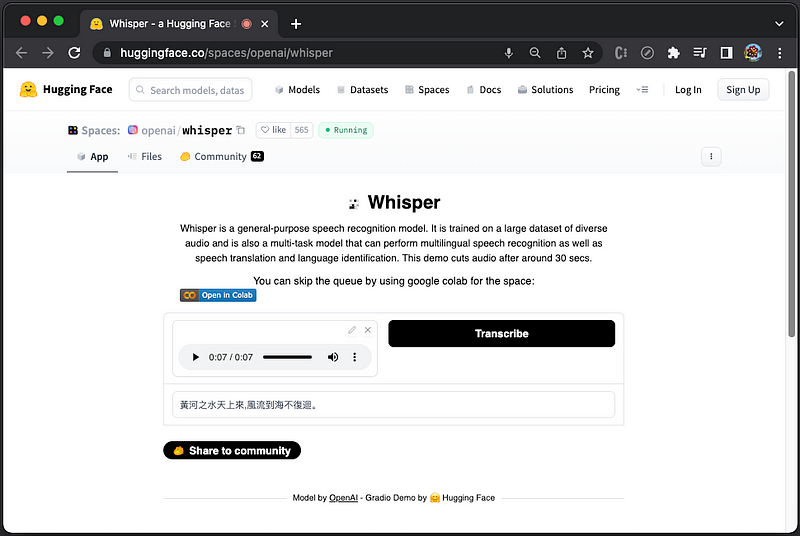
This Chinese recording has been transcribed to “黃河之水天上來,風流到海不復迴。” There is one word wrong: 風 should be 奔.
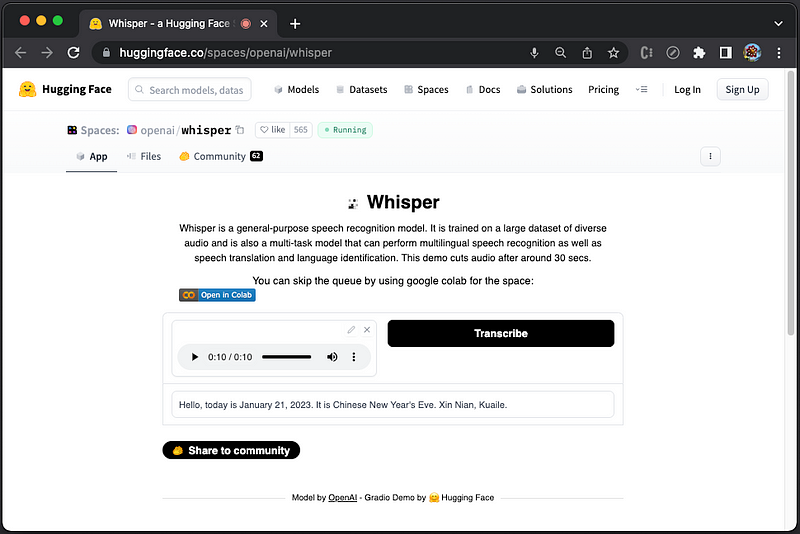
Here is mixed English and Chinese recording, “Hello, today is January 21st, 2023. It is Chinese New Year Eve. 新年快樂!” The English part is transcribed well, but not the Chinese part.
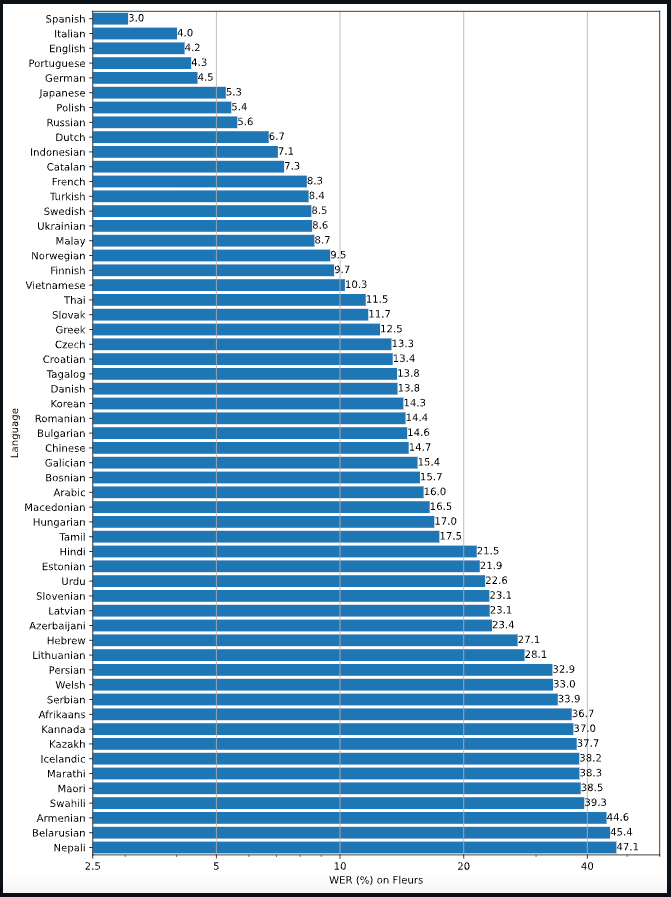
Whisper still needs to improve for mixed languages. The following image shows the supported languages, as well as Word Error Rate (WER) breakdown by languages of Fleurs dataset. Smaller number is better.
Whisper Demo on Google Colab
On the above app, there is a button, Open in Colab. It is a link to https://colab.research.google.com/drive/1WJ98KHgZxFGrHiMm4TyWZllSew_Af_ff?usp=sharing. Clicking on it opens Google Colaboratory (Colab) that is running on public cloud. The file, whisper-gradio.ipynb, is opened.
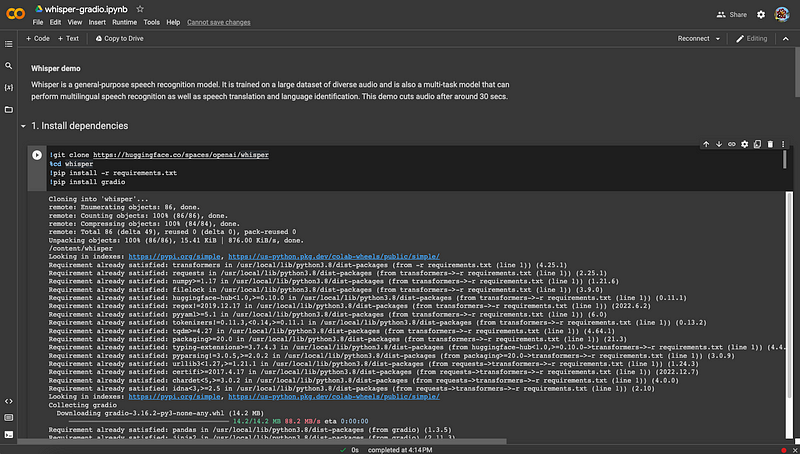
As we have explained in a previous article, .ipynb stands for Interactive PYthon NoteBook. There are a number of ways to view and execute a notebook file — Jupyter Notebook, Visual Studio Code, and Google Colaboratory. Lately, Colab becomes a popular working environment for AI computing. It is a free Jupyter notebook version that runs entirely in the cloud. In addition, it does not require a setup and runs with the cloud resource. It also enables collaboration among team members.
Select the menu, Runtime → Run all:
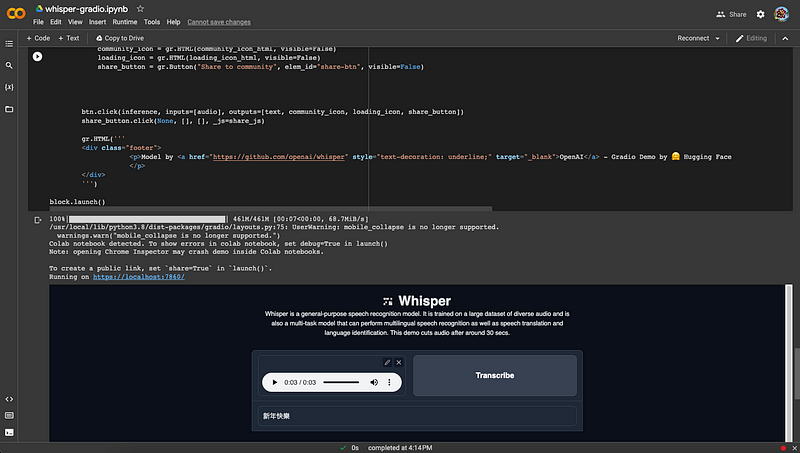
It works similarly to run the Whisper Demo on Hugging Face. It has perfectly transcribed the Chinese audio to “新年快樂”.
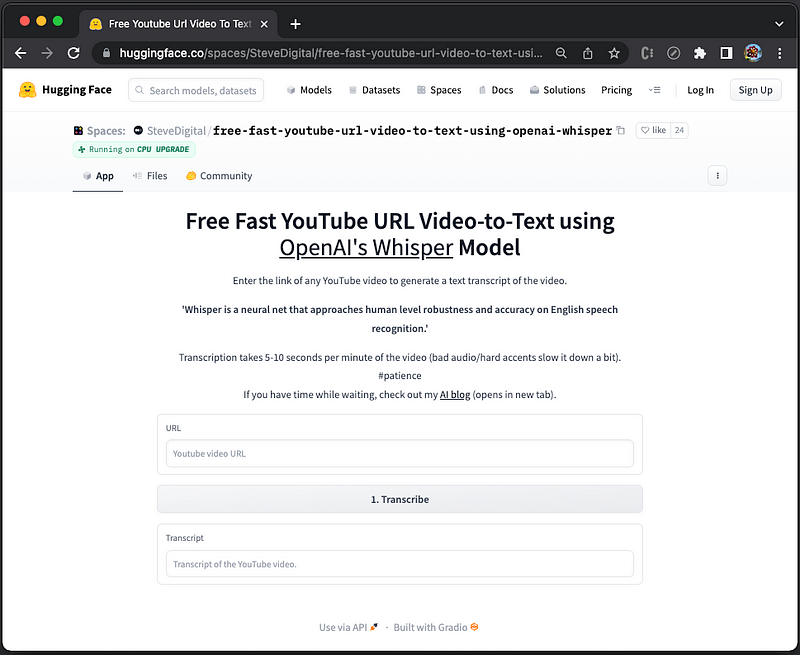
Whisper Demo From Video to Text
SteveDigital/free-fast-youtube-url-video-to-text-using-openai-whisper is another Whisper demo on hugging face. Enter the link of any YouTube video, it can generate a text transcript of the video. Transcription takes 5–10 seconds per minute of the video. Here is the user interface:
Type the YouTube video line, https://www.youtube.com/watch?v=qTgPSKKjfVg, and click the Transcribe button:
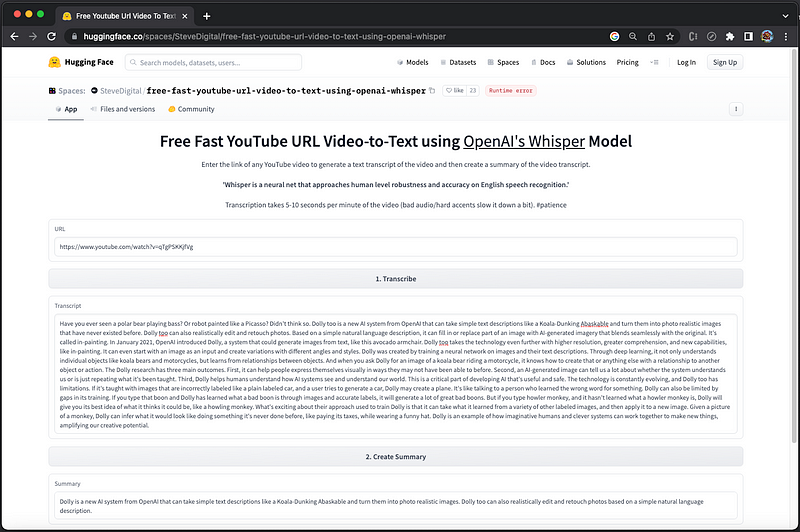
This Whisper demo generates the transcript and summary.
Here is the original transcript on YouTube:
Have you ever seen a polar bear playing bass? Or a robot painted like a Picasso? Didn’t think so. DALL-E 2 is a new AI system from OpenAI that can take simple text descriptions like, “a koala dunking a basketball” and turn them into photorealistic images that have never existed before. DALL-E 2 can also realistically edit and retouch photos. Based on a simple natural language description, it can fill in or replace part of an image with AI-generated imagery that blends seamlessly with the original. It’s called “in-painting”. In January 2021, OpenAI introduced DALL-E, a system that could generate images from text, like this “Avocado Armchair”. DALL-E 2 takes the technology even further with higher resolution, greater comprehension, and new capabilities like in-painting. It can even start with an image as an input and create variations with different angles and styles. DALL-E was created by training a neural network on images and their text descriptions. Through deep learning, it not only understands individual objects, like koala bears and motorcycles, but learns from relationships between objects. And when you ask DALL-E for an image of a koala bear riding a motorcycle, it knows how to create that or anything else with a relationship to another object or action. The DALL-E research has three main outcomes: First, it can help people express themselves visually in ways they may not have been able to before. Second, an AI-generated image can tell us a lot about whether the system understands us, or is just repeating what it has been taught. Third, DALL-E helps humans understand how advanced AI systems see and understand our world. This is a critical part of developing AI that’s useful and safe. The technology is constantly evolving, and DALL-E 2 has limitations. If it’s taught with objects that are incorrectly labeled, like a plane labeled “car”, and a user tries to generate a car, DALL-E may create…a plane. It’s like talking to a person who learned the wrong word for something. DALL-E can also be limited by gaps in its training. For example, if you type “baboon” and DALL-E has learned what a baboon is through images and accurate labels, it will generate a lot of great baboons. But if you type “howler monkey” and it hasn’t learned what a howler monkey is, DALL-E will give you its best idea of what it thinks it could be: like a “howling monkey”. What’s exciting about the approach used to train DALL-E is that it can take what it learned from a variety of other labeled images and then apply it to a new image. Given a picture of a monkey, DALL-E can infer what it would look like doing something it’s never done before. Like paying its taxes, while wearing a funny hat. DALL-E is an example of how imaginative humans and clever systems can work together to make new things — amplifying our creative potential.
Here is the generated transcript:
Have you ever seen a polar bear playing bass? Or robot painted like a Picasso? Didn’t think so. Dolly too is a new AI system from OpenAI that can take simple text descriptions like a Koala-Dunking Abaskable and turn them into photo realistic images that have never existed before. Dolly too can also realistically edit and retouch photos. Based on a simple natural language description, it can fill in or replace part of an image with AI-generated imagery that blends seamlessly with the original. It’s called in-painting. In January 2021, OpenAI introduced Dolly, a system that could generate images from text, like this avocado armchair. Dolly too takes the technology even further with higher resolution, greater comprehension, and new capabilities, like in-painting. It can even start with an image as an input and create variations with different angles and styles. Dolly was created by training a neural network on images and their text descriptions. Through deep learning, it not only understands individual objects like koala bears and motorcycles, but learns from relationships between objects. And when you ask Dolly for an image of a koala bear riding a motorcycle, it knows how to create that or anything else with a relationship to another object or action. The Dolly research has three main outcomes. First, it can help people express themselves visually in ways they may not have been able to before. Second, an AI-generated image can tell us a lot about whether the system understands us or is just repeating what it’s been taught. Third, Dolly helps humans understand how AI systems see and understand our world. This is a critical part of developing AI that’s useful and safe. The technology is constantly evolving, and Dolly too has limitations. If it’s taught with images that are incorrectly labeled like a plain labeled car, and a user tries to generate a car, Dolly may create a plane. It’s like talking to a person who learned the wrong word for something. Dolly can also be limited by gaps in its training. If you type that boon and Dolly has learned what a bad boon is through images and accurate labels, it will generate a lot of great bad boons. But if you type howler monkey, and it hasn’t learned what a howler monkey is, Dolly will give you its best idea of what it thinks it could be, like a howling monkey. What’s exciting about their approach used to train Dolly is that it can take what it learned from a variety of other labeled images, and then apply it to a new image. Given a picture of a monkey, Dolly can infer what it would look like doing something it’s never done before, like paying its taxes, while wearing a funny hat. Dolly is an example of how imaginative humans and clever systems can work together to make new things, amplifying our creative potential.
Do you notice the issue?
It did not recognize the term, DALL-E. Instead, it is transcribed to Dolly.
We use Diffchecker to compare the differences:
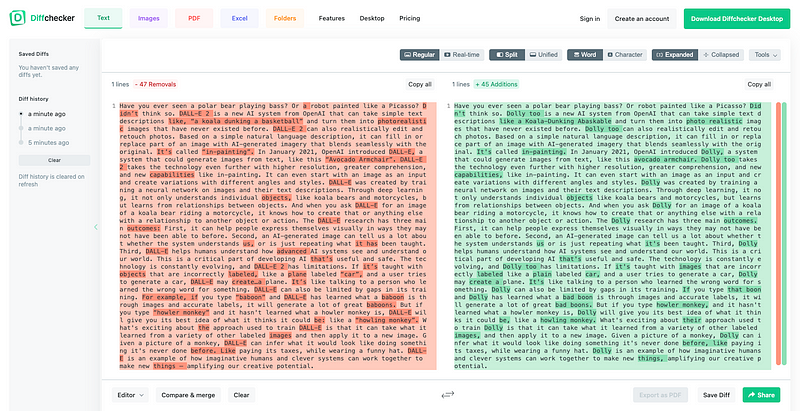
The transcription is generally good, except the term, DALL-E.
The same conclusion is true for the summary:
Dolly is a new AI system from OpenAI that can take simple text descriptions like a Koala-Dunking Abaskable and turn them into photo realistic images. Dolly too can also realistically edit and retouch photos based on a simple natural language description.
Conclusion
We have explained Whisper, a general-purpose speech recognition model. OpenAI released Whisper on September 2022. Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web.
We have explored two examples on Hugging Face:
- Transcribe an audio recording to text.
- Generate a text transcript of the video, along with a summary.
Whisper is a leap from the existing speech recognition technologies. It is going to bring impact to the ASR world.
Thanks for reading.
Want to Connect?
If you are interested, check out my directory of web development articles.More content at PlainEnglish.io. Sign up for our free weekly newsletter. Follow us on Twitter, LinkedIn, YouTube, and Discord.
Interested in scaling your software startup? Check out Circuit.




