
Building an AI Assistant Chatbot with GPT4All and Langchain: A Step-by-Step Guide and Response Time Comparison of Mixtral vs. Llama3
Learn to Develop a Powerful Chatbot Using GPT4All and Langchain, and Compare Response Times of Llama3 and Mistral Locally or in Google Colab
👨🏾💻 GitHub ⭐️ | 👔LinkedIn |📝 Medium

Introduction
The world of AI and natural language processing (NLP) is evolving rapidly, with the introduction of various models and frameworks that make it easier to build AI-powered applications. One such ecosystem is GPT4All, which allows you to run large language models (LLMs) locally without depending on the cloud. Combining this with LangChain, an open-source framework for building language model applications, can help you create robust AI-powered chatbots.
In this blog post, we will walk through the steps of creating a chatbot using GPT4All and LangChain, running on Google Colab. We’ll explore the performance of different models (Mistral-7B-instruct and Llama-3 8B-instruct) and implement a chatbot that can handle continuous conversations with users. You can also make use of any alternative model accessible through GPT4All.
What is GPT4All?
GPT4All is an open-source project that makes it possible to run powerful language models on your local machine. This is particularly useful for developers who need privacy, reduced latency, or want to avoid the costs of cloud-based services. GPT4All supports models like Mistral, Llama, and others, allowing you to choose the one that fits your needs.
Advantages:
- Privacy: Running models locally ensures that your data never leaves your machine.
- Low Latency: Local execution often results in faster responses compared to cloud-based solutions.
- Cost: No cloud costs — once the model is downloaded, you can run it as many times as you want.
Disadvantages:
- Resource Intensive: Large models require significant computational resources (like a good GPU).
- Setup Complexity: Setting up these models locally can be more complicated compared to simply using an API.
LangChain
LangChain is an open-source framework designed to build applications powered by LLMs. It provides components that make it easy to work with language models, including support for chaining multiple steps together, which is essential for building more complex applications like chatbots. LangChain also integrates with different LLM providers, enabling you to leverage various models seamlessly.
Advantages:
- Flexibility: Easy to create complex workflows involving multiple prompts and responses.
- Integration: Supports various models and embeddings out-of-the-box.
- Scalability: Allows you to scale your LLM-based applications easily.
Disadvantages:
- Learning Curve: LangChain offers a lot of features, which can be overwhelming for beginners.
- Resource Consumption: Depending on your use case, running large workflows might consume a lot of resources.
Tutorial: Building a GPT4All-Powered Chatbot with LangChain
Let’s dive into the code to build our chatbot using GPT4All and LangChain on Google Colab.
Step 1: Setup Google Colab with Necessary Libraries
We begin by installing the required libraries on Google Colab:
!pip install langchain !pip install -U langchain-community !pip install gpt4all
Enable to retrieve GPU devices with configuring an Ubuntu 22.04 server with the following:
!apt install libvulkan1
# Install NVIDIA Vulkan driver
!apt install libnvidia-gl-525-serverStep 2: Comparing Model Response Times (Mistral-7B-instruct vs. Llama-3 8B-instruct)
We will use two models, Mistral-7B-instruct and Llama-3 8B-instruct, to compare their performance and response times.
Mistral-7b-instruct
from gpt4all import GPT4All
import time
# Initialize the Mistral-7B model
llm = GPT4All("mistral-7b-instruct-v0.1.Q4_0.gguf", n_threads=4, allow_download=True, device='gpu')
prompt = "What are the benefits of using GPT4All?"
start_time = time.time()
print(llm.generate(prompt))
end_time = time.time()
print(f"Time taken to generate answer: {end_time - start_time:.2f} seconds")
Llama3–8b-instruct
# Initialize the Llama-3 8B-Instruct model
model = GPT4All("Meta-Llama-3-8B-Instruct.Q4_0.gguf", device='gpu')
start_time = time.time()
print(model.generate(prompt))
end_time = time.time()
print(f"Time taken to generate answer: {end_time - start_time:.2f} seconds")
Here, we initialize two different models and time their response for the same prompt. This helps us understand which model performs faster, depending on the complexity of the task. As the mistral model response is slightly faster so we will continue making the chatbot with this model.
Step 3: Locating the Downloaded Model
When working with Google Colab, it’s important to know where your models are stored after download. If you run your code in your local machine then save the model and get the path for further use.
The following code helps you locate your model files in colab:
import os
model_filename = "mistral-7b-instruct-v0.1.Q4_0.gguf"
downloaded_model_path = None
# Search common directories
if os.path.exists(model_filename):
downloaded_model_path = model_filename
elif os.path.exists(f"/root/.cache/gpt4all/{model_filename}"):
downloaded_model_path = f"/root/.cache/gpt4all/{model_filename}"
elif os.path.exists(f"/content/.cache/gpt4all/{model_filename}"):
downloaded_model_path = f"/content/.cache/gpt4all/{model_filename}"
else:
print("Model file not found. Trying to locate the download directory...")
if downloaded_model_path:
print(f"Model downloaded at: {downloaded_model_path}")
else:
print("Model still not found. Please ensure that the model downloads correctly.")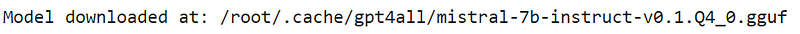
This script checks common directories where the model might be downloaded and helps you debug any issues related to model location.
Step 4: Building the Chatbot with LangChain
Now, let’s build a simple chatbot using LangChain and the GPT4All model:
Part 1: Setting Up the AI Model and LangChain
This part of the code sets up the GPT4All model and integrates it with LangChain to create a basic AI-powered language model application. Key steps include:
1. Importing Libraries: Essential components from LangChain are imported, including document loaders, embeddings, and the GPT4All wrapper.
2. Defining the Prompt Template: A simple template is created, instructing the AI to provide a short answer to a given question.
3. Model Initialization: The GPT4All model (Mistral-7B) is loaded from a local path, with the GPU specified for better performance.
4. Creating the LLMChain: The LangChain
LLMChainis created by combining the GPT4All model with the prompt template, allowing you to send queries to the model and receive responses.
from langchain.document_loaders import DirectoryLoader
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain.callbacks.manager import CallbackManager
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain_community.llms import GPT4All
# Define the prompt template
template = """
You are an AI assistant. Given the following question, provide a short answer.
Question: {question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["question"])
# Define the model path
model_path_mistral = "/root/.cache/gpt4all/mistral-7b-instruct-v0.1.Q4_0.gguf"
# Create the LLM using GPT4All
llm = GPT4All(model=model_path_mistral, device='gpu', verbose=True)
print("Model loaded successfully!")
# Create the LLMChain
llm_chain = LLMChain(prompt=prompt, llm=llm)If you run your code in your local machine, give the locally stored model path.
Part 2: Interactive Chatbot Loop
This part creates a continuous loop for user interaction:
1. Input Loop: The code enters a loop, asking the user for input until the user types “stop.”
2. Model Invocation: For each query, the
LLMChainsends the question to the GPT4All model, retrieves the response, and prints it.
3. User Interrupt: The loop breaks when the user types “stop,” effectively ending the chatbot session.
# Continuously ask questions until the user interrupts
while True:
query = input("Ask a question (type 'stop' to end): ")
if query.lower() == "stop":
print("Stopping...")
break
result = llm_chain.invoke(input={"question": query})
print(result['text'])
In this step, we use LangChain to create a chatbot that can answer user questions. The chatbot keeps running until the user types “stop.”
Get GitHub code: click here
Conclusion
In this tutorial, we demonstrated how to set up a GPT4All-powered chatbot using LangChain on Google Colab. We compared the response times of two powerful models — Mistral-7B and Llama-3 8B-Instruct — and successfully created an interactive chatbot.
GPT4All offers a robust solution for running large language models locally, making it a great choice for developers who prioritize privacy, low latency, and cost-efficiency. By combining GPT4All with LangChain, you can build complex, flexible AI-powered applications.
Whether you’re working on chatbots, document analysis, or other NLP tasks, this stack provides a powerful toolset to bring your ideas to life. Experiment with different models, fine-tune your workflows, and take advantage of the flexibility these frameworks offer.
Happy coding! 🎉
👨🏾💻 GitHub ⭐️ | 👔LinkedIn |📝 Medium
Thank you for your time in reading this post!
Make sure to leave your feedback and comments. See you in the next blog, stay tuned 📢
Enjoyed this article? Check out more of my work:
- Unlock the Future of Document Retrieval: Dive deeper into the cutting-edge approach of Hypothetical Document Embedding (HyDE) combined with Retrieval-Augmented Generation (RAG) to revolutionize how queries and documents interact. Read more here.
- Run LLaMA3.1 and Gemma2 with Ollama: Learn how to run LLaMA3.1 and Gemma2 models locally or on Google Colab using Ollama. Find out how here.
- Supercharge Text-to-Speech with Piper TTS: Find out how to achieve 10x faster, real-time, offline voice synthesis with human-like accuracy in this hands-on Google Colab tutorial. Transform your text into lifelike speech here.




