
DOS via a billion laughs 😈
Consume arbitrary much RAM by repeated referencing
The billion laughs attack is known since 2003 (source). The attack uses the references in XML files to make a small source file be huge in memory if all references are expanded. It’s also known as a LOL bomb, XML bomb, or in a variation as a YAML bomb and git bomb. It is a type of denial of service (DOS) attack as it can bring a service down.
Why you should care
This is a bit too specific to be visible in many news articles. However, there are several big projects which were vulnerable over the years:
- 2003: libxml2 was vulnerable (CVE-2003–1564)
- 2015: MediaWiki was vulnerable (CVE-2015–2942)
- 2016: libxml2 was vulnerable … again (CVE-2016–3705)
- 2016: HTTP/2 header compression was used to build an HPACK bomb (CVE-2016–6581)
- 2019: Kubernetes was vulnerable (source, CVE-2019–11253)
- 2019: c3p0 (JDBC database drivers) was vulnerable (CVE-2019–5427)
How it works
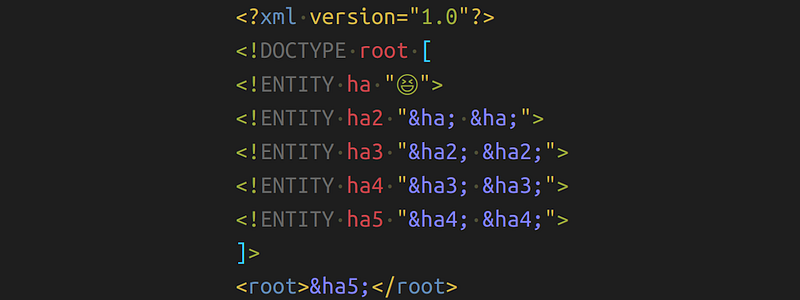
The following XML defines an entity ha , then an entity ha2 which contains ha twice. This pattern is repeated. This means ha5 contains ha indirectly 16 times. You can see the exponential growth, can’t you?
<?xml version="1.0"?><!DOCTYPE root [
<!ENTITY ha "😆">
<!ENTITY ha2 "&ha; &ha;">
<!ENTITY ha3 "&ha2; &ha2;">
<!ENTITY ha4 "&ha3; &ha3;">
<!ENTITY ha5 "&ha4; &ha4;">
]><root>&ha5;</root>With ha31, we would have 2³⁰ times 😆 . That is a billion laughs. Please note how asymmetric this is: With a document that is less than 1kB big the attacker can make the parser consume about Gigabytes of memory. This can easily consume all memory of a machine and thus render it unusable until the parser is killed or the machine is restarted.
A slight variation of the billion laughs attack is called quadratic blowup.
Please notice that similar attacks are possible in other file formats such as YAML. The key point here is that those formats have references.
How can I defend against a billion laughs?
Assuming that you cannot control the input directly and prevent XMLs with attacks from reaching you at all, I can think of 4 measures:
- Lazy evaluation of references: Instead of evaluating the whole document at once, the references are only resolved when necessary. It might solve some issues.
- No evaluation of references: Throwing the dangerous feature out of the window for sure means that you’re not vulnerable to the attack anymore. You need to make sure it doesn’t affect your users, though. Communicating this might be hard.
- Reference recursion depth limit: The parser itself could be aware of this issue and have a threshold when it stops evaluating references. However, this might also lead to false-positives — documents that get not parsed, because the parser thinks it’s an attack.
- RAM restriction: You can run the code that might execute the billion laughs attack under resource restrictions. This means the execution thread/process receives a (catchable) exception and can continue execution normally. It might especially mean that even if the exception is not thrown, the rest of your system might be fine. Only that thread/process might be killed.
So, how do you do this with Python?
For XML, the simplest solution is to use the defusedxml package as pointed out by Diederik van der Boor (thank you!)
The resource restriction is easiest:
Restricting the parser is sometimes possible, sometimes not. It depends on your parser. Some have parameters like resolve_entities (lxml).
Limiting the maximum decompression size was done against the HTTP/2 “HPACK” bomb (source).
See also
Kate Murphey wrote an awesome article about git bombs, check it out!
What’s next?
In this series about application security (AppSec) we already explained some of the techniques of the attackers 😈 and also techniques of the defenders 😇:
- Part 1: SQL Injections 😈
- Part 2: Don’t leak Secrets 😇
- Part 3: Cross-Site Scripting (XSS) 😈
- Part 4: Password Hashing 😇
- Part 5: ZIP Bombs 😈
- Part 6: CAPTCHA 😇
- Part 7: Email Spoofing 😈
- Part 8: Software Composition Analysis (SCA) 😇
- Part 9: XXE attacks 😈
- Part 10: Effective Access Control 😇
- Part 11: DOS via a Billion Laughs 😈
And this is about to come:
- CSRF 😈
- DOS 😈
- Credential Stuffing 😈
- Cryptojacking 😈
- Single-Sign-On 😇
- Two-Factor Authentication 😇
- Backups 😇
- Disk Encryption 😇
Let me know if you are interested in more articles around AppSec / InfoSec!