
Denoising and reconstructing dirty documents for optimal digitalization

I participated in the Denoising ShabbyPages competition at kaggle where the goal is to denoise dirty documents. You are given image pairs, where one is a cutout of a (clean) document while the corresponding other is a dirty version. These snippets were made ‘unclean’ with the Augraphy Python library.
Augraphy is a Python library that can randomly distort images of documents so that it mimics paper printing, faxing, scanning and copy machine processes. You can build very realistic pipelines that can help you with data augmentation for your deep learning projects.
The task was to clean them up as much as possible, effectively reversing the Augraphy noise. This has practical applications in the real world. Having an effective way to clean physical documents helps them being better captured in digital form. Here is a typical example:

Some time ago I wrote about image manipulations for data augmentations for OCR. This was more destined for individual words or sentences while Augraphy is more tailored for complete pages.
Note that is applicable for more traditional OCR engines. One could argue that transformer based models for document understanding are trained to deal with noise inherently. Preprocessing text images would be unnecessary in this scenario. See for example these examples from GPT-4V(ision):


Approach
I started out with the Pix2pix model. It translates one image to another with conditional adversarial networks. It can be useful in many creative ways:

If we feed into this model our training pairs, it should be able to clean up the noisy image. The paper was groundbreaking in 2016 but shows its age nowadays. Playing around with training parameters didn’t give me any better results than the ones below, which I would catalog as barely acceptable at best:


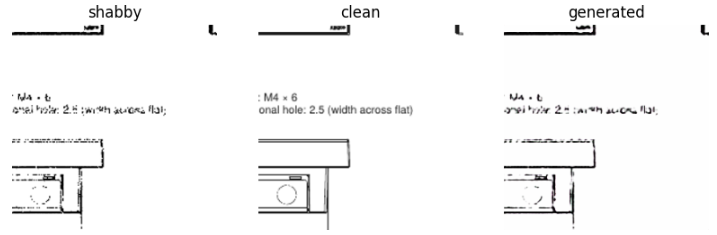

Next up was the MIRnet-v2 model. This came out in 2022 and has a novel feature extraction model from coarse-to-fine attempting to preserve the original feature information at each spatial resolution. After some experimentation I ended my final training run with a PSNR of 21 and a SSIM of 0.87.
PSNR: the higher the better, typical denoising values range from 20–35 SSIM: how much do two images look like each other on a range from 0 to 1, where 1 is completely the same

Notice the damaged characters, you can see there is some reconstruction happening. But can we do better? My competitions scores were still at the lower end. So I tried also the Restormer (Restoration Transformer) model.
It’s based on transformer blocks that each time focus on a smaller patch size. You can also recognise the usual (de)construction U shape here.
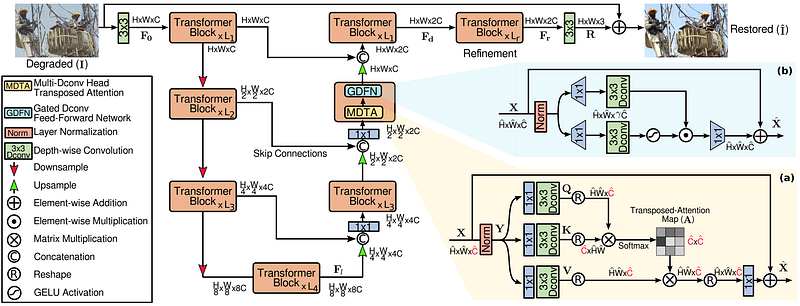
Initial results were promising, so I optimized the training parameters and also enlarged the dataset. Originally you were given a 1000 something images pairs to train on, I created 5000 more, while also including some samples from the previous competition.
In the end I got a PSNR of 31.4 after training for 100k iterations over 9 hours using multiple patch sizes. This landed me somewhere in the middle of the leaderboard of the competition. More on that later.
Here are some samples of what the trained model achieved on the competition images. Besides being very competent at removing the background noise, notice that the faint portions of the letters are reconstructed and also the marker lines disappear. the restored results are now ideal to be fed into an OCR engine.




Scoring
The competition score is calculating the RMSE of submitted random pixels for each of the 300 images in the competition test set. In my experience however, after a certain point, my score didn’t improve while the PSNR of my validation set got higher and higher. A visual inspection confirms that letters were in fact being better restored, despite the competition score not improving. This is because of the RMSE metric. It penalizes uneven gray levels between the clean and restored image, while it could be that the restored image is actually more fit to be converted by OCR.
This had the perverse effect that introducing postprocessing effects such as gaussian blur and median filters lead to higher competition score. While it certainly will not help the ultimate goal of digitization.

Above are samples where the ‘clean’ image contains a gray background. The denoiser does its work well, feeding this to an OCR engine would give better results but it gets penalized for removing the gray background by measurement of the RMSE.
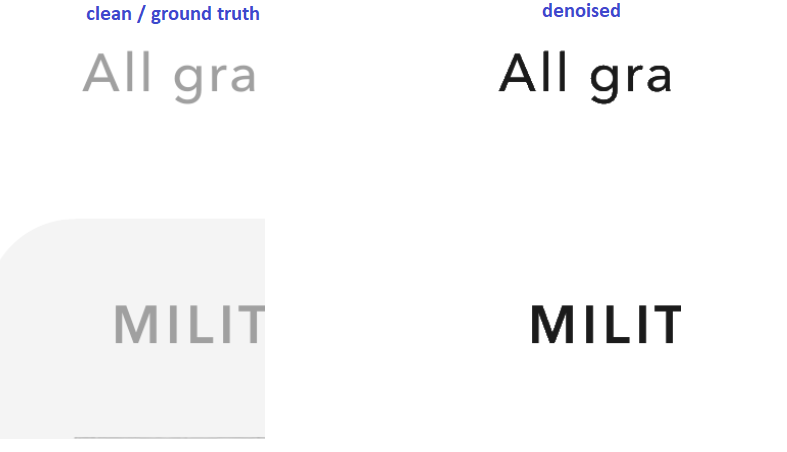
Here you have the additional problem that the source text was light gray, while the denoised is more black and easier to OCR. This would get penalized as well.
Ideally, the score for this competition would have been calculated by actually performing OCR on the clean images and comparing it with OCR done on the denoised set. Of course this would make matters much more complicated.
Conclusion
I successfully trained the Restormer architecture for the task of cleaning up damaged text from dirty documents. A huggingface demo space was created by me where you can try it out yourself and download the pretrained model. There are also new architectures that came out, so results in this field will further improve in the near future. However, as I have mentioned, it could be that this method will be made obsolete by models like GPT-4V that don’t seem to be as affected by noise.
You may also like:
Links:





