
Computer Vision: How to tackle the problem of class imbalance in image datasets?
Here are 4 things you could do if you have 200 images of dogs and only 35 images of cats

If you have been following my previous articles, I have shown why real-world datasets are always flawed and imperfect, and how numerous problems would surface once you get to the point of exploring your image data with code. Today, let’s examine a problem widely encountered in the machine learning community, specifically in computer vision, where there exist different number of images for each of your class in your dataset. Enter the problem of class imbalance.
Real-world datasets are flawed and imperfect. Learn how to use them.
From my previous internship as an AI Research intern, I was tasked with numerous computer vision projects and for the most part, I had to analyze image datasets and obtain a base model to output the necessary metrics before we started working on improving it. Usually, we should find out all the problems we have with our dataset beforehand, so that when the base model is built and evaluated, the only improvement we can work on is on the model itself. More often than not, one of the problems that I usually encounter is that my dataset has imbalanced classes of images. I used to worry a lot about this problem and even thought there basically were no solutions other than going back to the wild and collecting more images. Fortunately for me, I learnt the hard way that there are indeed a few steps that I could possibly try out before deciding that I should gather more images.
In this article, I am going to help you visualize the difference it makes by using all 4 techniques to fix the class imbalance problem.
Here, I have a base model working on imbalanced classes of dogs and cats.
/Training: /Cats — 300 images /Dogs — 500 images/Validation: /Cats — 100 images /Dogs — 200 images/Test: /Cats — 100 images /Dogs — 200 The results look like this:
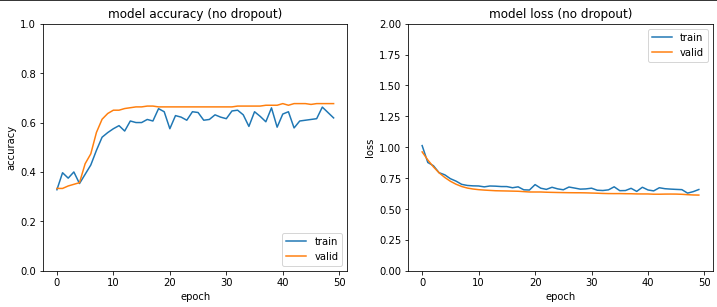
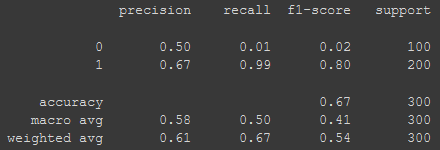
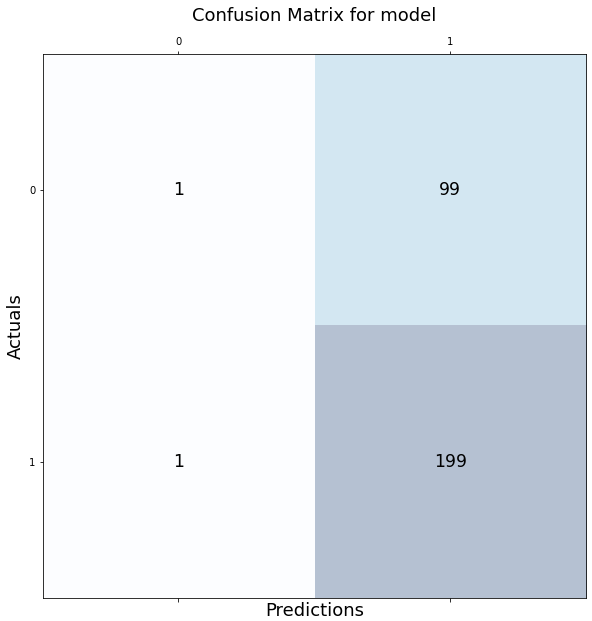
I will use all 4 techniques and show you the difference it makes in your model. We will start with undersampling first. Let’s go!
1. Undersampling
Simply put, undersampling is a technique where we would sample or select randomly (or with a formula) a set of images from the class with the greater number of images so that the class would end up with the same number of images with the other class(es). A more proper definition is that it is a technique to balance uneven datasets by keeping all of the data in the minority class and decreasing the size of the majority class. I can’t stress enough how this was a life-saver for me when I was working on image classification tasks. Undersampling image classes helped me reach a point where both classes have the same number of images, albeit still considered low for deep learning but definitely sufficient to qualify as a working dataset for the base model.
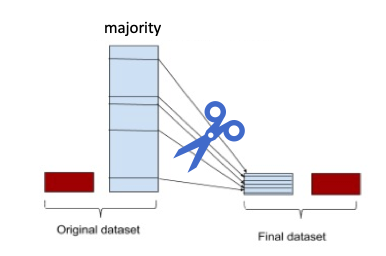
But of course, with undersampling comes a set of complications too. First of all, you definitely lose relevant information from the majority class and eventually the model will not be able to learn from the dataset. Usually, you will be able to notice the effects as you plot the metrics graph. One super helpful Python package that you can look into is definitely the imblearn package, where it has some handy functions to help you fix the problem of class imbalance either by using undersampling or oversampling.
I’ll save you the hassle of reading code here by sharing the links to where I get help most of the time:
With undersampling, my file structure now looks like this:
/Training: /Cats — 300 images /Dogs — 300 images/Validation: /Cats — 100 images /Dogs — 100 images/Test: /Cats — 100 images /Dogs — 100While the results look like this:
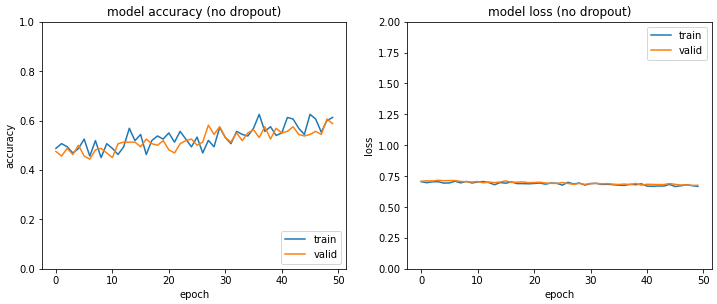
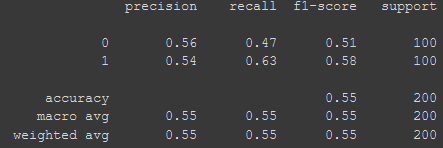
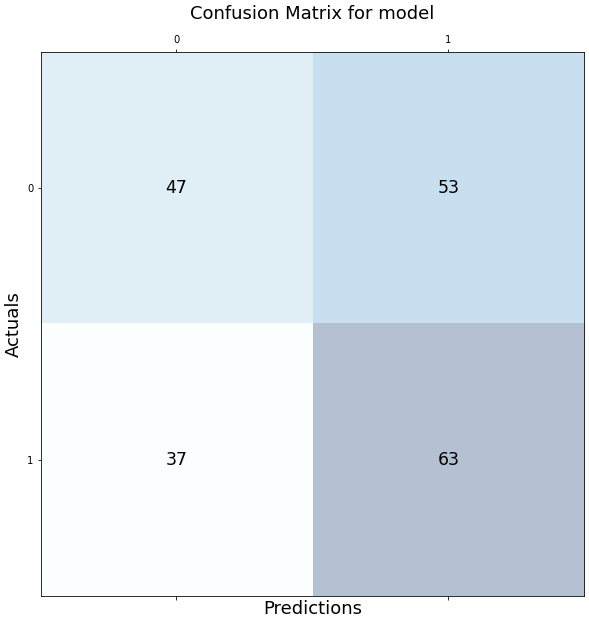
As you can see, the model did not actually improve. However, what we can take away from these metrics is that the model is currently not biased towards any class at all! The confusion matrix simply tells us we probably need more images and from here, we can already safely proceed to gather more images.
Now let’s look at the technique of oversampling.
2. Oversampling
Oversampling is basically the opposite of undersampling, where you would duplicate random images from the minority class or synthesize images from what you already have in your minority class using specific algorithms or methods. In return, all your classes have the same number of images but with a caveat: overfitting of your model. Because there exist duplicates within the minority class(es), the model might end up learning only the patterns specific to the minority class and might never learn to generalize.
Again, there is a well-done tutorial on one of the most popular algorithms for oversampling, Synthetic Minority Oversampling Technique(SMOTE):
However, the catch here is that for image data, it is hard to basically synthesize images that belong to the original dataset distribution, hence the method of oversampling would basically mean to gather more images for the minority class until all classes have about the same number of images.
It is still worth putting in the time to pick up the skills of SMOTE, for it will come in handy the next time you work on data-lacking problems.
3. Merge similar classes
This method is only useful if you are working on multiclass-classification problems. In a multiclass classification problem, there could be minority classes that share similar features (or maybe not) and by being able to identify classes that can be merged into one can probably save you the time on gathering more images. For example, if you have a file structure similar to the one below, you could group the minority classes like penguins, lizards, snakes and parrots together and make that a new class for your model to train on.
/dogs (3972 images)
/cats (3956 images)
/penguins (219 images)
/lizards (128 images)
/snakes (127 images)
/parrots (278 images)
Clearly, this step takes a lot of domain knowledge in order to make such a decision. Depending on your use case, it might be wise to consult an expert in the field or clarify the end goal of the project with your supervisor before merging any classes together.
4. Data Augmentation
Last but not least, if you still want to write code to increase your image class size, data augmentation is also a definite method for this purpose. Data augmentation in data analysis are techniques used to increase the amount of data by adding slightly modified copies of already existing data or newly created synthetic data from existing data.
If you read it carefully, the modifications are only in the slightest effects possible and for this reason, it is only acceptable to use this method if the difference between the minority and majority class is not too huge. After all, data augmentation cannot possibly fill the gap between the minority and majority class in terms of the number of images. Still, it can make modifications to the images such that the model “sees” new images.
Using OpenCV or any imaging libraries like PIL or scikit-image, here are some changes you can apply to any image to turn it into an image the model has never seen before:
- Geometric transformations such as flipping, cropping, rotation, translation etc.
- Color space transformations such as changing the color space of an RGB image to a HSV image
- Kernel filters like sharpening or blurring an image
- Mixing/merging images
However, if you are looking for data augmentation libraries, there are some useful ones that do the job quite nicely, such as:
pip install albumentationpip install Augmentorpip install imgaugFinally, if you are really ambitious and are looking at new ways of generating new data, look no further than GANs although I might not exactly recommend it. It does, however, provide an alternative to the pool of solutions above if you are running out of them. State-of-the-art GANs are able to generate high quality human-proof images, but this will require a large amount of computing resources, so it’s probably best to stay away from this if you’re unsure of what you’re doing.
To sum up, I have shared 4 tips on how you can solve the problem of class imbalance in your image classification task, but generally, the steps are applicable to any machine learning problems. I hope you are able to learn something from this article as I try to share from experience of working on real-world datasets.
Check out my Github if you are looking for some references:
References for this article:





