Handling imbalanced dataset in image classification

I have been working on test task of detecting volcanoes on images from radar. Images have dimensions 100x100 pixels and single channel. The training dataset was highly imbalanced (the number of images without volcanoes is 5x larger than these with volcanoes).
There is plenty of ways to tackle this problem like class weights, oversampling the training dataset, focal loss etc.
In this article I will present manual oversampling of the training dataset to tackle the class inbalance problem.
Let’s firstly overview the distribution of classes in the data. Here we see the number of samples per class before oversampling:
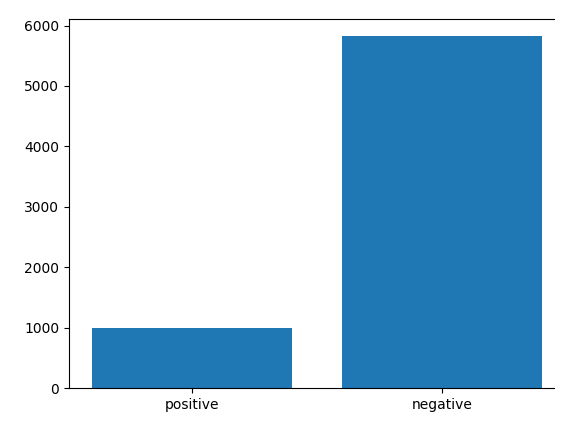
We can see 1K samples with volcanoes and about 6K samples without volcanoes.
Oversampling means that we increase the number of samples in the minor classes so that the number of samples in different classes become equal or close to it thus get more balanced.
Let’s apply manual oversampling when preparing our training samples.
I applied oversampling in method prepareImages:
def prepareImages(train, shape, data_path, mode): for index, row in train.iterrows(): has_volcano = row['Volcano?']
...
if has_volcano and mode == 'train': x_train[count] = img_to_array( cv2.flip( img, 1 ) ) y_train[count] = int(has_volcano) count += 1 // repeat the same step three more times applying different transformation and incrementing countHere we read ‘Volcano?’ attribute of the sample. If image contains volcano we apply some transformation to the original image and add modified image to dataset together with corresponding label. In my case I applied 3 flips (with values 0, 1 and -1) and rotate (cv2.ROTATE_90_CLOCKWISE).
Let’s display class distribution after oversampling
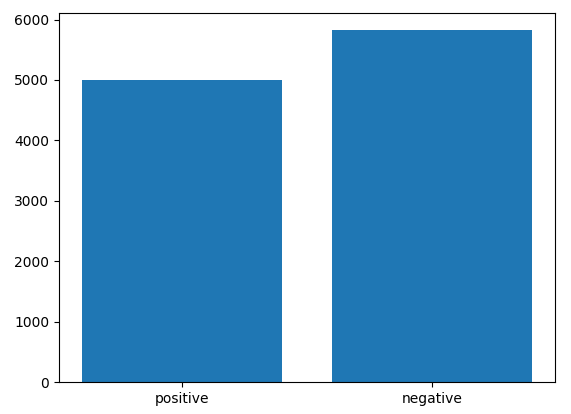
Experimental evaluation of oversampling
Results with oversampling
When not applying oversampling
loss: 0.2359 — acc: 0.9202 — val_loss: 0.4253 — val_acc: 0.8626AUC = 0.500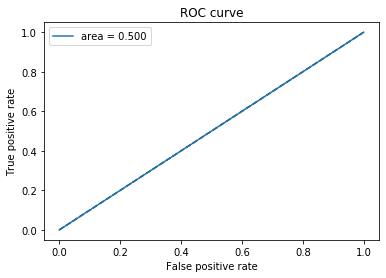
and loss / accuracy plot
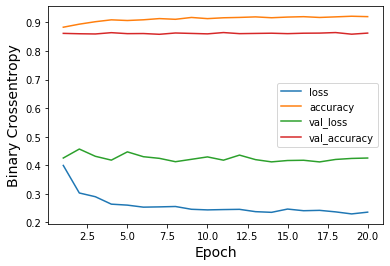
When perform predict on test dataset we get following results:
number of images with volcanoes: 0number of images without volcanoes: 2734We can see that all the test samples were classified as having no volcanoes.
Results with oversampling
When we applying oversampling
loss: 0.6885 — acc: 0.5264 — val_loss: 0.6856 — val_acc: 0.5718AUC = 0.504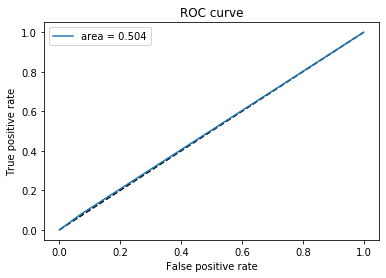
and our learning curves
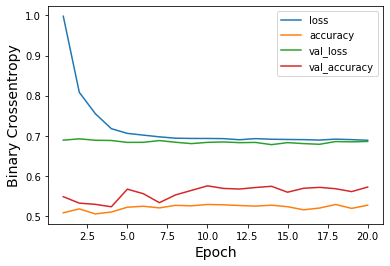
When perform predict on test dataset we get following results:
number of images with volcanoes: 27number of images without volcanoes: 2707That’s it.