Classification and Regression Trees
This is my second post about machine learning algorithms. My first post is about artificial neural networks, you can find it below.
Our topic for this post is decision trees which is one of the first algorithms to learn as a beginner in data science. It is used in supervised learning and it is a miraculous algorithm that is used for both classification and regression, plus it does not require dummification of the categorical variables which can be highly problematic for some machine learning algorithms. Here’s my summary for decision trees. Enjoy!
Decision trees are very important in machine learning because methods based on trees are straightforward and easy to interpret. In terms of prediction accuracy, they frequently fall short of the finest supervised learning techniques. There are also bagging, random forests, boosting, and Bayesian additive regression trees. In each of these methods, numerous trees are created and then joined to produce a single consensus prediction which is called ensemble learning. Integrating a lot of trees can frequently lead to huge gains in prediction accuracy at the cost of some interpretation loss.
Decision trees can be used in unsupervised learning, too. Unsupervised learning is a machine learning method where you don’t have labelled data as in supervised learning. Instead of making a prediction for a future cases based on the historical data, you can gain insight about your data applying clustering methods. If you are curious about clustering, check out my post about it here!
Classification and regression trees are also known as the CART algorithm or the CART model. These trees are models that use yes/no questions to make predictions. These models can be a classification model as well as a regression model.
However, they are not preferred in regression problems because they give an average value for a group of observations.
In classification models, the predicted variable is a class, as in a competition on Kaggle.com, Titanic. The classification tree is supposed to predict if the people have survived the disaster or are dead.
Famous Chihuahua vs Muffin classification is a good example of a classification problem. It is a model that predicts if a given picture is a dog.

A regression problem or a regression tree, however, predicts a numerical value. A good example on Kaggle.com is Housing Prices where the predicted variable is the price of a house. I recommend beginners play with these datasets.
A decision tree is drawn upside down with its root at the top. Order and data on the left side don’t necessarily have to be the same as on the right. Final classifications (outcomes) can be repeated. An example of a visualization of a decision tree is as follows.
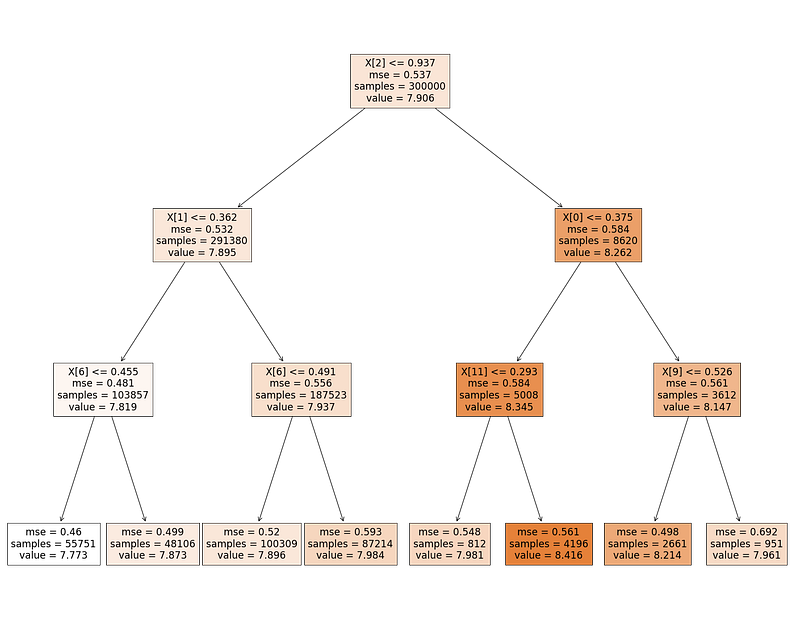
In this decision tree, you can see many features denoted by X[n]. The first split of the tree is in X[2] feature and the threshold value is 0.937. There are 300.000 observations in total. After the split, there are 2 groups of observations (which is always the case). You see 291.380 of the observations on the left side, whereas the rest (8620 observations) is on the right side. The first group (the group on the left) is the group for which the condition in the box on the previous level is true.
In the second stage, 291.380 observations on the left are split into two groups again, this time the feature is X[1] and the threshold is 0.455. This threshold splits the group into groups of 103.857 and 187.523 observations.
Applications
Decision trees have many application areas. I gathered some of them below.
- Decision trees are guiding for identifying features to be used in implantable devices in biomedical engineering.
- They are beneficial predicting customer satisfaction with a product or service financial analysis.
- They are used in astronomy in classification of galaxies.
- They are used in system control.
- They are used in manufacturing and production, areas such as quality control, semiconductor manufacturing, etc.
- They are used in medicine, in diagnosis stage, cardiology or psychiatry.
- In physics, they are used for particle detection, etc.
How it works
The algorithm selects the best attribute using Attribute Selection Measures to split (like Information Gain, Gain Ratio, or Gini index), makes that attribute a decision node, and breaks the dataset into smaller subsets.
The decision tree algorithm requires only the following elements to form:
- Features that vary to split the data,
- A rule to decide which feature should be used in splitting,
- An approach for finding a tree of the right size.
A tree is built by the repetition of this process for each child until one of the conditions below matches:
- All the tuples belong to the same attribute value.
- There are no more remaining attributes.
- There are no more instances.
There is an issue to be addressed though:
A worthless split early in the tree might be followed by a very good split. A better strategy is to grow a very large tree, and then prune it back in order to obtain a subtree.
To do this, we can perform cross-validation and check when the error metric diverges from the training error metric.
Pros
Decision trees have many advantages.
- Trees can easily handle qualitative predictors without the need to create dummy variables.
- It can easily capture non-linear patterns in data.
- It has a very simple form, so it can be understood and hard-coded easily.
- It requires fewer data preprocessing from the user, for example, there is no need to normalize or standardize columns.
- It can be used for feature engineering such as predicting missing values and is suitable for variable selection.
Cons
On the other hand, decision trees may be problematic, too.
- Decision trees are sensitive to noisy data. Models using decision tree algorithms may lead to overfitting.
- The small variation (or variance) in data can result in very different decision trees.
- Trees generally do not have the same level of predictive accuracy as some of the other regression and classification approaches.
- Decision trees are biased with imbalanced datasets. To use decision trees with imbalanced data, oversampling or undersampling methods should be used first.
When should decision trees be used?
Decision trees are a sort of machine learning technique that can be utilized in a range of applications. They are frequently used in classification problems, where the goal is to predict a category outcome using a set of features.
Decision trees have the primary benefit of being simple to comprehend and analyze. When describing the outcomes to others, it can be useful to be able to demonstrate precisely how the model is generating predictions thanks to its tree structure. Decision trees can handle big datasets and a lot of features, and they are also reasonably efficient to train.
When there are few possible outcomes or when those outcomes are mutually exclusive, decision trees are a viable option. They are also a wise option in cases when there are nonlinear interactions between the features and the result. Decision trees, however, are susceptible to overfitting, particularly if they are deep and have a large number of branches.
These were the basics of decision trees. I will be posting more about them, so please follow me to see my posts in your feed. If you want to learn more about classification and regression trees, check this out!
If you are looking for more classification algorithms, check out my post below!
If you found this article useful, please give it a clap and share it with others.
Thank you!
This post may contain affilliate links.