
Avoid This Problem When Making Predictive Models for Finance
Are you showing your model the future by accident?

An accurate price prediction model — truly the holy grail of finance and something that everyone wants. I have tried, and ultimately failed to create one of these; however there were times where I could taste the success by having a model that performed excellently on my testing data.
Naturally, this was incredibly exciting, not only did I think I cracked a tricky problem, but I was going to get super rich in the process. However, failures are opportunities to learn; hopefully by reading this you’ll avoid my mistakes and in doing so, have a better hope at success than I did.
In this article I will talk about one of my mistakes. In short, I inadvertently showed my model the future result. It sounds easy to avoid, right? However, trust me when I say it’s a lot easier to include this error than you may think!
If you read on, you’ll see how I introduced this error when pre-processing the data, and also, how to properly avoid this! I hope you enjoy and learn from my mistakes 🙂
The Problem
To put my error into context, let’s try and put together a Neural Network that predicts if the next day’s closing price will be higher than the previous for SPY, TSLA, AAPL, GOOG and AMZN. This is the framework we will adopt:
- We will use the past 25 days of open, low, high, close and volume data as the features (i.e. an input of length 125).
- The output will be either 1 (price increase), or 0 (price decrease).
- A standard vanilla (dense-layered) neural network will be used for simplicity (no fancy LSTM layers here).
- The training/testing split will be 85%/15%, and randomly shuffled.
The reason this neural network is being made is to show how accidentally including the mistake can give you unrealistic and suggestively good performance, and how fixing it brings you back down to Earth.
Pre-Processing: The Mistake
Stock price data is notoriously noisy, even with an index fund ticker like the SPY. This makes it rather tricky to deal with, and therefore, predictive models could struggle to learn from the data we have.
In the initial development, I thought a good idea was to smoothen my data so that the model has an easier time picking up on macro-scale features. Moving averages introduce a “lagged” element to your features, and therefore perhaps not the best to use. At the time, I opted to use the Savitzky-Golay filter which removes this lagged issue.
Since then, I have developed another (and I think better) method to perform time-series smoothening, solving the heat equation; you can read about this in my article:
This GIF highlights the smoothening process:
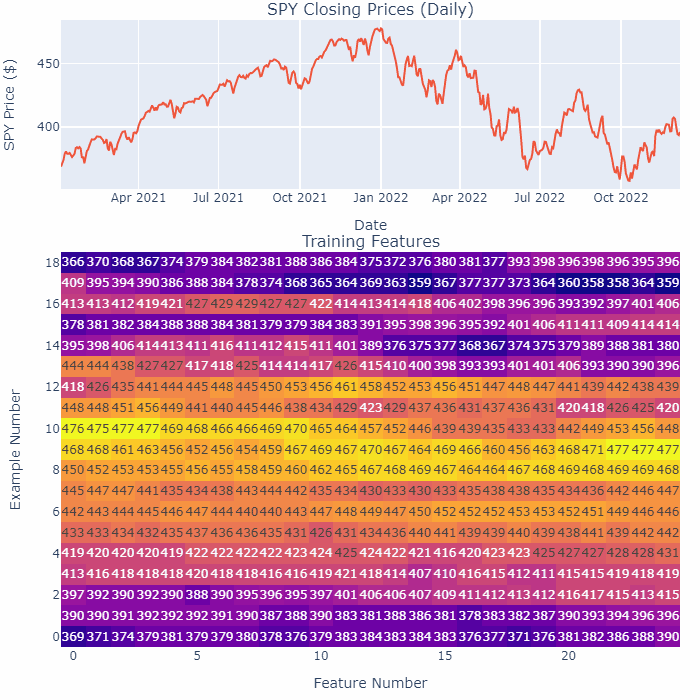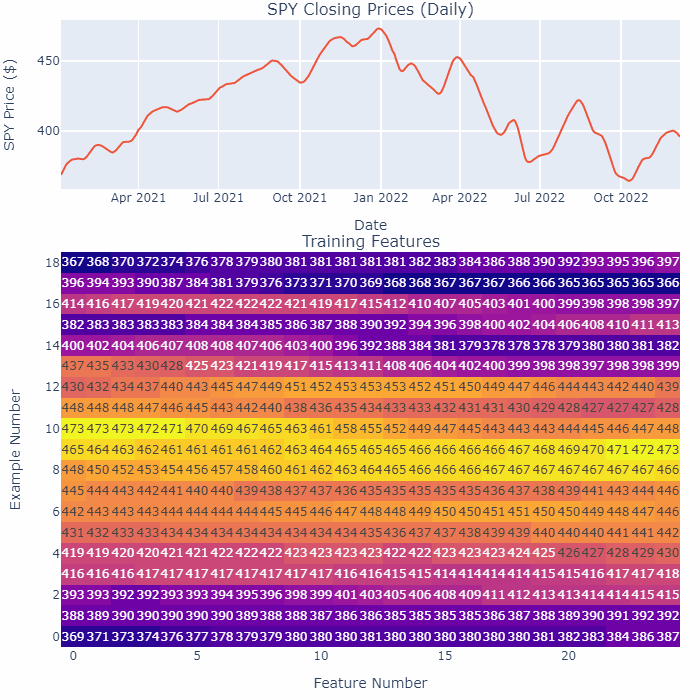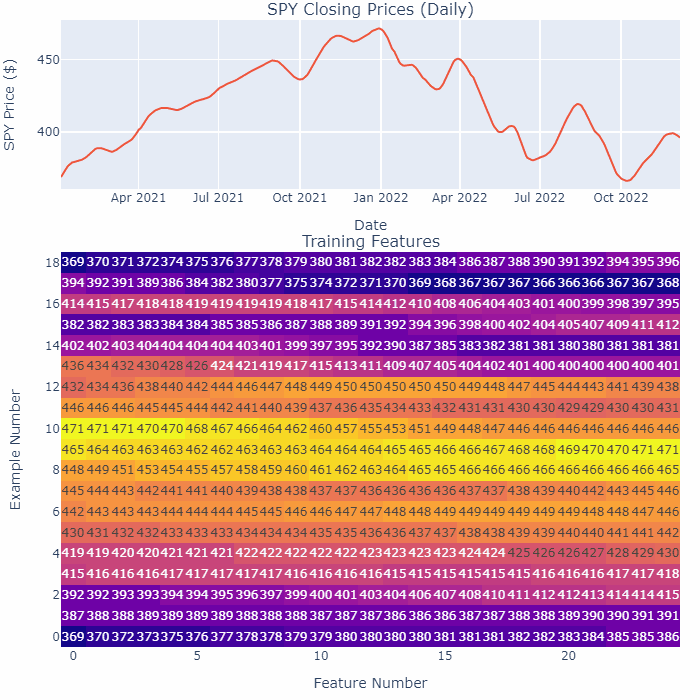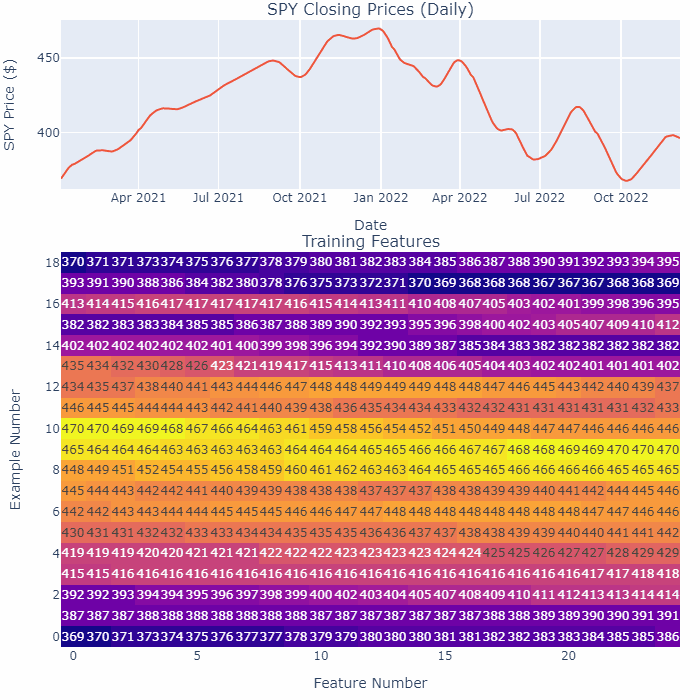
Let’s break this GIF down slightly:
- The top shows the recent closing prices as it is being smoothened, the bottom shows the features we feed into the Neural Network for training (each “Example Number” row is a new feature).
- “Feature Number” here represents each day in the time-series for that feature. I’m only using the closing pices here for illustration purposes.
- Notice how as we are smoothening the time-series, all the numbers in the table are changing.
The bottom line — we are smoothening the entirety of the SPY at the same time.
OK, fair enough — I don’t see the problem?!
Neither did I at first, it’s sneaky how a problem slips in (or perhaps you spotted it immediately and you’re way smarter than me!). Nevertheless, I put together this code to show the performance you’d get after training:
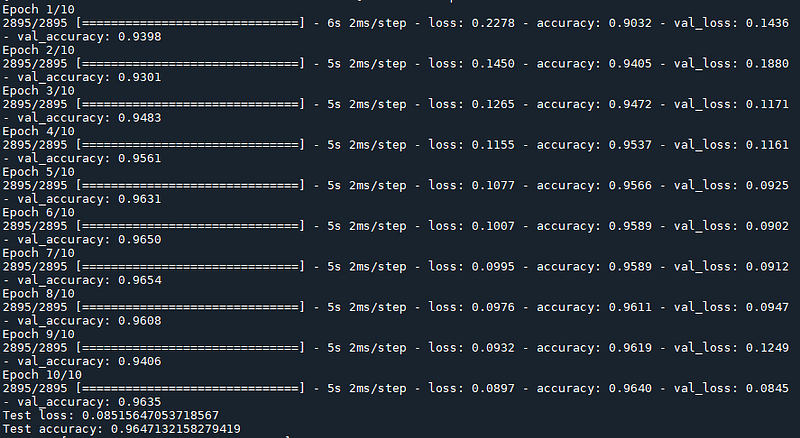
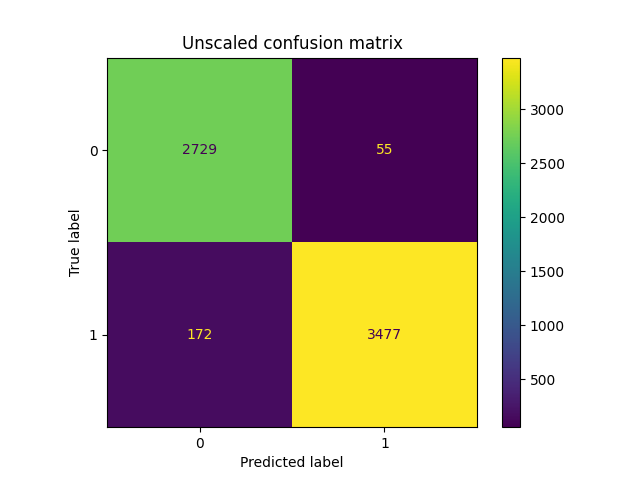
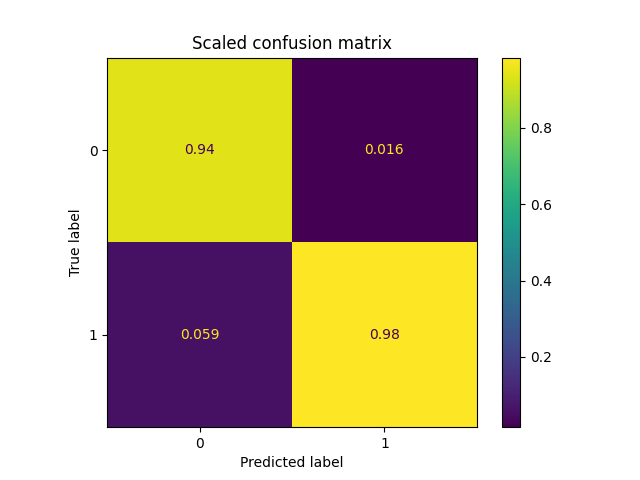
Wow — a model that’s 96% accurate! We are going to be rich!! Clearly this is one of those times where something is just too good to be true (and it certainly is). So what’s the problem?
The issue is that by smoothening the entire time-series at once, we are asking each point to be smoothened in relation to it’s neighbours. In other words, a point in time will be brought up or down depending on the points behind it and in-front of it.
The bottom line — smoothening like this accidentally shows your model the future.
Pre-Processing: The Fix
To fix this we should smoothen in such a way so that the training time-series (i.e. each series of length 25) never sees any future points. This means we should process each time series individually.
As an example, take a look at this GIF:
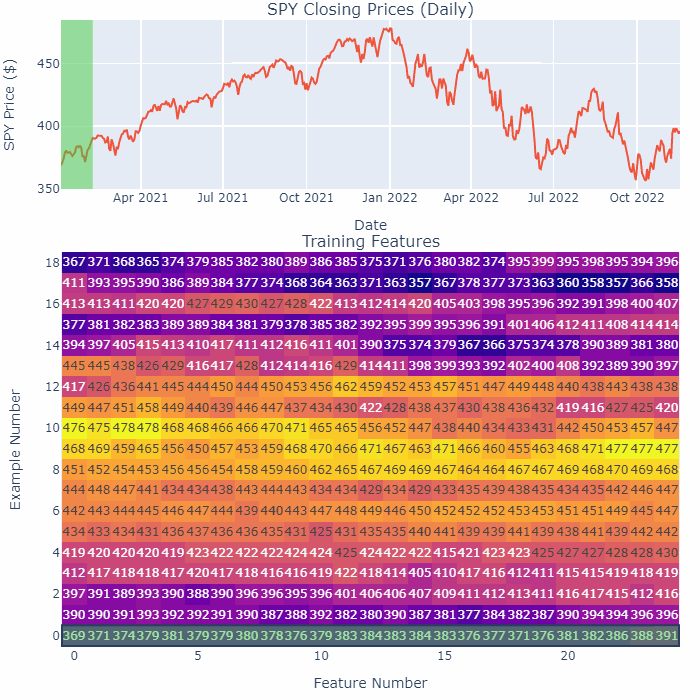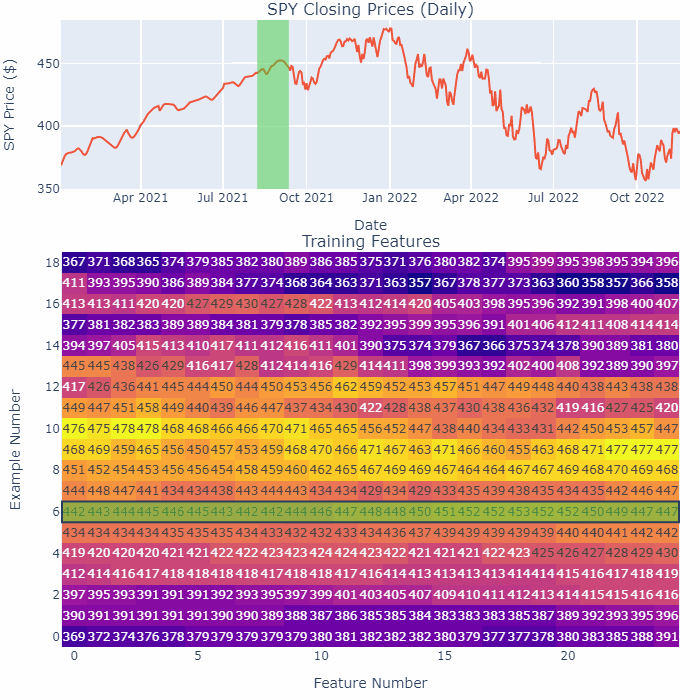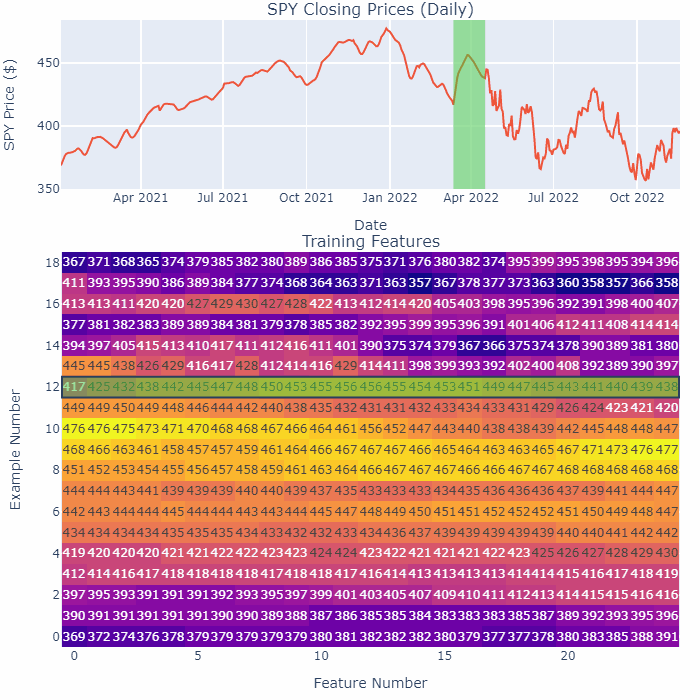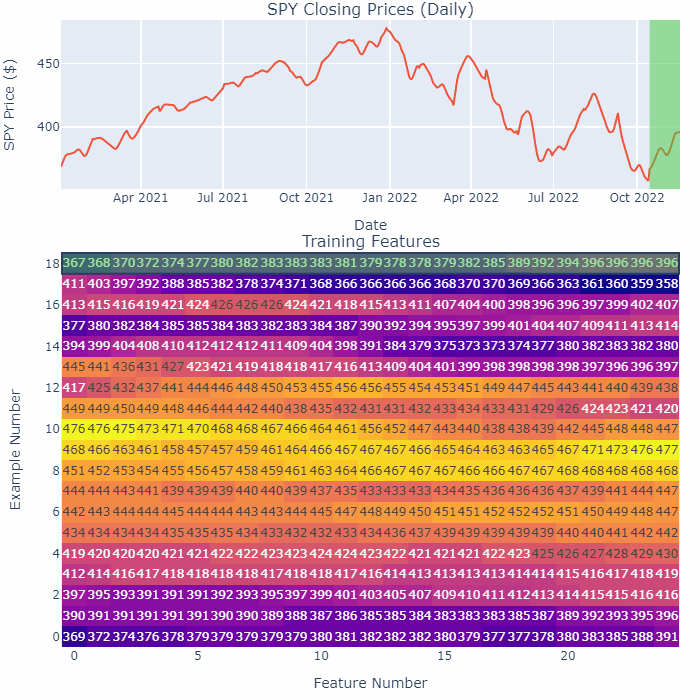
Notice how as we smoothen a small section of 25 days, only one row in the training matrix changes. Also, the end-points do not change at all. This is a safer way of processing the time-series, no future data can leak in this way.
By the way, the method I’m splitting up and smoothening above is purely for illustration purposes. In the actual code, I step one day at a time, look back at the past 25 days, smoothen that series to store as a feature, and then move to the next day. You squeeze out more training data that way.
You can find the full code here, which produced the following results:
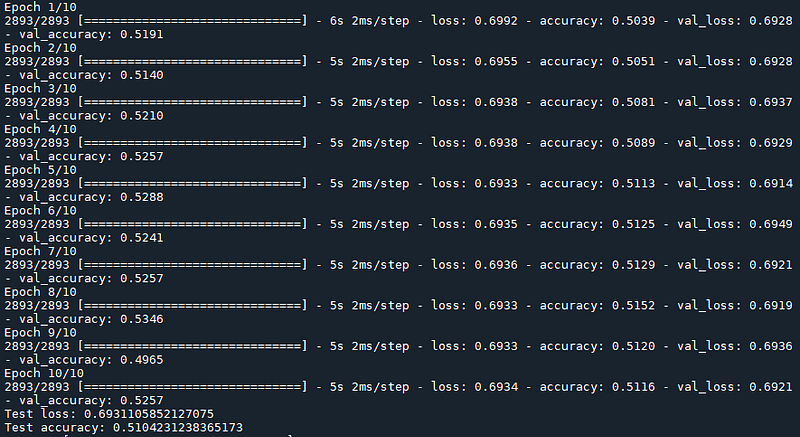
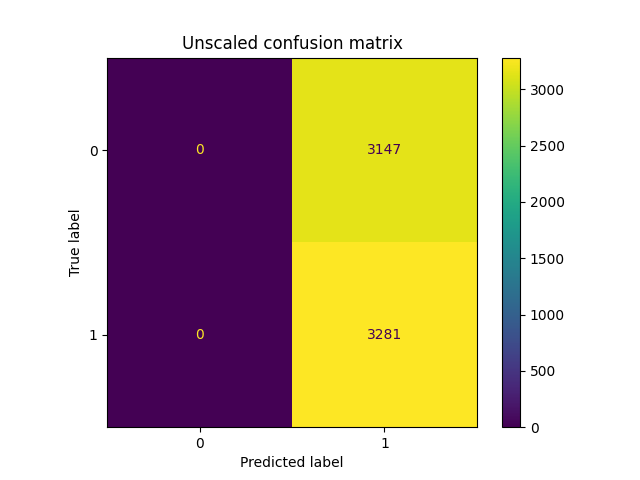
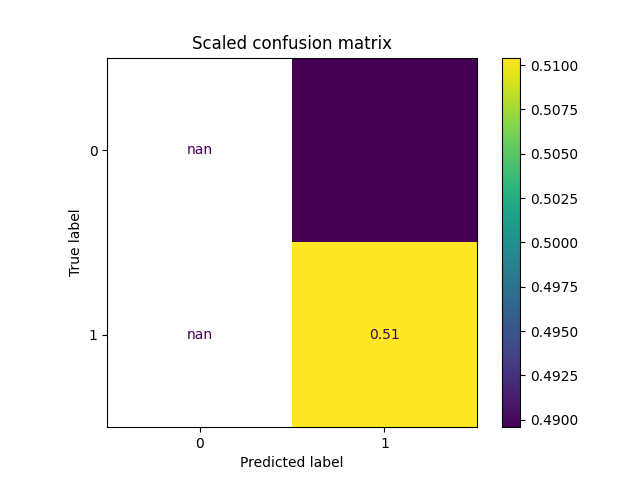
As you can see, the results are significantly worse. In fact, it looks like the model is basically always predicting one single class (and therefore not much better than randomly guessing!). The only change made here was how the smoothening was performed, everything else is the same.
Let me emphasize that this article is not intended to show how to produce a prediction network, but, how to avoid a very easy mistake to make (one that I made myself!). You should not use this code for any live trading.
My Intuition on Price Prediction Models
After trying and failing many times, the one conclusion I have obtained about price prediction is that it’s not an easy task. I believe it can be achieved, but only with the correct sources of data with the correct questions being asked.
To be concrete, having one model to rule them all is likely impossible with just price data, since each asset will not trade the same and have different fundamental drivers. This is something I have been exploring with the granger causality test, which looks for correlated assets using statistical methods — I have an article on this topic:
What Can You Use Neural Networks for in Finance?
Pattern recognition — plain and simple.
Neural networks are fantastic at finding patterns, and the beauty about this is that you can get decent results by thinking “What do I need to see to find this pattern”. I made one to find breakout consolidation patterns, rather similar to what the likes of Kristjan Qullamaggie and Mark Minervini trades. Since I only need to see the price data, that’s all I gave the model (and it’s ~90% accurate so far!).
The basis for this code can be found here, for those who are interested 🙂
Wrapping Up
Hopefully it’s clear to see how you can slip in easy mistakes when making a price prediction model. If anything, I hope this article has inspired you to ask “are my results too good to be true?”, and really really reeeeealllly dig into your work before you’re absolutely sure you’ve struck gold.
If you do happen to strike the jackpot, then feel free to share your results with me on LinkedIn 😉Jokes aside, I’d love to hear if this article has helped you in any way!
Good luck on your trading/investing journey! 🙂
Thank you for reading, I hope you enjoyed the article! Please feel free to connect with me on LinkedIn — I’d love to hear from you! Also feel free to follow/DM me on twitter.
If you are thinking getting a medium account, then please consider supporting me and thousands of other writers by signing up for a membership. For full disclosure, signing up through this link grants me a portion of your membership fee, at no additional cost to you (a win-win for sure!).
Or if you’d like another way to support my content creation, then you could

Because I work a full-time job, go to the gym, trade, and write on Medium, I use a lot of coffee!
Subscribe to DDIntel Here.
Visit our website here: https://www.datadriveninvestor.com
Join our network here: https://datadriveninvestor.com/collaborate




