
Automated quality gate — a rail guard to support the continuous quality
A first step to improve the code quality
In my career, I have been multiple times onboarded in the middle of a project. Ironically, every project starts as a “green field”. But somehow sooner or later, they end up poor or very poor of quality. Over time, it piles up more and more technical debt. The codebase becomes the one we would not like putting our fingers on. It also becomes more difficult to deliver business value to our customer. We would rather start a new revamp it from scratch, right? But no! No stakeholder would pay multiple times to build the same software. There are many reasons why we would end up with such heavy, yet accumulated over time, technical debt.
- First, we work on quickies (quick wins), as we adopt a user centric approach to in software engineering, and that is just a natural way of doing things.
- The design and delivery process is not yet industrialised, thus not having any standard, that also must be defined and spread globally across teams.
- We do not having the right management and tooling to measure and control the quality.
- Team’s standard is not putting the quality as top priority.
- At last, coding (best) practices are more or less present to support the quality goal even if we set up a quality gate.
In this article, we will walk through the first quality gate we just set up.
Before we get there, let’s understand the reason why we would need a quality gate (QG), its goal in the software development process. I suggest we get to clarify the concept of technical debt.
If you wish to have a more concrete experience, I’m writing another article in which I walk through the setup of the first quality gate at TheFork. I’m more than happy to share with you in this article.
Related articles :
- Testing Strategy — toward Agility, a guideline to define testing strategy that better fits in an Agile environment
- Testing Terminology, testing vocabularies and definitions reference
Happy reading!
— — —
Why a quality gate ?
A quality gate (QG) is an important piece in the Software Development Life Cycle. It can be of use to get early feedbacks to reduce cost of defects resolution. It’s also a great tool to help improve the code quality, and simplify the component design and software architecture.
The code analysis generates metrics related to code, then we can if the codebase complies with our standards, and the standard must be defined. In an industrialised way would apply the same standard on all projects within the whole organisation. Then we can talk about quality gate.
The goal of having a quality gate is to first monitor then control the quality aspect on the piece of software we are about to ship to production. Then monitoring requires tooling and metrics. The control necessitates a process and also tooling. If we want to ensure a good quality (or enforce the quality of deliverables), we must monitor the technical metrics, and have a good idea of technical debt we have. And yes! Most projects (close to 99.99% of them) have technical debt.
Technical Debt
When we are in debt, we are in trouble and we must pay it sooner or later, or we go bankrupt. The same goes for software, and for the technical part, we call it technical debt. That is everything related to technical aspect in the design, build and run phases. The technical debt describes the results of actions (or consequences of decisions) to ship a functionality or a piece of software as part of a project which later needs to be refactored or revamped.
When we design a system (sub-system, components, module or block of code), sometime we are confronted with multiple options. So then we need to choose. And almost every decision comes with benefits and drawbacks. In the perfect world (with ideal options only), we wouldn’t have any drawback, so we won’t have to talk about technical debt. Right? For example, do we build an in-house solution or is it better buy a software to serve the purpose? A home made solution requires times to build and effort to maintain, while buying an existing tool requires to deal with a separate line of budget and put efforts to integrate the tool. Another case is when we have a deadline (I don’t like a deadline, but it’s there), so we would take a shortcut either in the design or build phase, such as quick and dirty code, omit writing tests and/or documentation. And a shortcut comes with a price that later we need to pay. That’s the drawback. That’s the technical debt.
Technical debt is not only about code, but also about product design, UI/UX, infrastructure, CI/CD toolchain, system architecture, software architecture, testing automation, manual testing… you got it right?
We won’t discuss about all aspects of technical debt, but rather focus on the code level problematic. In other words, we want to enforce the quality in our build phase, thus enforcing our development practices.à
I suggest we explore the tow following questions, which are of much interests, because they are the pain points from the developer’s point of view :
- Why do we dislike a poor quality codebase ?
- Why is it like that, and why can’t we get rid of bad quality code?
- What are the impacts and risks ?
Why do we dislike the codebase ?
Like I stated earlier, every project started as a “green field”, and we as developers like that. Who does like freedom? When starting a project from scratch, we have a chance to experiment new things, to introduce a framework, technologies or new patterns. We would also have a “second” chance to make things better. And it would likely be better than the previous project anyway.
At the opposite, “better” does not mean perfect or good (or good enough). The project would eventually end up as a mess, because we cumulate the technical debt over time. Some part of the codebase may be clean, but what about the rest? Many people refer to existing project as “legacy”. Ironically speaking, projects (99%) eventually become legacy (referring to a popular definition). It’s just a matter of time.
I won’t debate on the definition, I do have my own : “code becomes legacy once it is delivered and deployed”. But here I refer it as a combination of :
“Code without tests”, by Michael Feathers.
“Legacy code is source code that relates to a no-longer supported”, from wikipedia.
No many people like working with legacy. A few like that though, as it is interesting and challenging, simply because that’s the reality every is facing. Myself do not like legacy codebase. I rather prefer working on a cleaner environment.
Why is like that, and why can’t we get rid of bad quality code ?
How comes most projects hit the poor quality issue? Even with good discipline, rigour, intention and motivation, we still have pile up technical, as explained earlier. At a point of time, we need to make a decision, choose one option over another, that comes with drawbacks in the balance. We all want to care about the code quality, we all wish to write perfect (close to) code, that works with zero hassle, 100% of code coverage, zero bugs, zero security issue, flexible, easy to scale, easy to re-use, easy to maintain, easy to read and understand. Again, that’s the perfection. And perfection comes with a price.
The fact is, we need to consider the time at disposal (deadline and time-to-market), the budget allocated, people involved (teams & organisation), and added to that the current state of codebase. So things get more and more complex in the timeline. We would add more features, thus make a lot of changes to the codebase. The complexity keeps growing. It just make things more complicated. The effort to put to achieved one thing that takes one day 2 years ago now requires 1 week to achieve. That would still happen even if the team is steady and the code is clean. Imagine now there is turnover, the market is more challenging (need of faster delivery), and we have cumulated accidental technical debt, while initiating technical migration (outdated technology), how do we prioritise the quality (again not only code)?
Then, when we have to deal with a poor quality codebase, while trying to delivery new features or functionalities to our customers, we are in a quite troublesome situation, sometime desperate, because we have no choice but to make a decision (implying to accept adding more technical debt) that allows us to ship an increment of the software. Depending on the state and size of the project, the poor quality may slow down the team 1.5x, x2, x3, x5 or x8, and it won’t be obvious to know which coefficient apply to our project.
What are the impacts and risks ?
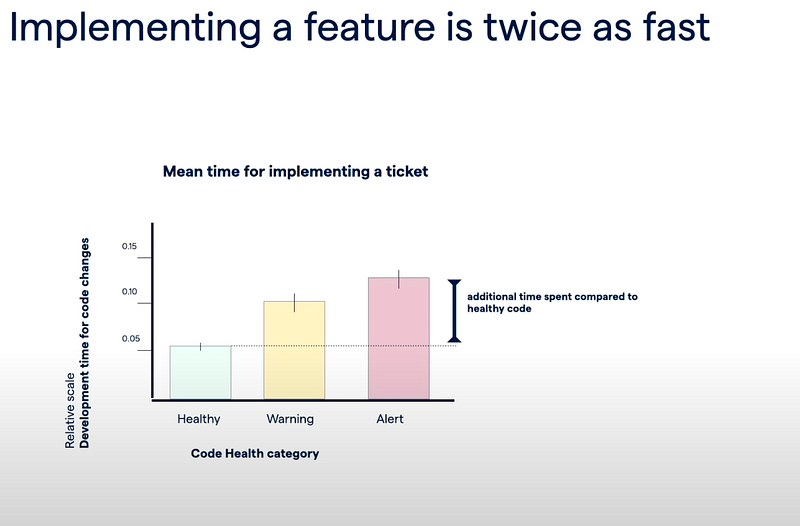
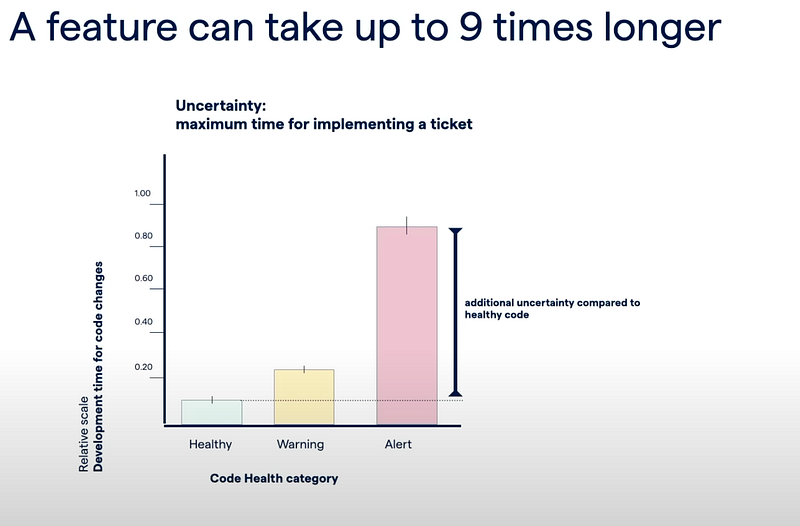
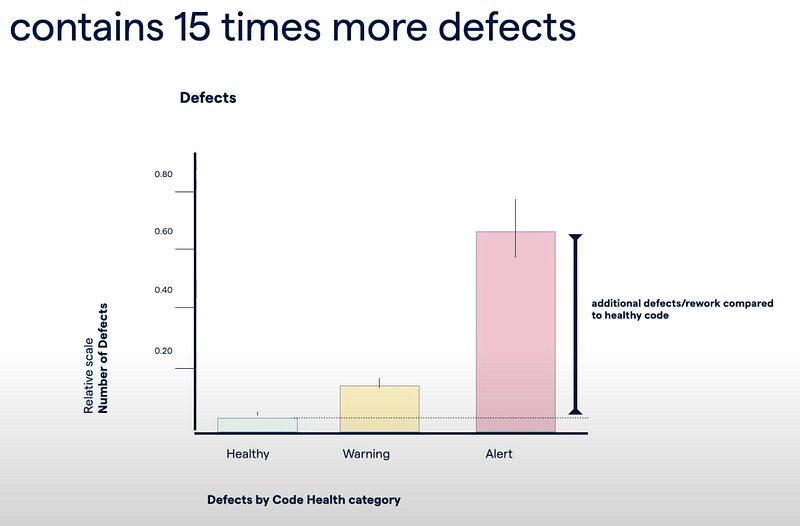
Technical debt is translated into more complexity, harder to read or understand, harder to add new feature, harder to maintain. As a result, implementing a new feature requires just more time. It may takes twice the time compared to healthy code. But added with operational complication when working with several teams, the feature may take up to 9 times to be delivered with the risks of containing up to 15 times more defects [@adamTornhill].
We, as developers, often said “we don’t have time to refactor”, because we have business pressure with deadlines. At the end, the result is adding more debt. Some debts have low interests because we don’t bump into them often. At the opposite, if the part of the code is very active, the debt is likely having a very high interest rate. For the business, it means longer time-to-market (TTM), more budget for the same feature or paying more people to get the expected features. It’s not for the best interests of the company to be forced to introduce new technical debt.
That being said, the quality of the code matters! So we need to care about it.
— — —
Now that we have understood the pain points and moreover the reason why we must have a QG, let’s see what it consists of.
— — —
What is a quality gate ?
The QG is a process, here an automated gate, to control a state of the codebase and its package being built to make sure the piece of software we are about to ship is compliant with some standards. Then the standards are defined according to the company context and constraints.
To connect the dots, this gate aims to support the Enterprise architecture principles, such as Security, Quality, Legal & Regulatory, Data Privacy Compliances, and software architecture principles, such as flexibility, maintainability, robustness, availability, scalability and resiliency.
The first QG we are putting in place is to do several checks on the CI pipeline, so that it would automatically validate a the codebase of a git branch, mostly PRs (Pull Requests), by analysing the code and the packaged artefact. As a pre-requisite, we must define the exit conditions of the gate. And the schema below shows an example, which checks whether the code is linted, the code coverage is above a threshold (ex. 80%), there are less than a certain number of security issues (static scan), good functional coverage, and no degrading performance.
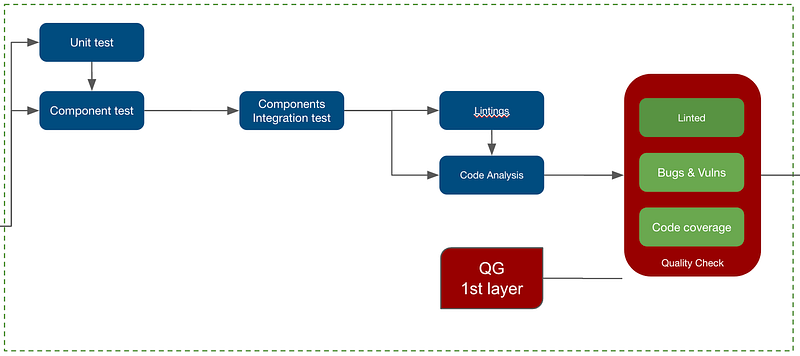
The schema above shows one part of the CI pipeline. At first sight, we see there are severals tests (unit, component, components integration), followed by a code analysis (linting and static code analysis), and at last the quality check to verify all exit conditions. We will focus only on the quality check block as that’s the quality pass.
In terms of checks, we ensure that :
- Code is properly linted (well formatted and compliant to coding standards)
- All automated tests (unit, components and components integration) are passed.
- Code coverage is above the threshold (usually 80%)
- Code Smell is low (close to zero)
- Reliability & Vulnerability (usually rating A, or zero issues)
The five aspects compose the code health. If it is good, we can promote to next stage, that means the PR is potentially mergeable.
Automation relies on a toolchain
As explained earlier, to measure the code quality, we would take into account five main aspects. Some tools are out there to bring their best to provide a meaningful and accurate scoring on a codebase, per technology stack (java, .net, javascript/typescript, python…). In my previous experiences, I see most of the time Sonar as code scanning tool, combined with gitlab/github as git server, gitlab-ci/github action/jenkins for continuous integration (CI), npm/maven/gradle as build tool, nexus iq/x-ray/fortify for security scan. I won’t provide details on all of them. But it worths mention that on project codebase, we need a code version control system, a build server to run test/build/analysis tasks, build tools, reporting tool. Put together with their specific role, they all are part of the CI toolchain.
Nowadays, a software development project requires a CI workflow (a.k.a pipeline) in addition to the toolchain. The workflow is a concrete automation of the software factory process. Most recent practices are in favour of an embedded CI workflow directly in the codebase, github action and gitlab-ci are good examples.
In terms of testing, building, packaging and publishing artefacts, the toolchain is there to automate everything. We can see that as a software factory : code in, artefact out. That artefact, usually versioned, is deployable to production.
If we want to ensure the artefact is of good quality, that is the best place to control, instead of verifying everything late on staging or production. Because it is automated thus efficient. And the earlier we can prevent any quality issue, the better it is. In a small organisation like a startup, we may try to detect issues directly on the developers’ workstations, but in a more industrialised software factory, in it best do the check on the CI.
The quality gate on the CI makes totally sense to support the continuous quality.
What more can we do ?
In my previous experience, almost all projects left me a lot to be desired. Technical debt was inevitable. It’s just a matter of interest rate. Here, about 30% of projects are poor, while the rest are having coverage higher than 70%. Shall we agree we can’t just look only at code coverage? Sure enough. As the article main concern is about code coverage, I won’t divert. We can work out on improve the code base.
If we want to go further, we may start a few more initiatives : better testing (component and unit function tests), clean code, hexagonal architecture (or functional core & imperative shell), pivot to BDD/TDD, better logging for easy monitoring and observability and secure code (by design).
Clean as you code
Some some situation, the technical debt is already present without any control or visibility. And we wish to set up a quality gate to rail guard the quality track. Then we bump into a big problem : we can just block everything. Setting the code coverage at 80% one-shot will be a show blocker. We need to approach the problem with goal and strategy.
The pragmatic way to go is tackling things in the flow of actions. we set our focus on impact and return on investment. That means targeting the part of the system that keeps moving : code changes. Not the rest of code that does not change. Bugs, if any, would be fixed. And fixes result in code change.
So we should enforce the quality of code changes when teams push their code, as suggested by the Sonar User Guide (clean as you code). Then progressively pull the string to where we want to reach, by raising the bar slowly but surely.
— — —
Take away
Not everything is great, and not everything is bad. Continuous improvement is the way to go. There is always room to get better.
I hope you appreciate reading this article. At last below you may find some keynotes as take away.
- Change and adoption (thus change management) is the hardest part
- Adoption start with an agreement, contributions from people is synonym of agreement and commitment
- Blocking the delivery is a risk for both business and adoption, else only frustration and complains we get
- Communication is crucial, that help teams to adopt changes and anticipate things to come and to do
- Progressive rollout and planning, being empathic toward teams : they have their own concerns everyday, and do their best to make things better.
- Clean as you code, improvement would be more fluid, with no show blocker, and adoption would be easier. Otherwise, it’s counter-productive.
Many thanks!
Reference
Glossary
- CI & CD : Continuous Integration & Continuous Delivery
- PR : Pull Request
- QG : Quality Gate
- TDD : Test-Driven-Development
- BDD : Behaviour-Driven-Development
- TTM : Time-to-market
- UI/UX : User Interface / User Experience



