
Anthropic’s Claude 3 Beats GPT-4 Across Main Metrics
The race is on, and it should not be over anytime soon.
Every week, even every day, new breakthroughs are happening in the AI space, and here is a new one.
Anthropic just released (On February 4th, 2024), its Claude 3 series, a new family of models: Opus, Sonnet, and Haiku.
The models are available on test, on Claude.ai but also via API.
So what is new about this new release, on how does it outperform OpenAI ChatGPT4?
Performance
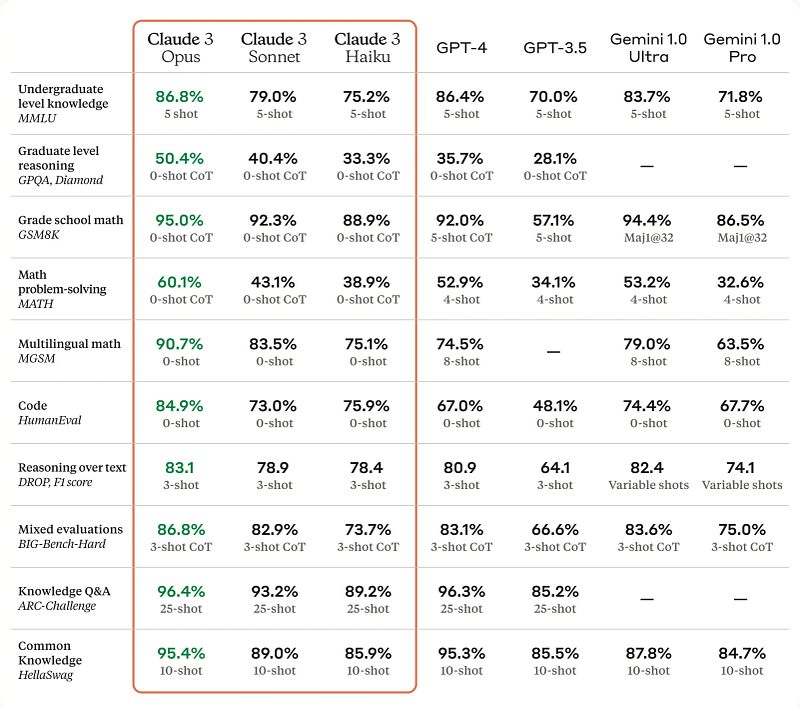
The benchmark made with Claude 3 (Opus) shows better accuracy against GPT4 on Undergraduate level knowledge (86,8% vs 86,4%), Graduate level reasoning (50,4% vs 35,7%), Grade school math (95% vs 92%), Math problem solving (60,1% vs 52,9%), Multilingual Math (90,7% vs 74,5%), Code (84,9% vs 67%), Reasoning over text (83,1% vs 80,9%) and so on.
It also beats Gemini 1.0 Ultra on the same benchmarks.
Here is the full benchmark matrix shared by Anthropic.
Capabilities
The Claude 3 models offer multimodal capabilities, enabling them to understand both text and visual inputs. This feature is crucial for analyzing and processing complex, unstructured information in a variety of formats. It allows for a more comprehensive understanding of data, regardless of its presentation.
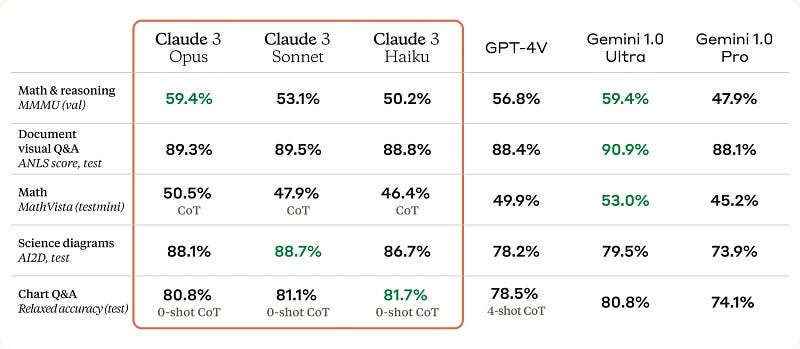
Claude 3 models feature advanced vision capabilities, equal to leading AI, for processing diverse visual formats like photos and diagrams. This enhancement is especially beneficial for using data in formats like PDFs and slides.
Here is the benchmark provided by Anthropic:
Extended Context Window
I think this is a major advancement in LLMs. Where GPT4 is still on relatively small context windows (32k tokens available to public. 128k tokens announced), Gemini 1.5 on other hand went up to 1M token capabilities (and announced up to 10M tokens). Claude 3, comes with standard 200k tokens window (that is almost 800 pages) and 1M tokens announced for enterprise / specific needs usage.
The Needle In A Haystack Test
Claude 3 models can remember and use a lot of information very well. Even with context windows with 200k tokens it passes well the Needle In A Haystack Test. Indeed, these models are great at finding specific details in a huge amount of data. They can almost always find the right information, and sometimes they even notice when something doesn’t quite fit right in the data they’re given.
To be noted that Gemini 1.5 also showed great results for such tests as well.
Pricing
Claude Opus is priced at $15 per million tokens, which also shows that the price per 1k token is continuing to drastically decrease, and that this trend is continuing.
Responsible Design and AI Safety
Even if it is difficult to assess this at early stage, Anthropic announces making Claude 3 models neutral and trustworthy, addressing AI biases and risks like misinformation and privacy issues with its “Constitutional AI” framework.
Despite progress in reducing biases, eliminating them completely is hard. Claude 3 is safer and less biased than earlier models, but still at AI Safety Level 2, with ongoing efforts to monitor and enhance safety and neutrality.
Anthropic shared that they validated their model against US Executive Order on Safe, Secure, and Trustworthy Artificial Intelligence, however there was no mention of the EU AI Act.
Closing Thoughts
We continue to move towards Faster, Safer, Smarter and Cheaper LLMs. Claude 3 is no exception. It shows great benchmark results compared to GPT4, showing better accuracy overally, bigger context windows and a very competitive pricing. It would be interesting however to benchmark against Gemini 1.5 which might beat Claude 3 on some lines.
If you found this article useful, please clap and share your thoughts.
I regularly write about AI and Data, feel free to follow me :
- On Medium : https://medium.com/@AhmedF
- On LinkedIn : https://www.linkedin.com/in/ahmedfessi/
- On Twitter : https://twitter.com/ahmedfessi
- On Udemy (my courses are also available on Udemy for Business): https://www.udemy.com/user/ahmedfessi/





