

An Overview of Pathways Autoregressive Text-to-Image Model
Exploring Google AI’s new big thing in image generation.
Some days ago, I wrote an article about DALL-E 2: an enhanced AI capable of producing realistic images in which you type whatever you want, creating it for you.
Image generators can be very helpful in converting text prompts into high-quality images.
Of course, human brains can create complex scenarios based on verbal or written descriptions. Replicating this to create visuals based on such descriptions can open up creative possibilities in various fields, including the arts, design, and multimedia content development.
Observing how DALL-E 2 works lead to the conclusion that there is a very deep scientific research process at the heart of DALL-E 2 to take artificial intelligence one step further.
The system is built on a foundation of two fundamental assumptions that lead to the ability to generate images.
To create photos from the text, the AI must first understand how words and images relate to one another; then, after training, the system must be able to generate the images.
To do so, OpenAI employs a technique known as Diffusion, which converts text into data before searching for similarities with what has been learned through Clip.
Recent research in text-to-image creation, such as DALL-E and CogView, has made significant progress in producing high-fidelity images. It has also demonstrated generalization capabilities to previously unexplored pairings of objects and concepts.
Both take a language modeling approach to the problem, converting textual descriptions into visual words. They use current sequence-to-sequence structures like Transformers to understand the relationship between language inputs and graphical outputs.
Visual tokenization effectively combines the perspectives of text and images, allowing them to be handled as discrete token sequences and thus susceptible to sequence-to-sequence models.
DALL-E and CogView, like GPT-3, learned from a large collection of potentially noisy text-image pairings using decoder-only language models. Make-A-Scene expands on this two-stage modeling method to support text and scene-guided image production.
Significant previous work has been on scaling large language models and developments in discretizing images and audio. Instead of discrete picture tokens, these models employ diffusion models that generate images directly.
Google Imagen, an image AI that uses a similar architecture (Diffusion) to OpenAI’s DALL-E 2 to generate images but uses a large AI language model for input — can create better images from text descriptions due to its higher level of language understanding — was introduced earlier this year.

Enter Google’s Parti
Google is already working on another text-to-image generator like Imagen, which aims for more advanced photorealism employing a different family of generative models.
The new model, called Parti, which stands for Pathways Autoregressive Text-to-Image, is a new AI tool that renders hyperrealistic images from short textual inputs using an encoder-decoder that can scale up to 20 billion parameters.
Parti, like DALL-E and Imagen, generates high-quality images from text descriptions, such as photorealistic images, paintings, sketches, and more. According to the researchers, scaling autoregressive models with a ViT-VQGAN image tokenizer is an excellent technique for improving text-to-image creation.
Parti’s method begins by converting a collection of images into a sequence of code entries, similar to puzzle pieces. After translating a given text prompt into these code entries, a new image is created.
This method leverages existing research and infrastructure for large language models, such as PaLM, and is critical for dealing with long, complex text prompts and producing high-quality images.
Parti and Imagen complement each other in their exploration of two distinct families of generative models — autoregressive and Diffusion, respectively — opening up exciting possibilities for combining these two powerful models.
Parti employs an autoregressive model to convert text to an image. In contrast, Imagen uses Diffusion to convert a pattern of random dots into images.
Parti begins by converting an image collection into a code sequence that can be compared to puzzle pieces. The user’s text prompt is then translated using these code sequences, creating a new image.
This is important for the approach because it aids in dealing with long and complex prompts. It also aids in the creation of high-quality images.
These models incorporate and graphically represent global information effectively.
Parti is a sequence-to-sequence model based on the Transformer, a critical architecture for many applications, including machine translation, voice recognition, conversational modeling, picture captioning, and many others. Parti predicts discrete picture tokens using text tokens as input to an encoder and an autoregressive decoder.
The image tokens are created with the Transformer-based ViT-VQGAN image tokenizer, which produces higher-fidelity reconstructed outputs while requiring less code.
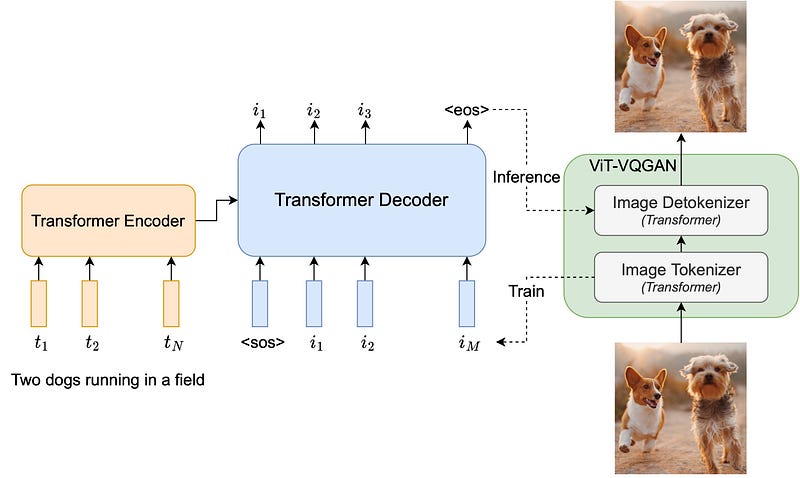
A close look at Parti’s architecture
With a relatively simple architecture, Parti can produce photorealistic images that rival the quality of larger models such as DALL-E 2 or Imagen.
It employs a two-stage model similar to DALL-E 2 or Imagen. Parti’s core architecture is built around an image tokenizer and an autoregressive model.
All of the components are built around standard transformer architectures. Parti, in particular, processes text inputs using an encoder-decoder model and predicts discrete image questions autoregressively.
After that, the predictions are processed by a ViT-VQGAN image tokenizer, which produces photorealistic images.
Nonetheless, despite the simplicity of its architecture, Parti is far from small. One characteristic of transformers is their ability to scale.
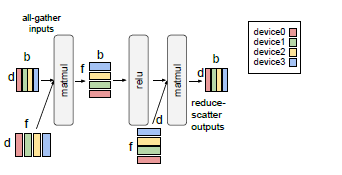
Google used model and data parallelism techniques to scale Parti from 350M to 20B parameters for both training and inference, using a combination of GSPMD on TPU v4 hardware.
The diagram below depicts the model parallelism technique, which divides each layer into four sub-layers distributed across different devices.
The improvement in output quality is visible across the different versions of Parti, as shown below.

When it comes to modeling, size matters!
Parti generates all images with a resolution of 256 x 256 pixels and then uses an upscaler to bring them to 1024 x 1024 pixels. It demonstrates that more extensive training leads to better results with more parameters.
Simply put, the AI model scales extremely well. It can also precisely convert particularly long and complex text inputs into images, indicating a deeper understanding of the relationship between language and motifs.
The largest model, with 20 billion parameters, generates the most error-free image corresponding to the extensive text input. The model excels particularly at abstract prompts requiring world knowledge, specific perspectives, or writing and symbol rendering.
Managing the Risks of hyperrealistic image generation.
Text-to-image models present numerous opportunities and risks, with potential consequences for bias and safety, visual communication, disinformation, creativity, and art, a problem shared by Imagen and DALL-E 2.
Because models like Parti are trained on a specific type of dataset that contains biases about people from various backgrounds, jobs, and so on, such models, including Parti, can produce stereotypical representations of people such as lawyers, flight attendants, homemakers, and so on, as well as reflect Western biases for events such as weddings.
This poses particular challenges for people whose backgrounds and interests are not well represented in the data and the model, particularly when such models are applied to uses such as visual communication and assisting low-literacy social groups.
Models that generate photorealistic outputs, particularly people, may increase the risks and concerns associated with creating deepfakes. This poses risks in terms of the spread of visually oriented misinformation and individuals and entities whose likenesses are included or referenced.
Google has chosen not to release any of Parti’s models, data, or codes for security reasons until additional safeguards are in place. To prevent credit theft, all images generated by the generator are watermarked with the name Parti in the bottom right corner.
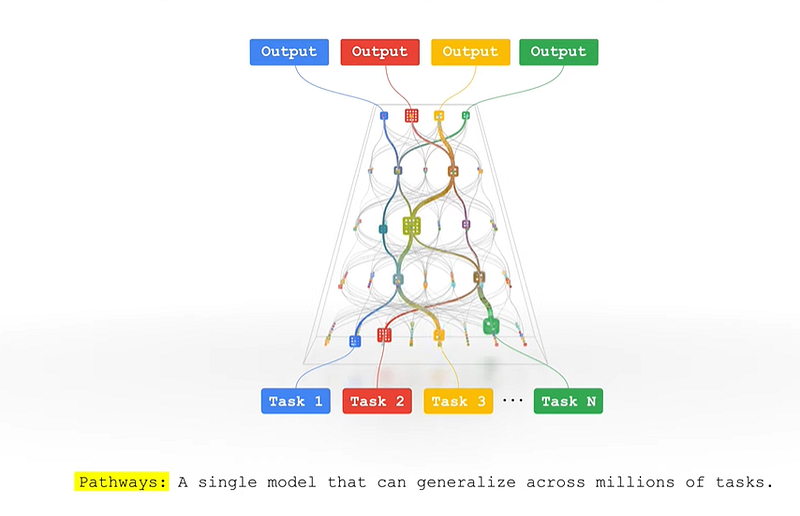
What is in a (model) name?
The name is also intriguing: The P in Parti stands for Pathways, Google’s next-generation AI architecture, which was first unveiled in late 2021 by Google’s AI chief Jeff Dean.
Pathways aim to create an intelligent AI multipurpose system that can “generalize across millions of tasks” one day.
The fact that Parti has Pathway in its name suggests that it will play the role of image generation in this future architecture. Combining the Parti and Imagen architectures is also worth a shot.
In short, Parti has the potential to be the next big thing in image generation and beyond.
Conclusion
Overall, Google’s Parti appears to be very promising. Parti focuses on modernizing more traditional autoregressive text-to-image architectures, whereas Imagen uses modern techniques such as Diffusion.
It’s only been a few years since AI image generators became a thing, but the quality of the results has already improved noticeably.
Text-to-image models give people many new ways to create unique and aesthetically pleasing images, essentially acting as a paintbrush to boost human creativity and productivity, and I believe that one day, text-to-image AI tools will be able to create images indistinguishable from real life.
The possibilities for this tool are limitless, and we can only speculate on what the future holds for this incredible technology.
Other Articles you may want to read.
- These 9 Research Papers are changing how I see Artificial Intelligence this year.
- The most impressive Youtube Channels for you to Learn AI, Machine Learning, and Data Science.
- These are some of the best Youtube channels where you can learn PowerBI and Data Analytics for free.
- What is the MIT MicroMasters Program?
- 5 companies that are revolutionizing recruiting using Artificial Intelligence.
- 5 amazing books about AI that you must read.
- The Best MIT Online Resources for You to Learn AI and Machine Learning for Free.
Sources, links, and references
- DALL-E 2: When AI transforms words into images… https://jairribeiro.medium.com/dall-e-2-when-ai-transforms-words-into-images-3de21f4ba9fa
- Google Research — Parti …. https://parti.research.google/
- Google AI Researchers Propose the Pathways Autoregressive Text-to-Image …. https://www.marktechpost.com/2022/06/30/google-ai-researchers-propose-the-pathways-autoregressive-text-to-image-parti-model-which-generates-high-fidelity-photorealistic-images-and-supports-content-rich-synthesis/
- Google is working on another text-to-image generator, and it is pretty cool … https://www.digitalinformationworld.com/2022/06/google-is-working-on-another-text-to.html
- Parti is Google’s other text-to-image generator [Gallery] — 9to5Google. https://9to5google.com/2022/06/22/google-ai-parti-generato/
- Deep Generative Adversarial Neural Networks for Realistic … — arXiv. https://arxiv.org/pdf/1708.00129.pdf
- OpenAI
- Elon Musk
- Sam Altman
- DALL-E
- DALL-E 2
- CogView
- ViT-VQGAN
- Google’s Imagen
- CLIP — Contrastive Learning-Image Pre-training
- Parti — Pathways Autoregressive Text-to-Image
- Pathways, Google’s next-generation AI architecture
- Diffusion Models
- Fake news
- Biases in AI
Would you like to support me?
To get access to unlimited stories, you can also consider signing up to become a Medium member for just $5. In addition, if you sign up using my link, I’ll receive a small commission (at no extra cost to you).