
AI enables designing new proteins from scratch
How artificial intelligence can allow producing unseen proteins

Since the publication of AlphaFold2, scientists have speculated what the fallout might be from a model that predicts protein structure. Now a new study shows how to use a language model to generate functional enzymes that also display some functional activity.
Alphafold2 showed how using DeepLearning made it possible to successfully predict the structure of a protein from its sequence (here’s for example a tutorial where you can run it yourself). Although this was considered an outstanding achievement, the model is not without limitations.
Meanwhile, DeepMind is not the only company that has shown interest in the possibility of predicting protein structure. Both Meta (former Facebook) and SalesForce (American cloud-computing company) have developed their own models, using a classical language model (transformer) modified for the occasion. The result is that these models are slightly less accurate than AlphaFold but are much faster (and also less computationally expensive).
The authors of SalesForce present in their latest work ProGen, a model that was trained on 280 million proteins from over 19,000 families. In addition, this model can be fine-tuned on a specific family and conditioned to generate new sequences. In this study, the authors generated new lysozyme-like proteins that showed indeed catalytic activity just like natural lysozyme. The key thing is that these are not simply variations of natural sequences but rather totally redesigned; in fact, these new enzymes have sequence similarity as low as 31 %.

You can find the original article here:
Traditional protein engineering methods are usually conducted using iterative processes of mutagenesis and selection. During these laborious steps, an attempt is made to select proteins for particular properties of interest. There are also other methods of drawing models in silico, using biophysical properties or from evolutionary studies of the sequence. These methods, however, are often laborious and not always successful.
ProGen is a language model (a transformer) that is optimized to predict the probability of a certain amino acid given the previous one in the sequence. In other words, the model takes as an input a protein sequence and predicts the next amino acid in the sequence (let’s say XXYZ, given the model X it learns to predict X, then with XX it learns to predict Y, and so on). This approach is called unsupervised learning and allows the model to understand the patterns and properties of the data.
As can be seen during training, no structural information or other assumptions about the evolution of a protein family are provided. At the same time, however, the model is capable, through unsupervised learning, of understanding some of the structural and functional properties of a protein that are hidden in the sequence.
Once trained, the model can be used to generate sequences:
After training, Progen can be prompted to generate full-length protein sequences for any protein family from scratch, with a varying degree of similarity to natural proteins. In the common case where some sequence data from a protein family is available, we can use the technique of fine tuning pretrained language modelswith family-specific sequences to further improve the ability of Progen
Meanwhile, ProGen is a much smaller model than AlphaFold2 (only 1.2 billion parameters) and second, it can be conditioned to generate particular types of sequences (‘tags’). These tags can represent concepts such as protein family, biological process, or molecular function.
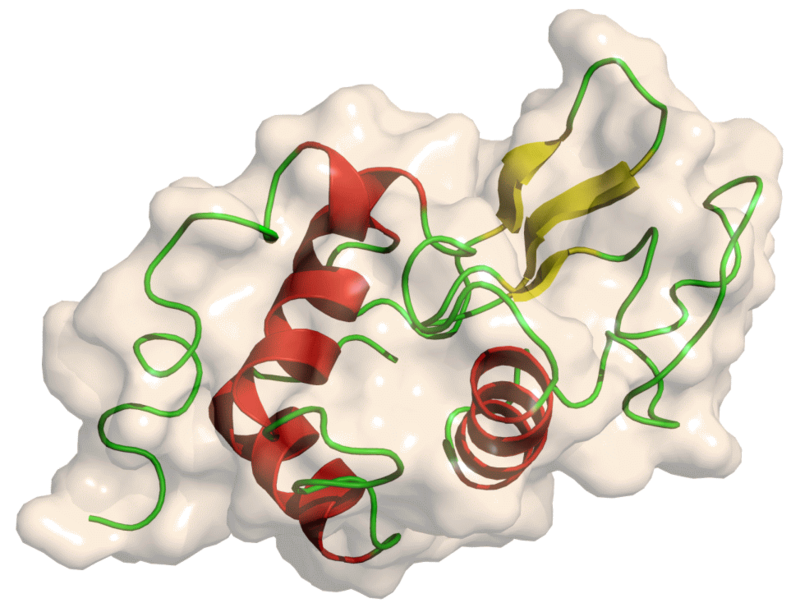
The authors decided to test it on five lysozyme families. The ProGen model was trained with all the known protein sequences, then they selected 55,000 sequences for fine-tuning. After that, they generated one million sequences with the model:
Our artificial lysozymes span the sequence landscape of natural lysozymes across five families that contain diverse protein folds, active site architectures and enzymatic mechanisms. As our model can generate full-length artificial sequences within milliseconds, a large database can be created to expand the plausible sequence diversity beyond natural libraries
As the authors note the model captured in these sequences evolutionary conservation patterns without the need to indicate this information to the model.
They subsequently selected one hundred sequences (using divergence from natural sequences as a criterion) to express as proteins and to do functional tests. As the authors noted, “Artificial proteins included specific amino acids and pairwise interactions never before observed in lysozyme family-specific alignments.” An interesting result that shows how AI can generate sequences different from those observed. The question remains: are these proteins functional?
The authors synthesized these candidate proteins in the laboratory, and were able to obtain a quality sample in 72 percent of cases -a quite a high success rate! They also tested these proteins using quench release of fluorescein-labeled Micrococcus lysodeikticus cell wall, an assay to measure lysozyme activity. The rather impressive result:
Among our artificial proteins, 73% (66/90) were functional and exhibited high levels of functionality across families. The representative natural proteins exhibited similar levels of functionality with 59% (53/90) of total proteins considered functional.
Translated into simple words, the proteins that were generated by AI show comparable activity to natural lysozymes. In addition, the authors note that there are particular outliers:
These highly active outliers demonstrate the potential for our model to generate sequences that may rival natural proteins that have been highly optimized through evolutionary pressures.
Finally, the authors tested the model with other families and conducted ablation studies. The latter showed that both initial training and fine-tuning are not necessary to obtain an optimal result.
Training with the universal sequence dataset containing many protein families enables ProGen to learn a generic and transferable sequence representation that encodes intrinsic biological properties. Fine tuning on the protein family of interest steers this representation to improve generation quality in the local sequence neighborhood.
This and similar tools are paving the way to a new revolution based on the possibility of creating new proteins. In fact, this permits the generation of new protein sequences in a millisecond. In the future, we can adapt this model to many other kinds of protein families. Moreover, the authors used tags to fine-tune and generate protein (in this case lysozyme) but this tag can be a specific function (a specific reaction, substrate, and so on). For example, we could in the near future see new enzymes to digest pollutants, fight parasites and bacteria, act as vaccines, or be useful as drugs in clinical applications.
If you have found this interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. If you want to support me, please clap and share, or you can also sign up here (I’ll earn a small commission at no extra cost to you).
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
or you may be interested in one of my recent articles:
— Edited by Luciano Abriata (LucianoSphere)






{kind=link}