
A Visual Journey in What Vision-Transformers See
How some of the largest models see the world

Visualizing CNN's allowed us to learn more about how these models work. Now that Vision Transformers are taking the stage, a new article explains how we can see what these broad models see the world as.
Visualize the vision transformers

Since convolution neural networks (CNN) have emerged as a winning model in computer vision, different research groups have focused on understanding what these models learn.
On the one hand, neural networks have emerged in several fields (from language analysis to computer vision) but have been considered “black boxes.” In contrast to many other algorithms, they are much more difficult to interpret. In fact, the more capable the models become (growth in the number of parameters), the more difficult it becomes to be able to understand what is going on inside.
Therefore, several methods have been developed to visualize what a convolutional neural network learns. Some of the most used:
- Visualize the filters (or visualize the weights).
- Visualize layer activation
- To retrieve an image that maximally activates a neuron
- Embedding the feature vectors with t-SNE.
- GradCAM, saliency maps.
In 2016, transformers appeared on the scene. These wide models based on self-attention have been shown to achieve much superior performance in NLP (machine translation, language classification, and so on). Soon, they became the standard for NLP, and with the introduction of vision transformers, they were also applied to computer vision.
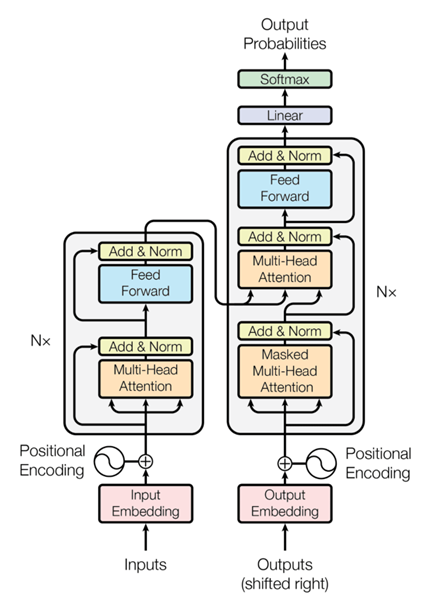
Therefore different researchers have tried to visualize what vision transformers (ViTs) learn. ViTs have proven to be much more difficult to analyze, and so far, the methods used have shown limitations. Understanding the inner workings of these models could be helpful in explaining their success and potential corner cases.
Previous work had focused on observing the activation of keys, queries, and values from the self-attention layer, but the result was unsuccessful.

A paper has recently been published by researchers at New York University and the University of Maryland that provides a better understanding of what happens inside the model (whether they are vision transformers or models such as CLIP).
In the article, the researchers summarize their contribution:
- While standard methods lead to uninterpretable results (especially when applied to keys, queries, and values), it is possible to obtain informative visualizations by applying the same techniques to the next feed-forward layer of the same transformer block (and they demonstrated this using different models: ViTs, DeiT, CoaT, ConViT, PiT, Swin, and Twin transformers).
- Patch-wise image activation patterns for ViT features behave like saliency maps demonstrating that the model preserves positional relationships between patches (and learns this during training).
- CNN's and ViTs construct a complex and progressive representation (in CNNs, the first layers represent edges and textures, while later layers learn more complex patterns, and the authors show that the same happens in ViTs). ViTs, in contrast to CNN's are better able to use background information.
- The authors also applied their method to models using language supervision (such as CLIP) and showed that features could be extracted from these models that are associable with caption text (such as prepositions, adjectives, and conceptual categories).
The authors compared ViTs to convolutional networks and noted that the representation increases in complexity along the pattern (earlier layers learn simpler structures while more sophisticated patterns are learned by more advanced layers). In practice, both CNN and ViTs share what is called progressive specialization.


There are also differences. The authors investigated the reliance of ViTs and CNNs on background and foreground image features (using bounding boxes on ImageNet). ViTs are able to detect background information present in the image (in the image, for example, grass and snow). In addition, by masking the background or foreground in the image the researchers showed that ViTs not only use the background information better but are also less affected by its removal.

We find it surprising that even though every patch can influence the representation of every other patch, these representations remain local, even for individual channels in deep layers in the network. While a similar finding for CNNs, whose neurons may have a limited receptive field, would be unsurprising, even neurons in the first layer of a ViT have a complete receptive field. In other words, ViTs learn to preserve spatial information, despite lacking the inductive bias of CNNs. -source: original article
In other words, during training, the model learns how to preserve spatial information. In addition, the last layer instead has a uniform activation pattern and learns how to classify the image (according to the authors, the last layer has the function of globalizing information).
Based on the preservation of spatial information in patches, we hypothesize that the CLS token plays a relatively minor role throughout the network and is not used for globalization until the last layer.

In recent years, vision transformer models have been trained with language supervision and contrastive learning techniques. One example of all is CLIP. Because these models are increasingly used and increasingly competitive, the authors also analyzed CLIP.

The model shows that there are features related to conjectures, such as “before and after” or “from above.” In other words, there are features that represent conceptual categories and are clearly discernible:
The corresponding seven highly activating images from the dataset include other distinct objects such as bloody weapons, zombies, and skeletons. From a strictly visual point of view, these classes have very dissimilar attributes, indicating this feature might be responsible for detecting components of an image relating broadly to morbidity.

Conclusions
To understand, seeing is always better. In recent years there has been an increasing emphasis on the need for the interpretability of models. While there are many worked methods on CNNs, being able to visualize the features of ViTs was not possible.
The authors not only identified a method to be able to do this (they showed that one had to use the feed-forward layer and not the self-attention layer) but also analyzed the properties of these features. They showed how the model is capable of learning spatial relationships during training and how, on the other hand, the last layer does not participate in this spatial representation.
Furthermore, although ViTs are similar to convolutional networks, part of their success for the authors is derived from how they make better use of background-related information. They also show that when ViTs are trained with d with language model supervision, they learn more semantic and conceptual features rather than object-specific visual features.
if you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
Or feel free to check out some of my other articles on Medium:





