
A Single Template Each for Lambda Functions, Roles, and Policies
ACM.289 The quest for faster, compliant deployments
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
⚙️ Check out my series on Automating Cybersecurity Metrics | Code.
🔒 Related Stories: AWS Security | Lambda Security | IAM
💻 Free Content on Jobs in Cybersecurity | ✉️ Sign up for the Email List
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In the last post I wrote about leveraging containers for improved governance, security, and portability.
Next up I need to create a CloudFormation template for the Lambda function. Now, what I was hoping to do was slightly modify and reuse my existing Lambda function template that I created in a prior post. The idea is that could use one template for all my Lambda functions and just swap out the container. The concepts in this post align with the the way I use the principle of abstraction in cybersecurity.
The concept is related to my idea of Micro-Templates in CloudFormation.
Let’s take a look at how this might work for Lambda functions, roles, and role policies.
Directory Structure
First of all, looking at the hierarchy I was putting the Lambda function template into a folder specific to the function. If I want to reuse one template for all my Lambda functions that is not going to work. I’ll need to rearrange my directory structure.
Instead of:
/Function1/Lambda.yaml
/Function2/Lambda.yamlI need something like:
/App/stacks/cfn/Lambda.yaml
/App/stacks/deploy/App1/deploy.sh
/App/stacks/deploy/App2/deploy.shWhat if I have an application that needs AWS Batch, EC2, or Fargate? I might try to create generic templates for all of those and leverage those template in my deploy scripts, if I can.
/App/stacks/cfn/Batch.yaml
/App/stacks/cfn/EC2.yaml
/App/stacks/cfn/Fartgate.yaml
/App/stacks/cfn/Lambda.yaml
/App/stacks/deploy/App1/deploy.sh
/App/stacks/deploy/App2/deploy.shLet’s look at my prior template.
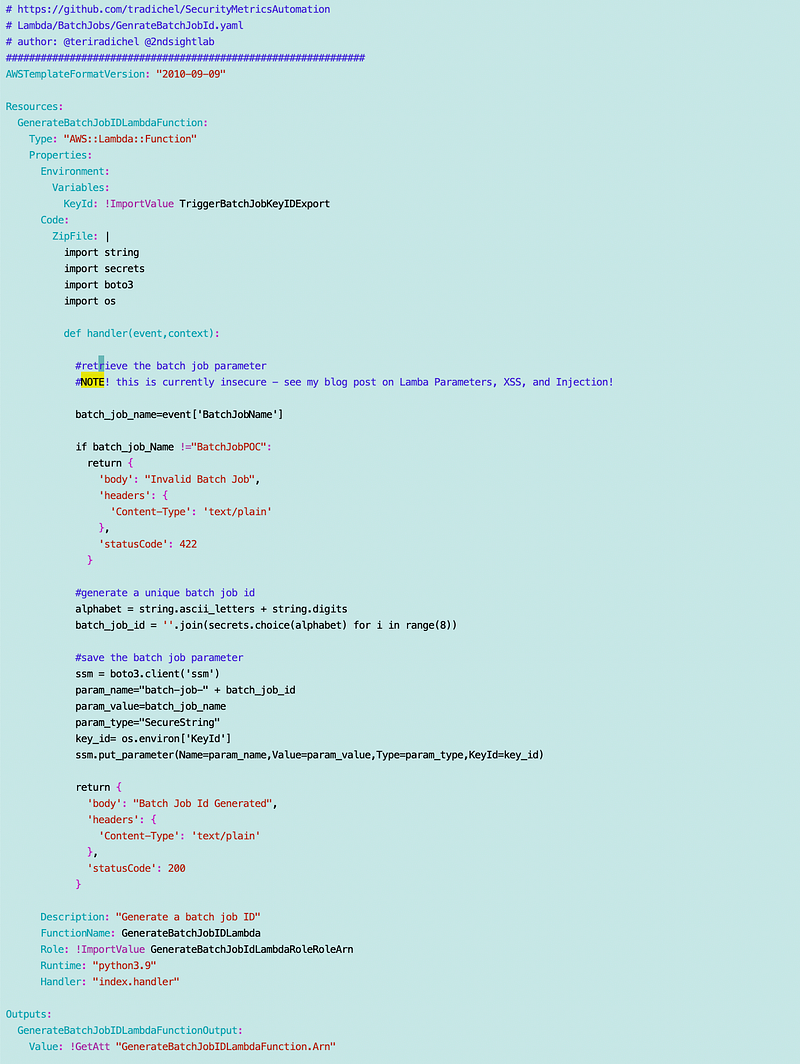
Code
As you can see the code is embedded into the template and would be hard to pass all that in. Putting the code in either a container or a zip file allows us to create a more generic template. We can give the zip file or container the same name as the function to make it clear that the two are related. In fact, then we only need to pass in a name to the function and use that name to pull the correct container.
Environment
I’ve been writing about this concept of environments. Perhaps a specific environment defines the repository from which to pull the container, the VPC to use for the function, log destination, and so on. We specify the environment in a parameter. We can use a map or reference the environment resource based on the output of a CloudFormation template, potentially.
To avoid any confusion, there’s an Environment property for Lambda functions that allows you to set environment variables within the Lambda function that the function can access when it runs. That’s not what I’m taking bout when I refer to environments.
I’m talking about the context in which the container runs. A function that might run in a Sandbox environment for testing purposes like we are doing now or a development, QA, staging, or prod environment. You might also have functions that run in a Security account or an account controlled by the IAM team or backup team. These different environments will have a set up consistent parameters, but the parameters will have different values in each “environment” such as a different VPC ID.
Role and Policy
Initially I created the role template for Lambda in the IAM repository, because the IAM team might define and manage the IAM role and trust policy for a Lambda function. That way some developer couldn’t come along and change the trust policy to grant access or some other principal access to assume the role intentionally or by mistake.
I had the idea that the developer would create the policy for the Lambda function role since the developer might have a better idea what permissions their application needs, within a permissions boundary — a concept I haven’t covered yet. But I started to think — could I create a generic Lambda role and policy that would work with many Lambda functions? That way I wouldn’t have to keep creating new policies and risk a malicious or inadvertent change to access unauthorized resources.
“How in the world can you create a standard role for Lambda functions? They are all so different.” That may be true but perhaps there are a certain type of functions that have similar needs in terms of the actions they carry out, but they are only allowed to access certain resources. How could I make that work so I could quickly deploy new Lambda functions?
Well, first of all, the role and policy name can match the Lambda function name. That makes our Lambda template pretty simple and generic.
The role and role name is easy. Unless we want to add a condition on the environment somehow the role should be pretty generic.
The hard part is the policy. The policy may need to access different resources depending on what the function is doing.
A generic Lambda policy for a process with steps
I started out this series writing about automating processes with batch jobs and how that can help cybersecurity. That’s kind of what we are doing now. We’re using a Lambda function instead of AWS Batch but really either one can run a batch job. They just have different properties that may cause you to opt for one or the other. Ideally we could leverage our container in both places. But for now we’re focused on Lambda.
I’ve worked on a lot of batch processes over the years. Lots and lots of batch jobs for back office processing at a bank, tax systems, sales systems, marketing, and e-commerce processing. Batch jobs often have a series of steps. After one step completes, it feeds into the next step. I also created a batch process for my penetration testing activities that do something similar.
Generally a process starts by retrieving data. Then it processes the data. Then the data gets stored somewhere.
The data could process data in a database. If the data is processed in a single database the process will generally run fastest by leaving the data in the database and processing it there. The process might retrieve data and push it to another database. To access the database(s) the process will often need to retrieve credentials first to access the database. There are are some other mechanisms for accessing cloud databases but many processes need to retrieve credentials to access a source system.
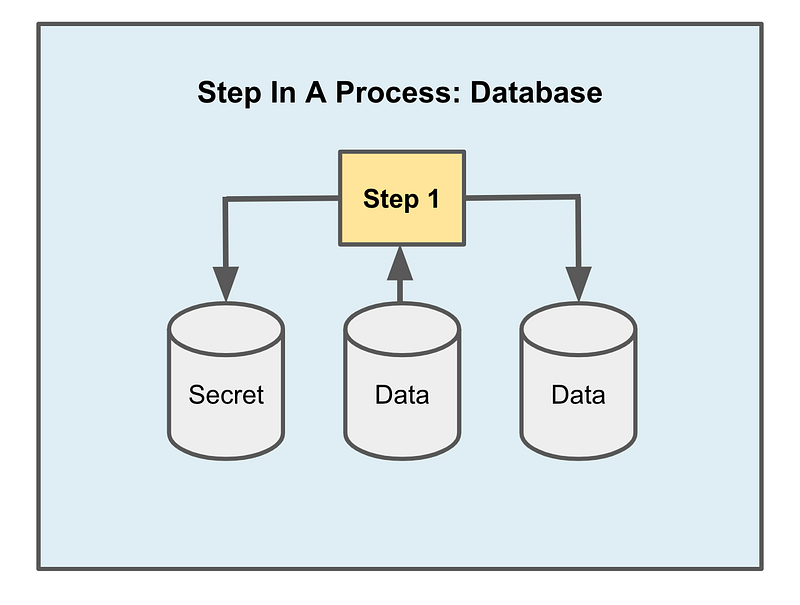
In the example I’m working on right now the source is a GitHub repository and the destination is AWS CodeCommit. If we need a password to access the GitHub repository, that could be stored in AWS Secrets manager. The role would need to grant access to check in code to AWS CodeCommit as the destination.
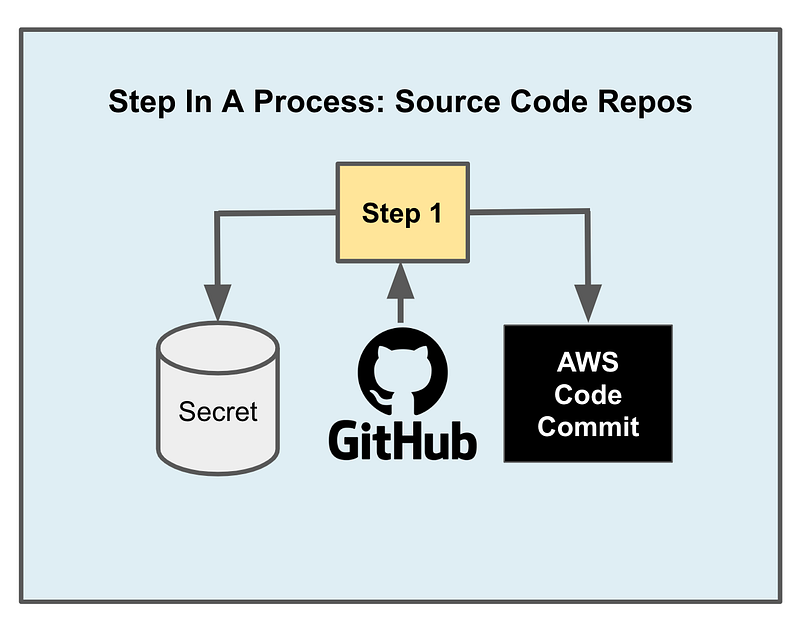
The source and the destination might be an S3 bucket or different source and destination S3 buckets. I have some processes like this. It could be that a file saved to an S3 bucket triggers a process. The process obtains the data in one bucket, processes it, and puts the results in the same or a separate bucket.
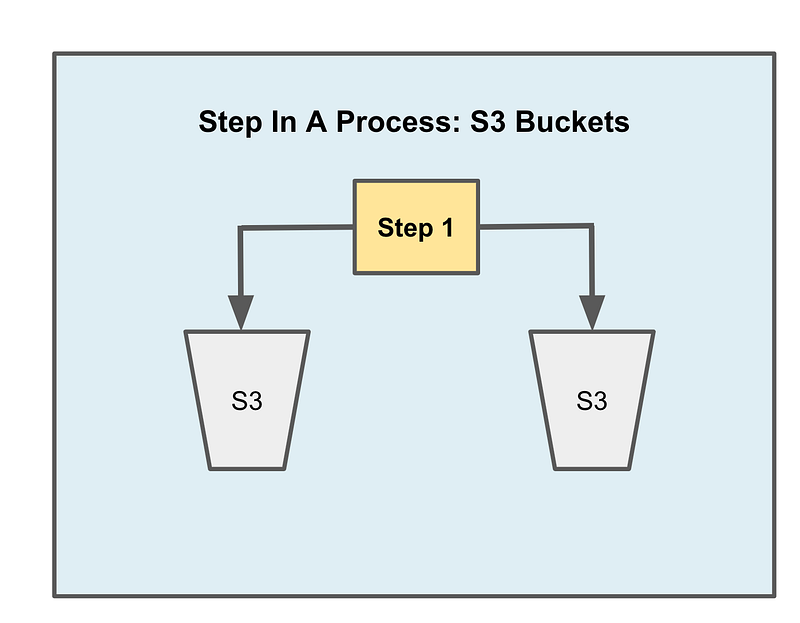
What if a process needs to pull from multiple sources? Perhaps in that case, the process should be broken into two separate steps. Does this work in all cases? I’m not sure yet. I’m still thinking this through.
What if we have are multiple steps in the process. We might have something like this:
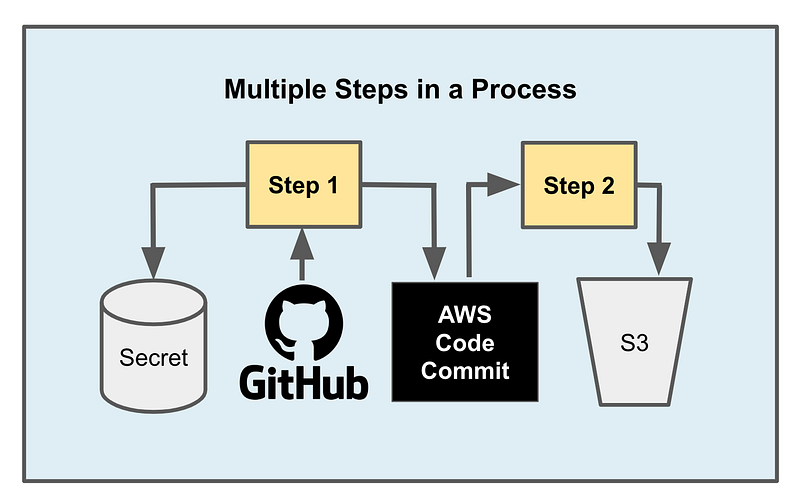
In general we might have the following for a process:
- A secret
- A data source
- A data destination
How could we create a generic policy given all these different sources and destinations?
Also, as a reminder, I am not using AWS Step Functions because currently the CloudFormation options for AWS Step Functions do not allow you to pass in a separate role for each step. Last time I checked there is one role for the entire process. I put in a request to AWS to fix that.
A Per-Process Secret
The first example scenario above is easy. We can create a secret with the same name as the process. Then we can have a parameter that can be set when deploying the policy that indicates whether the process requires a secret or not. If it does, add a statement to allow the process access the secret. We can also pass in a parameter for read, write or both. The policy template can be hard-coded to only allow a Lambda function to access a secret with the same name as the process.
A Per-Step Secret
If you take a closer look at the above process it has two steps. Only the first step needs a secret. The second step should not have access to the secret. What we really need is a per step secret. We can easily modify the template to allow a per-step secret for a step. The secret name matches the process name plus the step name. The policy only allows access to that hard coded secret and not others, so someone can’t pass in a parameter that gives them access to some unauthorized secret at the time of deployment.
Environment Sources
Some sources will be environmental sources. For example, we created an AWS CodeCommit repository for the Sandbox environment. I might end up with a separate repository for Dev, QA, and Production the way I do things. We could indicate whether the source is a CodeCommit repository and it would be in the current environment. It could be that our process is pushing the code to another environment repository. Maybe the source is always the current environment and the destination can be another environment. I’m not sure about that because it would be risky to allow any process to push to production. We’ll need to limit pushing from one environment to another somehow, perhaps with an SCP or by limiting who can run those types of deployment Lambda functions. I still need to think about that. But you get the idea.
Process Sources
It could be that there is an S3 bucket for process. each step in the process has it’s own folder.
S3://<processname>/step1
S3://<processname>/step2
S3://<processname>/step3One thing that would be easy to do is specify that a process only has access to write to its own bucket: s3://
It would also be easy to pass in the step we are deploying and our template could easily grant write access to the current process step: s3://
What is not so easy is granting read access to the prior process step by hard-coding it into the template so that we know for any process step, it only has access to the prior process step folder and nothing else. We can’t do math in a CloudFormation template by design. Passing in the prior step could lead to configuration errors. A mapping inside the template would need to know the max number of steps for all processes (mapping the prior step number for the current step number.)
Then again, sometimes the resulting destination will not match the name of the process. For the process I am currently trying to deploy, the final location for the data is the website S3 bucket. Can we match the process to that bucket name somehow to grant access to that bucket?
What if my process is “DeployWebsite” and I can pass in the website name I want to deploy? The destination bucket name is going to be the bucket with the name of the website or similar since I can deploy many different websites with the same process.
Or should I create a unique process for each website? If I did that, the process name would need to be my domain name for my website in order for the above logic to work and the website files would be deployed into a folder named /step2. Hmm. That’s kind of odd.
I know I can just pass in the input source and the destination. But I wanted to limit the policy to only accessing buckets in the same environment with the same process and step name but having the policy name limit to resources with the same name or partial name as the process. I could also prevent the steps from running out of order potentially. But even if I have the policy limit to a bucket matching the process name that’s helpful.
One of the good things about using Amazon CloudFront is that the website and bucket name don’t have to match. That solves one problem. I’m sure I will have cases where a bucket name and process don’t match, but I’ll cross that bridge when I come to it. (And perhaps they shouldn’t?) We’ll see. For now my use case is kind of simple.
I’ll need to think about all of the above a bit more but perhaps you can see how I might create a generic policy.
#Pseudocode and I would not use * in the policy - this is just
#showing you how I would create a generic Policy that limits action
#to a resource with a matching name
Parameters:
Name: NameParam
Env: Sandbox
Resources:
Policy:
Effect:
Action: S3:*
Resource: !Sub [arn-format-here]:${NameParam}/*Process or Step SSM Parameter
It would also be easy to create an SSM Parameter for a process or each step in a process using the same strategy we used for secrets. Perhaps we can deploy some sort of useful configuration to the SSM Parameter Store that can help us manage process steps. To decide whether we want to use secrets or parameters we’ll need to understand the difference between the two and the properties of each.
Other inputs and outputs
A process might leverage lots of other source and destination data stores. Perhaps we are sending or receiving event from a Kinesis data stream or an SQS queue. If we go the route of dynamically generating a policy we’d need to probably specify the input and output types and names. It’s possible but then we also need to make sure the configuration can’t be used to allow someone to gain access to something they shouldn’t or to inadvertently misconfiguration the development environment to point to production, for example. We also need to make sure steps are run in the proper order.
A work in progress…
As you can see I haven’t figured all of this out yet but that’s the direction I’m heading at the moment. If you follow along you’ll see if and how these ideas work out. I may actually hard code or do something in less than ideal ways to get through the initial test and then come back around and clean things up more after I see how it all works.
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2023
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab