
Stable Diffusion 3 Is Here — It’s Packed With Huge Improvements

The biggest week in the history of AI isn’t over yet. Just days after OpenAI announced Sora, which can generate jaw-dropping videos, and Google revealed Gemini 1.5, which supports up to 1.5 million tokens of context window, Stability AI today showed an early preview of Stable Diffusion 3.
What is Stable Diffusion 3?
Stable Diffusion 3 is the latest and most capable text-to-image model from Stability AI. It boasts significant improvements in handling multi-subject prompts, image quality, and even text rendering abilities.
The suite of models currently ranges from 800M to 8B parameters. It combines a diffusion transformer architecture (similar to Sora) and flow matching.
Diffusion Transformer Architecture
The Diffusion Transformer (DiT) architecture represents a novel class of diffusion models that incorporate transformer technology. Unlike traditional diffusion models that commonly use convolutional U-Net backbones, DiTs employ transformers to operate on latent patches of images.
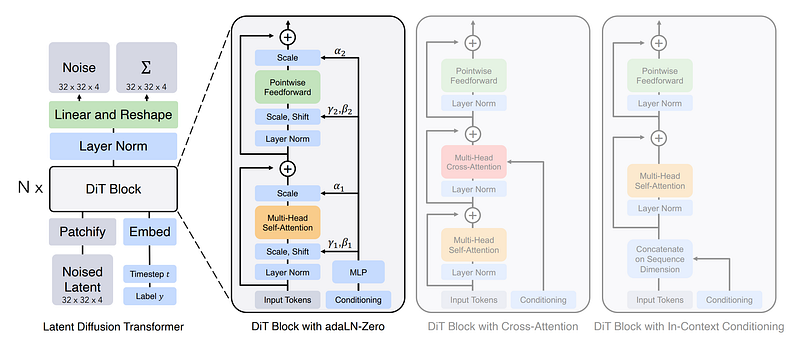
This architecture proves particularly effective for class-conditional image generation tasks on large datasets like ImageNet, where DiTs have set new benchmarks for image quality and generative model performance.
Flow Matching
Flow Matching (FM) is introduced as a new, simulation-free approach for training Continuous Normalizing Flows (CNFs) that enables training CNFs at unprecedented scales. FM works by regressing vector fields of fixed conditional probability paths compatible with a general family of Gaussian probability paths, including diffusion paths.

This not only makes training diffusion models more robust but also paves the way for faster training, sampling, and better generalization with CNFs using non-diffusion probability paths, such as optimal transport (OT) paths.
What’s new in Stable Diffusion 3?
Here are the key improvements SD3 brings:
- Text rendering support
- Improved performance
- Multi-subject prompts
- Better image quality
Perhaps the most exciting feature of this new image model is its capability to render text similar to openAI’s Dall-E 3 and Google’s Imagen 2 in Gemini. Stability AI CEO Emad Mostaque has been sharing images generated with SD 3, and here are some of my favorites:
Prompt: “Photo of a red sphere on top of a blue cube. Behind them is a green triangle, on the right is a dog, on the left is a cat”

One thing I find interesting about this image is the subtle green tint on the white fur of the animals. I wonder if the model learned this effect from behind-the-scenes photos of green-screen film sets.
Prompt: “cinematic photo of a red apple on a table in a classroom, on the blackboard are the words “go big or go home” written in chalk”

Stable Diffusion 3 vs Dall-E 3 vs Gemini
I did a quick comparison of the images generated by SD3 and OpenAI’s Dall-E 3. In the example below, I used the prompts from SD3’s announcement blog post.
Prompt: “Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says “Stable Diffusion 3” made out of colorful energy”

Did Stable Diffusion 3 just beat Dall-E 3? Honestly, I’m surprised that Dall-E 3 repeatedly refused to render text with this prompt. Go try it yourself.
Out of curiosity, I also fed the prompt into Gemini Advance, and here’s the result:

How do I get access to SD 3?
Right now, Stable Diffusion 3.0 is not available to the general public. You can, however, sign up here to get invited to the Discord server.
Final Thoughts
Overall, I’m very excited to see more examples of Stable Diffusion 3. I’ve already signed up to get early access to the preview model.
One thing I am concerned about, though, is that half of the announcement post was talking about AI safety. The obsession with safety in this announcement feels like a missed marketing opportunity, considering the recent Gemini debacle.
Isn’t Stable Diffusion's primary use case the fact that you can install it on your own computer and make what you want to make?
Anyway, open-source models can be fine-tuned by the community if needed. Just to make it clear, the SD3 image model will still be open-source. The preview is to improve its quality & safety, just like the other stable diffusion releases.

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!





