
4 More Little-Known NLP Libraries That Are Hidden Gems
With code examples and explanations

Discovering new Python libraries can oftentimes spark new ideas. Here are 4 hidden-gem libraries that are exceptional to know about.
Let’s get into it.
1) Presidio Analyzer and Anonymizer
Developed by Microsoft, Presidio offers an automatic way to anonymize sensitive text data. First, the locations of private entities are detected within the unstructured text. This is done using a combination of named entity recognition (NER) and rule-based pattern matching with regular expressions. In the following example, we look for names, emails, and phone numbers but there are many other predefined recognizers that you can choose from. The information from the Analyzer is then passed into the Anonymizer which replaces the private entities with de-sensitized text.
Installation
!pip install presidio-anonymizer
!pip install presidio_analyzer
!python -m spacy download en_core_web_lgExample
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig# identify spans of private entities
text_to_anonymize = "Reached out to Bob Warner at 215-555-8678. Sent invoice to [email protected]"
analyzer = AnalyzerEngine()
analyzer_results = analyzer.analyze(text=text_to_anonymize,
entities=["EMAIL_ADDRESS", "PERSON", "PHONE_NUMBER"],
language='en')# pass Analyzer results into the anonymizer
anonymizer = AnonymizerEngine()
anonymized_results = anonymizer.anonymize(
text=text_to_anonymize,
analyzer_results=analyzer_results
)
print(anonymized_results.text)Result
ORIGINAL: Reached out to Bob Warner at 215–555–8678. Sent invoice to [email protected]OUTPUT: Reached out to <PERSON> at <PHONE_NUMBER>. Sent invoice to <EMAIL_ADDRESS>Use Case
Anonymization is a critical step toward safeguarding personal information. It is especially important if you are collecting or sharing sensitive data in the workplace.
2) SymSpell
A go-to Python library for automatic spelling correction: SymSpell. It offers speedy performance and covers a large variety of common mistakes including spelling issues and missing or extra spacing. Although SymSpell will not fix grammatical issues or consider the context of words, you will benefit from its quick execution speed — which is helpful when working with large datasets. SymSpell suggests corrections based on the frequency of words (i.e the is more frequently appearing than therapy), as well as single-character edit distances with regard to keyboard layout.
Installation
!pip install symspellpyExample
from symspellpy import SymSpell, Verbosity
import pkg_resources# load a dictionary (this one consists of 82,765 English words)
sym_spell = SymSpell(max_dictionary_edit_distance=2, prefix_length=7)
dictionary_path = pkg_resources.resource_filename(
"symspellpy", "frequency_dictionary_en_82_765.txt"
)# term_index: column of the term
# count_index: column of the term's frequency
sym_spell.load_dictionary(dictionary_path, term_index=0, count_index=1)def symspell_corrector(input_term): # look up suggestions for multi-word input strings
suggestions = sym_spell.lookup_compound(
phrase=input_term,
max_edit_distance=2,
transfer_casing=True,
ignore_term_with_digits=True,
ignore_non_words=True,
split_by_space=True
)
# display the correction
for suggestion in suggestions:
return f"OUTPUT: {suggestion.term}"text = "the resturant had greatfood."
symspell_corrector(text)Result
ORIGINAL: the resturant had greatfood.OUTPUT: the restaurant had great foodUse Case
Whether you are working with customer reviews or social media posts, your text data is likely to contain spelling errors. SymSpell could be used as another step during NLP preprocessing. For instance, a Bag-of-Words or TF-IDF model will view restaurant and the misspelled word resturant differently even though we know they both have the same meaning. Running spelling correction fixes this issue and may help reduce dimensionality.
3) PySBD (python Sentence Boundary Disambiguation)
Finally! A smart, simple Python library that splits text into sentence units. Although a seemingly straightforward task, human language is complex and noisy. Splitting text into sentences based on punctuation alone only works up to a certain point. What’s great about pySBD is its ability to handle a large variety of edge cases, such as abbreviations, decimal values, and other complex instances oftentimes found within legal, financial, and biomedical corpora. Unlike most other libraries that leverage neural networks for this task, PySBD identifies sentence boundaries using a rule-based approach. In their paper, the authors of this library demonstrate that pySBD scores higher accuracy than the alternatives on benchmark tests.
Installation
!pip install pysbdExample
from pysbd import Segmentersegmenter = Segmenter(language=’en’, clean=True)text = “My name is Mr. Robert H. Jones. Please read up to p. 45. At 3 P.M. we will talk about U.S. history.”print(segmenter.segment(text))Result
ORIGINAL:
My name is Mr. Robert H. Jones. Please read up to p. 45. At 3 P.M. we will talk about U.S. history.OUTPUT:
['My name is Dr. Robert H. Jones.',
'Please read up to p. 45.',
'At 3 P.M. we will talk about U.S. history.']Use Case
There have been many times in which I needed to treat or analyze text on the sentence level. A recent Aspect-Based Sentiment Analysis (ASBA) project is a good example. In this work, it was important to determine the polarity of specific relevant sentences within customer clothing reviews. This could only be done by breaking up the text into individual sentences first. So instead of spending time writing complex regular expressions to cover dozens of edge cases, let pySBD do the heavy lifting for you.
4) TextAttack
TextAttack is a fantastic Python framework for developing adversarial attacks on NLP models.
An adversarial attack in NLP is the process of creating small perturbations (or edits) to text data in order to fool the NLP model into making the wrong prediction. Perturbations include swapping words with synonyms, inserting new words, or deleting random characters from the text. These edits are applied to randomly selected observations from your model’s dataset input.
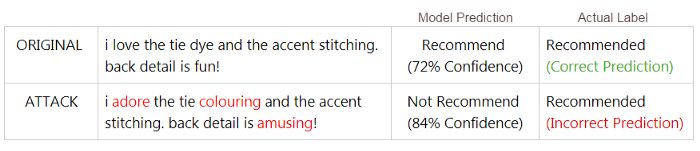
TextAttack provides a seamless, low-code way of generating these adversarial examples to form an attack. Once an attack is run, a summary will be shown of how well the NLP model performed. This will provide an evaluation of the robustness of your model — or in other words, how susceptible it is to certain perturbations. Robustness is an important factor to consider when launching NLP models into the real world.
Installation
!pip install textattack[tensorflow]Example
TextAttack is way too versatile to cover in brief so I heavily recommend checking out its well-written documentation page.
Here, I will be running an attack via command line API (within Google Colab) on a BERT-based sentiment classification model from Hugging Face. This pre-trained model was fine-tuned to predict Positive or Negative using the Rotten Tomatoes Movie Review dataset.
The attack contains a word-swap-embedding transformation, which will transform selected observations from the Rotten Tomatoes dataset by replacing random words with synonyms in the word embedding space.
Let’s see how this NLP model holds up against 20 adversarial examples.
!textattack attack \
--model-from-huggingface RJZauner/distilbert_rotten_tomatoes_sentiment_classifier \
--dataset-from-huggingface rotten_tomatoes \
--transformation word-swap-embedding \
--goal-function untargeted-classification \
--shuffle `True` \
--num-examples 20Result

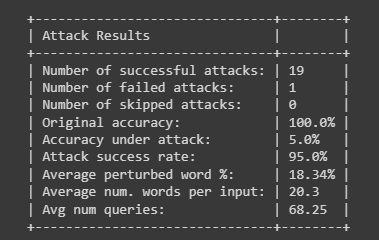
Interesting! Without any perturbations, this model achieves an impressive 100% accuracy. However, out of 20 total attacks — in which only 18% of the words were altered on average — the NLP model was fooled into misclassifying 19 times!
Use Case
By testing an NLP model against adversarial attacks, we can better understand the model’s weaknesses. The next step can then be to improve model accuracy and/or robustness by further training the NLP model on augmented data.
For a full project example of how I put this library to use to evaluate a custom LSTM classification model, check out this article. It also includes a full code script.
Conclusion
I hope that these libraries come to use in your future NLP endeavors!
This was a continuation of a similar article I wrote recently. So if you haven’t heard of useful Python libraries like contractions, distilbert-punctuator, or textstat, then check that out too!
Thanks for reading!