
NLP Project With Augmentation, Attacks, & Aspect-Based Sentiment Analysis
Do you know about these 3 advanced NLP concepts?

Have you heard of these three areas of Natural Language Processing (NLP)?
- Text Augmentation
- Textual Adversarial Attacks
- Aspect-Based Sentiment Analysis
In this article, I will demonstrate the value of these advanced topics and how they can improve your next NLP project. While this will be an explanatory overview, you can find the commented code on my GitHub here.
Dataset
I will be working with the Women’s E-Commerce Clothing Reviews dataset from Kaggle.
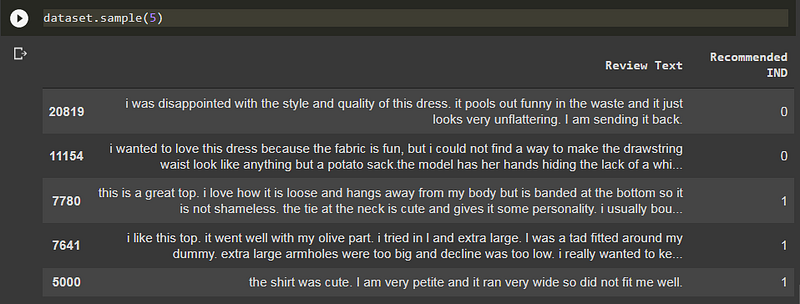
The two variables we need are:
- Review Text: String variable of clothing reviews
- Recommended IND: Binary variable stating whether the customer recommends the product (where 0 is Not Recommended and 1 is Recommended)
Text Augmentation
Using this dataset, our first goal is to implement a supervised deep learning model for binary classification.
However, there is one glaring issue: the dataset is imbalanced. The vast majority of customers provide positive feedback and Recommend the product that they purchased.
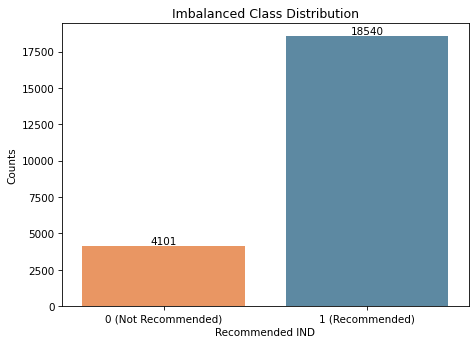
This presents a problem because our model will develop a bias towards the majority class (Recommended products). In other words, the model may struggle to predict Not Recommended reviews due to the lack of negative examples during training.
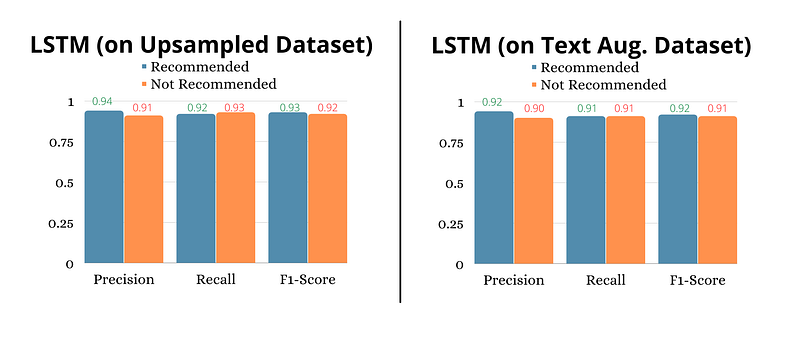
We can see this weakness reflected in the model metrics of an LSTM neural network that I trained on the imbalanced dataset.
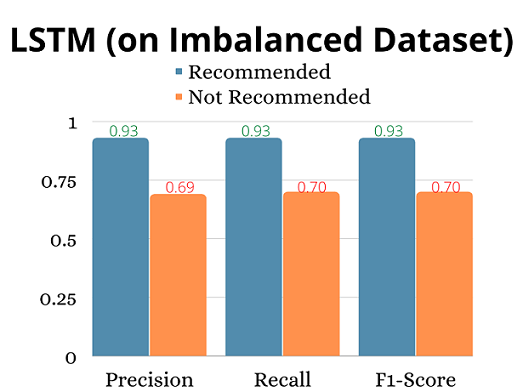
So how can we balance the dataset?
- One common method is to simply upsample the negative reviews. This means we make copies of the current Not Recommended observations and add them to our dataset.
- A more advanced option is text augmentation. Here, words are randomly swapped, deleted, as well as replaced or inserted with synonyms using pretrained word embeddings. I implemented this using Easy Data Augmentation techniques.
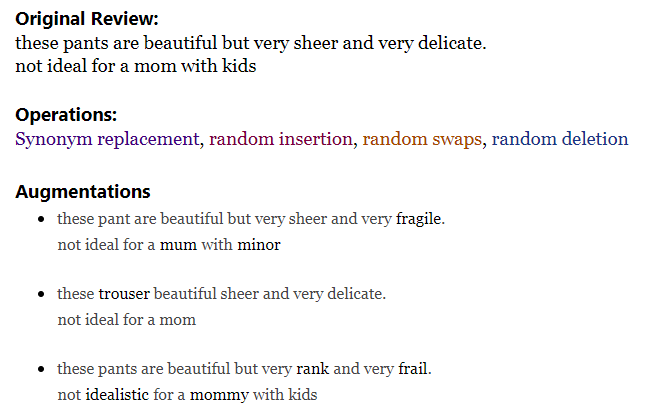
For both upsampling and text augmentation methods, I balanced the dataset to 16,104 Not Recommended reviews (or 4x the original size) and kept the original 18,540 Recommended reviews. I also continued to use an LSTM model for training and testing on each dataset.
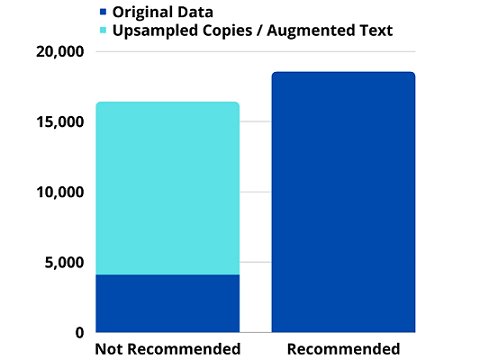
Both upsampling and text augmentation was effective in improving the model’s predictive performance on minority class observations.
So what is the advantage of using text augmentation?
With text augmentation, we also add more variation to our training data, which boosts the robustness of our model and its ability to generalize on unseen text.
Continue reading into the next section to find out how we can evaluate an NLP model’s robustness.
Click here to see the code.
Adversarial Text Attacks
What if I told you that swapping an input’s words or randomly deleting several letters can severely alter the performance of our NLP models?
These types of edits, which can either be accidental or malicious in the real world, are called perturbations and have been shown to significantly decrease the accuracy of even the best state-of-the-art models, such as BERT. Link to article.
We formulate attacks against a trained model by testing it against inputs that are semantically similar to the original but have slight paraphrasing or synonym substitutions.

Using the TextAttack library, I will run an adversarial attack on each of the trained LSTM models (the one trained with upsampled data and the one with augmented data). The attack will run until 1000 attacks are successful at fooling each model.
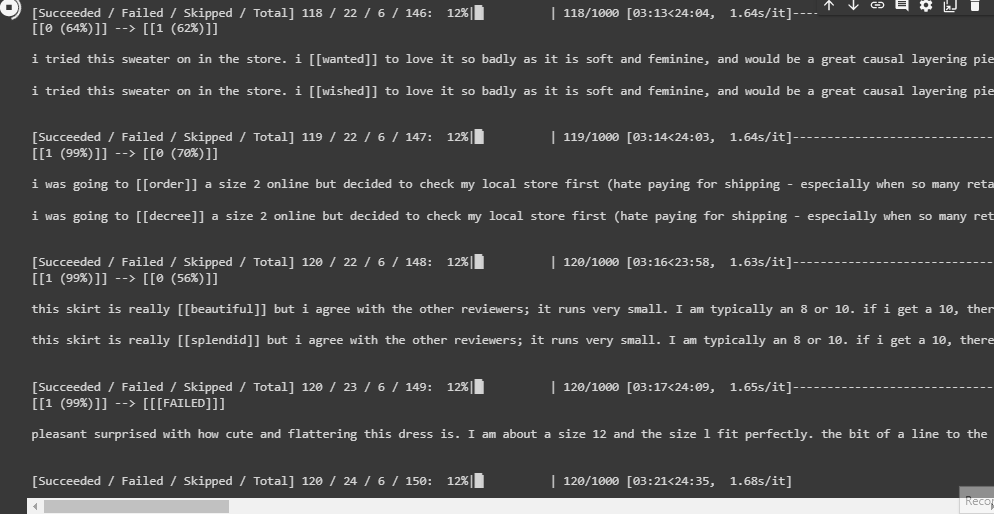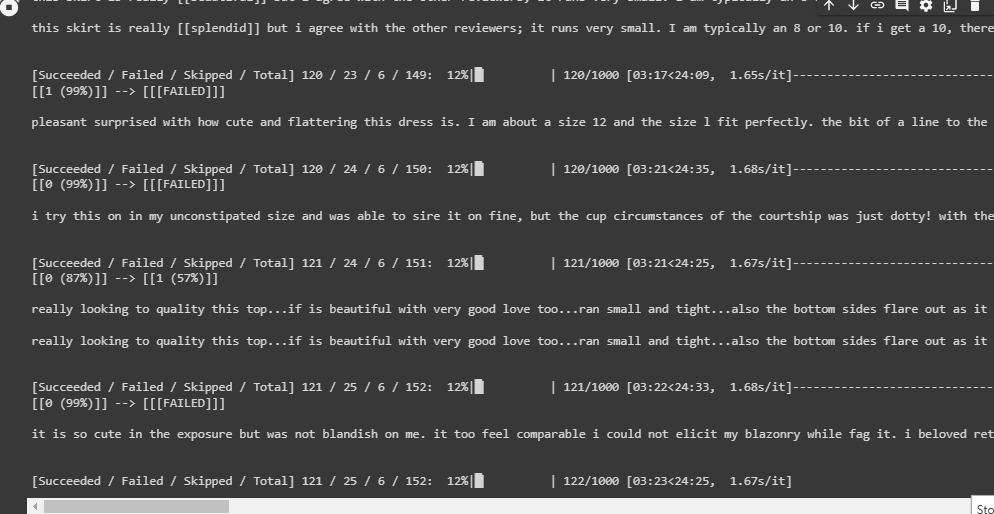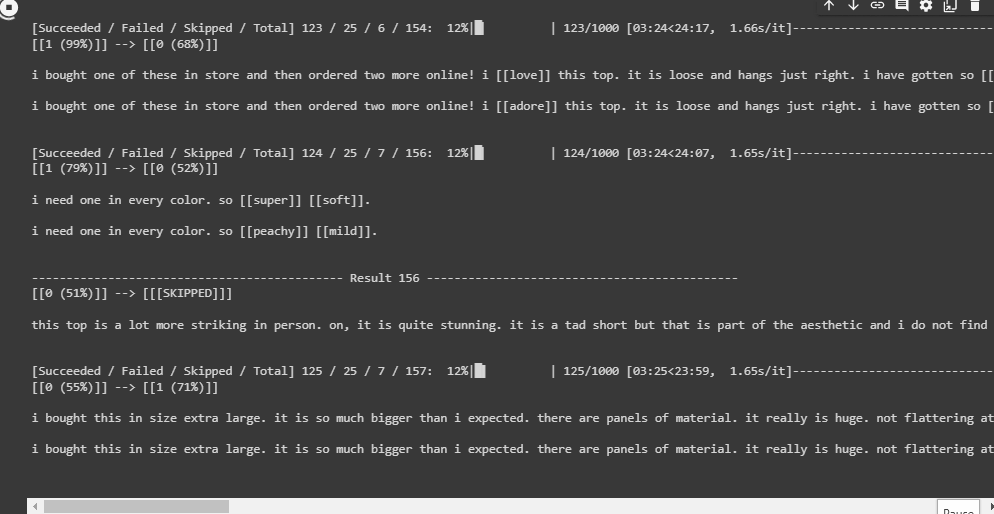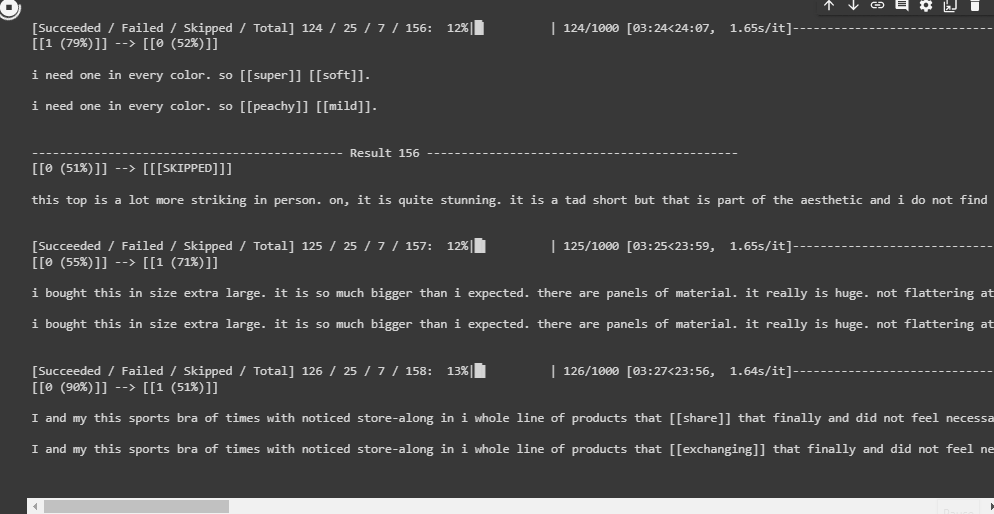
Here are the attack results. The LSTM trained on a dataset with augmented data outperformed all-around. In comparison, it had significantly better accuracy against perturbations and yielded nearly double the amount of failed attacks.
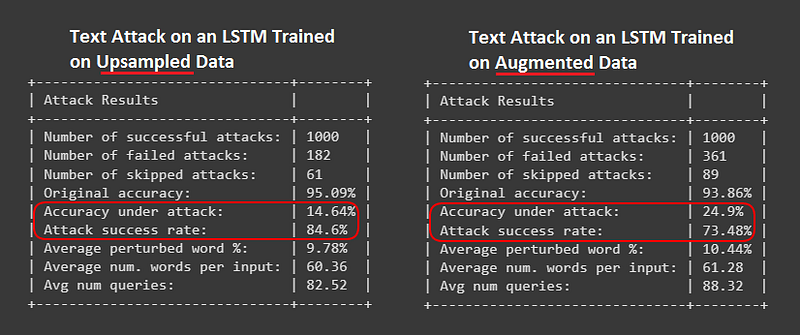
These results are promising and are consistent with existing studies that have exhibited text augmentation techniques to be effective in improving model performance on small and imbalanced datasets.
Click here to see the code.
Aspect-based Sentiment Analysis (ASBA)
Let’s say you are working as a data scientist for the company that makes these women’s clothing. Your boss asks you to dive deeper into the negative reviews and analyze consumer sentiment specifically related to the color of dresses.
How would you go about doing this using unstructured text?
Many of us are already aware of sentiment classification. But take a look at the following review:

By simply classifying the overall review as Positive or Negative, we miss out on several smaller nuggets of information. With ASBA, we can be more granular in our analysis and extract the positivity associated with color.
I like to think of ASBA as a 4-step process:
- Identify observations from the dataset that are relevant to our aspect. Color is our aspect here. We can keep things simple and use a subset of reviews that mention the word “color” or “colors” in the review using regular expressions. However, this won’t always be the case. Sometimes with more abstract aspects, such as Experience, Service, or Location, you may need to leverage topic modeling to predict which aspect is most relevant to a text.
- Secondly, we need to segment our text into smaller pieces. In my code, I leveraged a 3rd party API to perform this step. But it can also be as straightforward as applying some common knowledge of linguistics. For instance, we can split the text by sentences on punctuation, as well as segment phrases when there is a conjunction word (“but”, “however”, “although”, etc).

3. Now, let’s determine the sentiment or polarity relating to the aspect. The easiest approach here is to apply a pretrained sentiment classifier model. For this example, I used the TextBlob library to determine polarity, which ranges between negativity and positivity on a scale of [-1, +1].

4. Lastly, we can extract the descriptors associated with our aspect. So far, we have discovered that this customer thought positively of the dress’s color, but it can also be helpful to know why. In this case, it was because it was “beautiful.” We can use spaCy’s token classification features to automatically analyze the linguistic structure of the sentence and extract what adjectives/adverbs are associated with our noun.
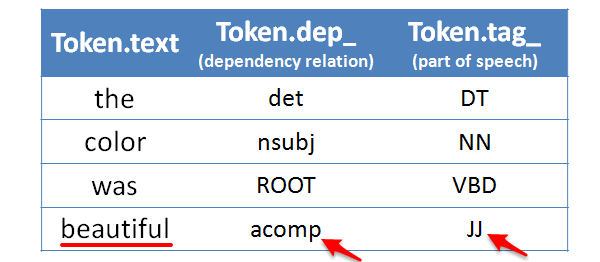
Let’s see these steps in action on some more opinions:
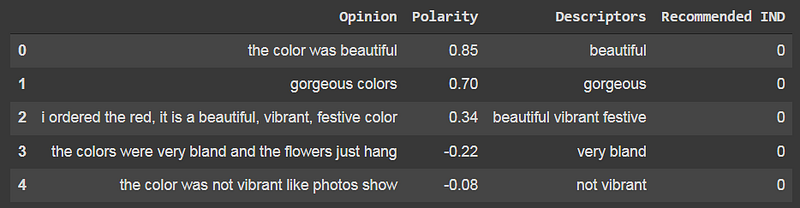
After analyzing the sentiment of our aspect — color — on 270 Not Recommended dress reviews, we find the following results.
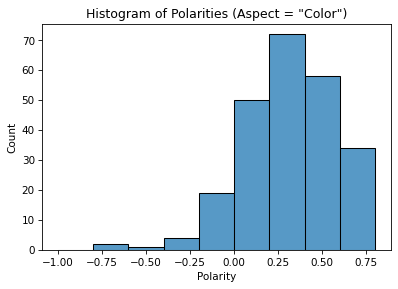
We can report that customers typically respond positively to dress colors. Therefore, color is not a primary contributor to Not Recommended reviews.
From analyzing the descriptors, we find that customers love products with bright, vivid, and vibrant colors. However, reviewers tend to complain about a product’s color when it appears darker in person than on online pictures or is too muted or dull.

We can recommend that the company focuses on using bright, vibrant colorways and materials.
For further research, you could analyze other aspects such as pattern, fabric, and size.
Click here to see the code.
Conclusion
Whether it is to improve your dataset, build a more robust model, or analyze specific aspects, these are definitely concepts to be aware of. I hope this article got you thinking about various possibilities for your next projects.
And if you are still wanting more NLP content, check out my recent article introducing several unique — but very helpful — NLP libraries.
Thanks for reading!